在自动驾驶感知系统中,语义分割是保障行车安全的核心技术——它需要精准识别道路、行人、交通标志等每一个像素级元素。但传统全监督语义分割依赖海量像素级标注,一张Cityscapes数据集的图像标注就要1.5小时,成本高到难以承受。弱监督语义分割(WSSS)虽能降低标注成本,却始终难以应对自动驾驶场景中尺度剧变、空间关系复杂、边界精度要求严苛的难题。
近期,一篇聚焦自动驾驶场景弱监督语义分割的论文《DyFuse: Dynamic fusion for weakly-supervised semantic segmentation in autonomous driving scenes》给出了颠覆性解决方案!该研究提出的DyFuse框架,融合CLIP的语义理解能力与SAM的视觉表征优势,在Cityscapes、CamVid、WildDash2三大自动驾驶数据集上实现mIoU大幅提升,甚至在CamVid验证集上超越全监督方法,今天就带大家深度拆解这项创新成果。
unsetunset论文信息unsetunset
题目:DyFuse: Dynamic fusion for weakly-supervised semantic segmentation in autonomous driving scenes
面向自动驾驶场景的弱监督语义分割动态融合方法
作者:Yongqiang Li, Chuanping Hu, Kai Ren, Hao Xi, Jinhao Fan
unsetunset一、自动驾驶分割的核心痛点:难在“动态”与“尺度”unsetunset
传统WSSS方法主要依赖类激活图(CAM)生成分割掩码,存在三大致命缺陷:
而自动驾驶场景的特殊性让这些问题雪上加霜:城市场景中既有建筑物这类大型结构,也有交通标志、行人等小目标,尺度差异悬殊;不同天气、光照条件下,特征可靠性波动大;类别不平衡、边界模糊进一步加剧了分割难度。
现有方法即便结合CLIP和SAM,也只是简单串联,未能充分发挥两者“语义理解+边界精准”的互补优势——这正是DyFuse框架要攻克的核心问题。
unsetunset二、DyFuse核心创新:四大维度破解场景难题unsetunset
1. 全新动态融合框架:端到端整合CLIP与SAM
DyFuse最核心的突破,是摒弃了传统“固定拼接”的融合思路,以端到端的方式将CLIP的语义理解能力与SAM的鲁棒视觉表征无缝融合。整个框架针对自动驾驶场景定制,精准应对尺度变化、空间关系复杂、边界精度要求高三大挑战,这也是其性能超越现有方法的基础。
2. 多尺度上下文感知增强(MCPE)模块:大小目标通吃
