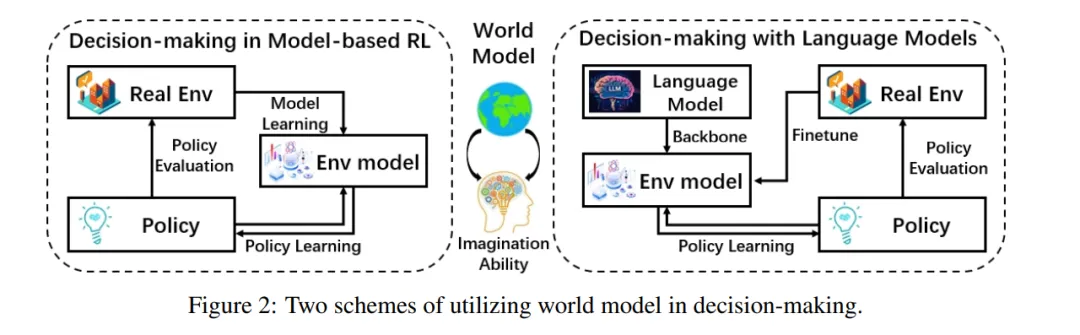
通俗易懂 | VLA 与世界模型,自动驾驶的左路与右路
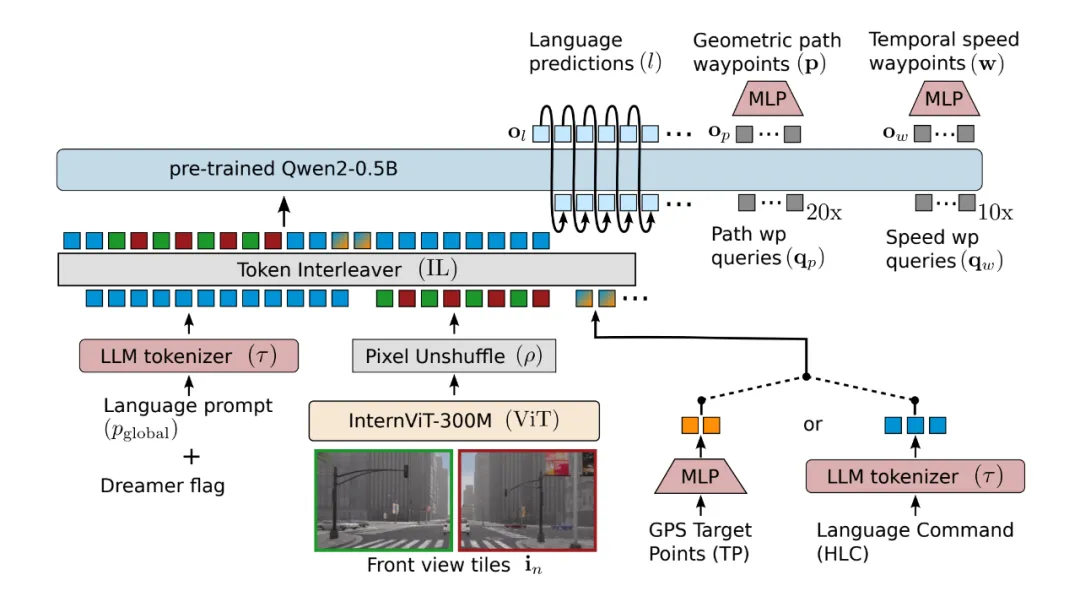
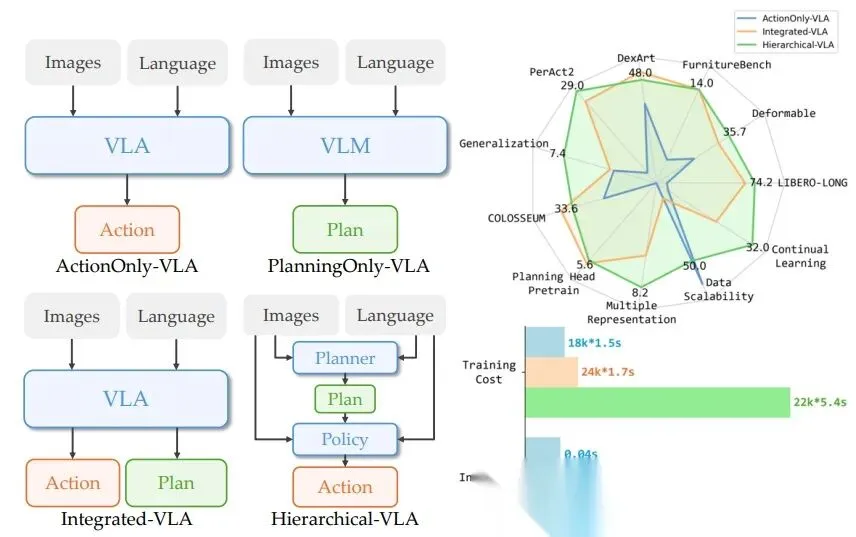
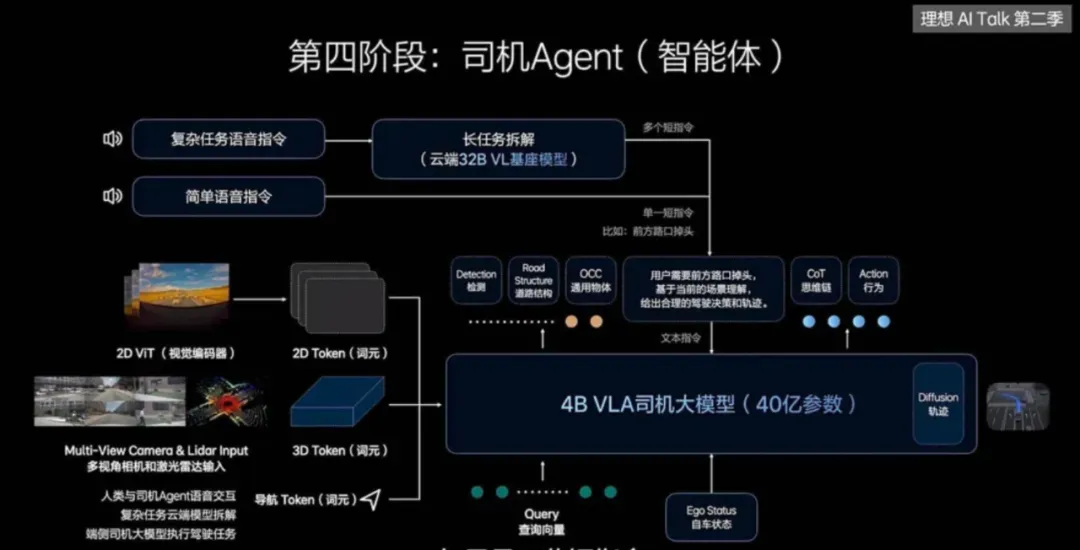
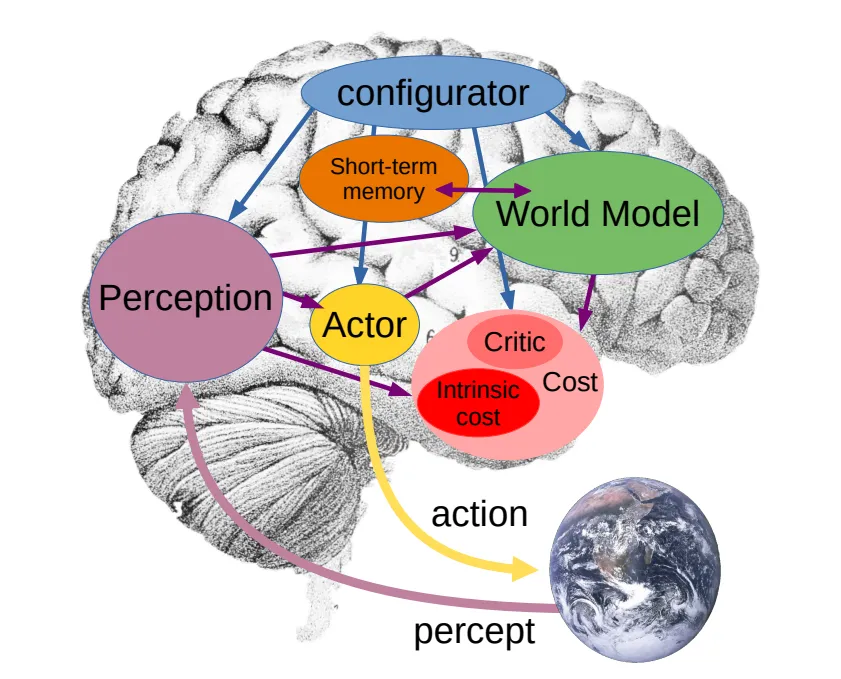
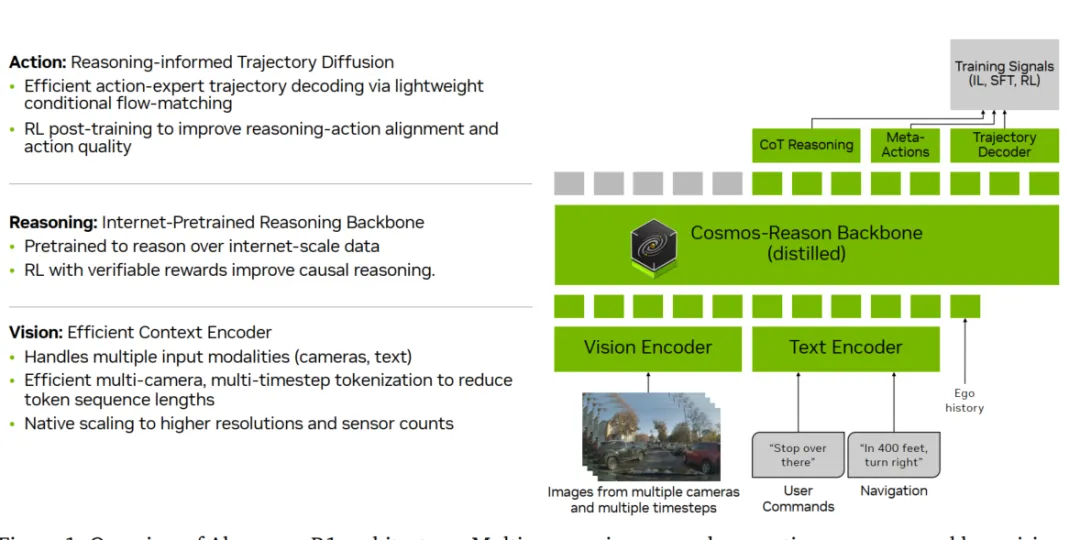
最近有个好友问了一个问题,能不能用通俗易懂的话说明一下VLA和世界模型的区别,一时间没有找到几句合适的话。VLA的架构是让AI记住和学习人类的开车经验,而世界模型是让AI自己去推演物理世界,让AI真正理解驾驶任务背后的关联。再通俗一点,如果将驾驶任务比作大学四六级考试,VLA像是每天翻开abandon的单词书背单词靠积累和匹配完成通过考试,而世界模型更像是学习语法,掌握底层逻辑后能应对更多未知情况。