针对自动驾驶场景的尺度剧变难题,MCPE模块设计了1.0、0.75、0.5三个特定尺度的并行处理分支,能同时捕获多分辨率特征。无论是建筑物这类大型结构,还是交通标志、行人等关键小目标,都能被精准分割。
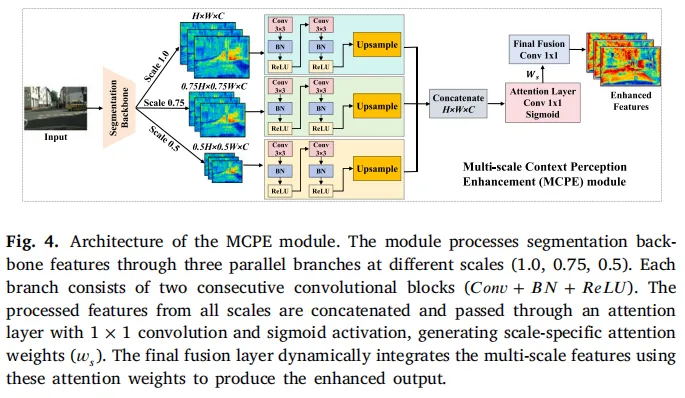 图4:MCPE模块架构图,通过多尺度并行分支+注意力融合,实现多分辨率特征的有效捕获
图4:MCPE模块架构图,通过多尺度并行分支+注意力融合,实现多分辨率特征的有效捕获
MCPE模块先通过双线性插值生成多尺度特征图,再经两阶段卷积细化,最后通过注意力机制自适应整合不同尺度特征——既保留了小目标的细节,又兼顾了大结构的全局上下文。
3. 动态特征融合机制:按“可靠性”智能加权
这是DyFuse的点睛之笔!传统融合方法用固定权重整合特征,无法适配不同区域的特征可靠性差异。而动态融合机制会学习“空间变化的权重”:在需要精确边界的区域(如道路边缘、行人轮廓)侧重SAM特征,在需要强语义理解的区域(如复杂场景的类别判断)侧重MCPE特征。
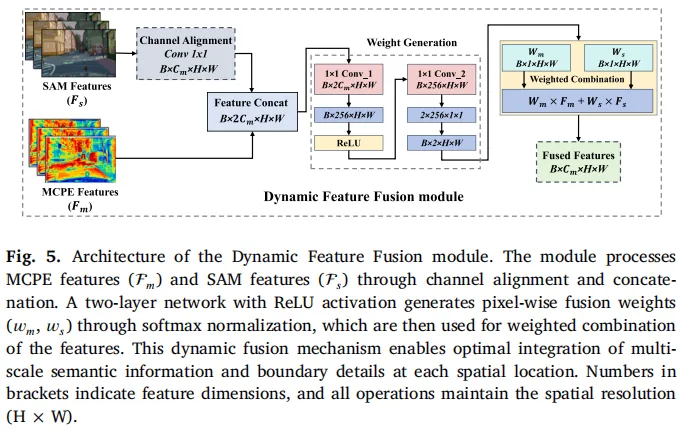 图5:动态特征融合模块架构,通过可靠性估计生成自适应权重,实现MCPE与SAM特征的智能融合
图5:动态特征融合模块架构,通过可靠性估计生成自适应权重,实现MCPE与SAM特征的智能融合
该模块先对齐MCPE和SAM特征的通道维度,再通过轻量级网络生成融合权重,最后按权重加权整合特征。这种“因地制宜”的融合方式,让模型在不同场景、不同区域都能发挥最优性能。
4. 智能伪标签生成策略:高质量监督信号的关键
弱监督学习的核心是伪标签质量,DyFuse将“密集网格提示的SAM掩码生成”与“CLIP的语义分类”结合,打造了一套智能伪标签生成流程:
- 分层点采样:结合均匀网格采样+边缘焦点采样,确保场景全面覆盖;
- 高置信度掩码过滤:仅保留SAM生成的置信度>0.8的掩码,保证基础质量;
- CLIP语义分类:用CLIP的视觉-语言对齐能力,为掩码分配精准的语义类别;
- 动态损失加权:训练中逐步调整SAM监督的权重,兼顾收敛稳定性与性能。
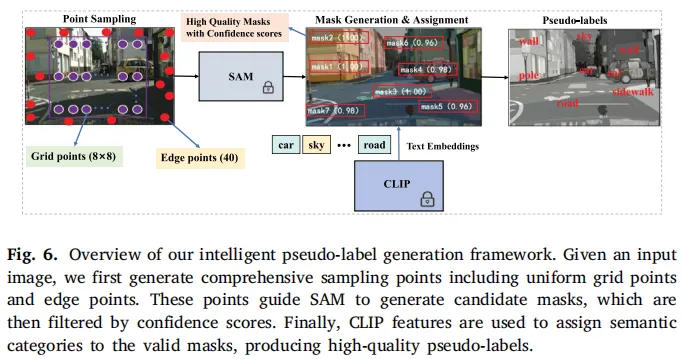 图6:智能伪标签生成流程,结合SAM的边界精度与CLIP的语义理解,生成高质量监督信号
图6:智能伪标签生成流程,结合SAM的边界精度与CLIP的语义理解,生成高质量监督信号
unsetunset三、DyFuse整体架构:三大组件协同工作unsetunset
整个DyFuse框架以端到端的方式整合上述核心组件,形成完整的弱监督语义分割链路,其总体结构如下:
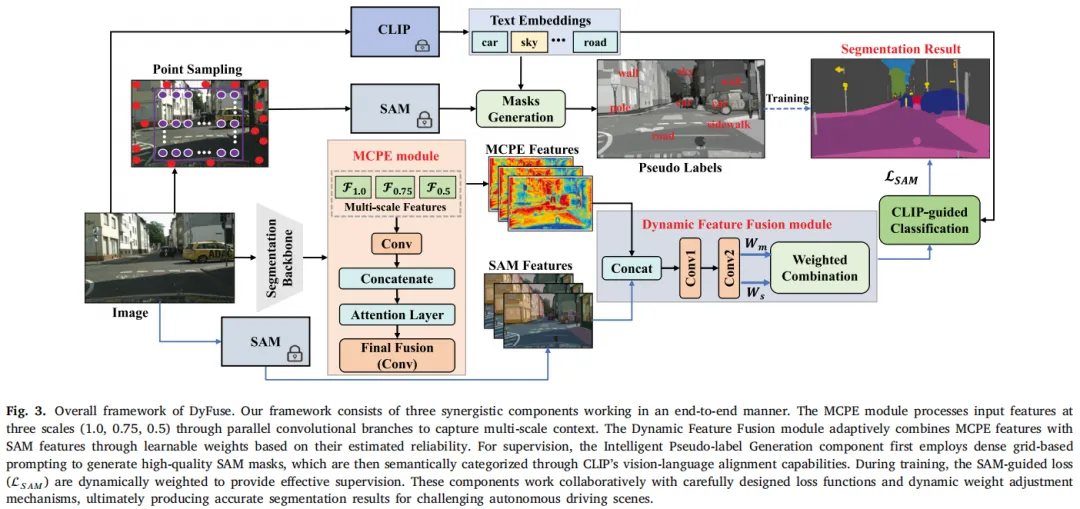 图3:DyFuse框架总体结构图,MCPE、动态融合、智能伪标签三大组件协同,实现端到端的弱监督语义分割
图3:DyFuse框架总体结构图,MCPE、动态融合、智能伪标签三大组件协同,实现端到端的弱监督语义分割
MCPE模块先提取多尺度上下文特征,再与SAM特征通过动态融合机制整合,最后结合CLIP的语义分类完成分割预测;同时,智能伪标签生成策略为训练提供高质量监督信号,配合定制化损失函数(基础分割损失+SAM引导损失),确保模型稳定收敛。
unsetunset四、实验结果:性能全面碾压,鲁棒性拉满unsetunset
1. 定量结果:mIoU大幅提升
在三大自动驾驶数据集上,DyFuse对比当前最优方法CARB实现了显著提升:
- Cityscapes:验证集mIoU达75.4%(+23.3%),测试集73.7%(+21.9%),与全监督方法差距缩小到3%以内;
- CamVid:验证集mIoU达82.2%(+26.5%),甚至超越全监督的DeepLab-ASPP;
- WildDash2:mIoU达50.5%(+18.3%),恶劣天气下仍保持强鲁棒性。
2. 定性结果:细节拉满,抗挑战能力突出
在复杂城市场景中,DyFuse展现出碾压级的细节处理能力:
 图8:DyFuse与CARB在Cityscapes复杂场景的分割结果对比,DyFuse能精准分割小目标、复杂边界
图8:DyFuse与CARB在Cityscapes复杂场景的分割结果对比,DyFuse能精准分割小目标、复杂边界
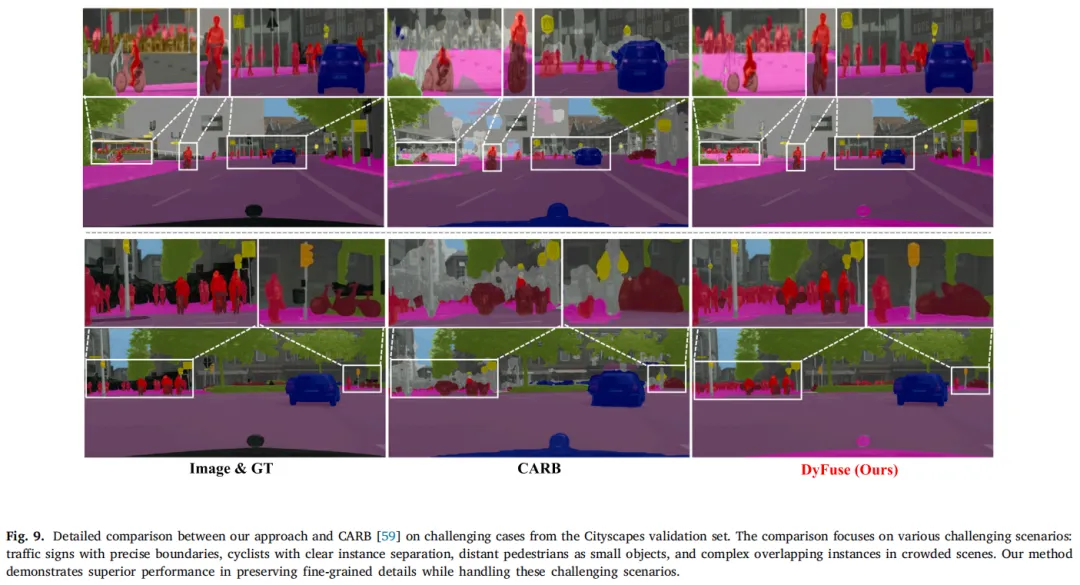 图9:细节对比图,DyFuse对交通标志、行人等小目标的边界分割更精准,复杂空间关系处理更优
图9:细节对比图,DyFuse对交通标志、行人等小目标的边界分割更精准,复杂空间关系处理更优
无论是远处的行人、细小的交通标志,还是重叠对象的边界,DyFuse都能精准分割;在雨、雪、雾等恶劣天气,以及夜间、强眩光等极端光照条件下,性能依然稳定——这对自动驾驶的实际部署至关重要。
unsetunset五、总结:弱监督分割的“自动驾驶专属”解法unsetunset
DyFuse的核心价值,在于真正针对自动驾驶场景的特殊性做了“定制化创新”:
这项研究不仅大幅提升了弱监督语义分割的精度,更证明了“融合基础模型优势+场景定制化设计”是自动驾驶感知技术的重要发展方向。未来,随着该框架的进一步优化,弱监督语义分割有望在降低标注成本的同时,真正达到全监督方法的性能,为自动驾驶的大规模落地扫清关键障碍。