为什么最近几年端到端、VLA或者世界模型火起来,得益于近年来的深度学习与算力的突飞猛进。自动驾驶的发展路径不甘示弱也出现分派。一派以理想汽车、小鹏汽车为代表,沿着VLA的实用主义道路坚定前行,其中小鹏汽车发布第二代VLA架构,干掉L直接变VA;另一派则以华为、蔚来为旗手,押注于构建世界模型的理想主义方案,不过华为发布的是世界模型模式,实际引望发表的论文中还是以语言模型为重点,也就是注重产品的落地和改善。这场看似单纯的技术路线之争,其实也蕴含着对智能本质不同的理解、对机器认知世界的路径选择,以及对未来人机关系的一些不同想象。当然,如果只是跟风追热点的企业就暂且不论,看宣传啥路径都布局,定睛一看只是自嗨的表演。从技术架构的层面来看,VLA路径与世界模型路径有着不同的设计逻辑与实现框架。VLA模型的核心,在于构建一个从视觉感知到驾驶动作的端到端映射系统,整个端到端系统最关键的创新是引入了自然语言作为中间的抽象层与推理引擎。这一设计灵感直接源于对人类认知流程的模仿,观察-思考判断-行动。首先通过强3D空间编码器(如基于BEV的感知模型),将传感器捕获的多模态数据,统一转化为几何与语义信息的空间token序列。这相当于为车辆构建了一个实时的、可理解的数字环境基底;其次将这些空间token与可能的文本指令(如导航目标)一同输入至一个经过特殊驾驶数据训练或微调的大规模语言模型。LLM在此扮演认知中枢的角色,它并非生成人类可读的句子,而是利用其强大的序列建模、逻辑推理和思维链能力,对交通场景进行深度分析,评估风险,规划轨迹,并输出一系列用于描述决策逻辑的中间表征或思维过程;最后基于LLM的输出,一个扩散策略模型或其它动作生成模型,负责将高层的推理结果解码为具体的、平滑的、安全的车辆控制信号,如方向盘转角、油门和刹车。那么,需要说明的是VLA路径它能够直接复用当前人工智能领域炙手可热的大语言模型,凭借LLM的涌现能力,可以快速赋予自动驾驶系统长时序推理、常识理解和复杂情境应对的潜力。例如,系统可以像人类一样,基于前方车辆刹车灯亮起且略有左右摇摆,可能司机在分心这样的隐含逻辑进行预判。同时,由于决策过程可被语言模型以近似自然语言的方式叙述出来,也可以增强系统的可解释性与可调试性,为安全认证和问题追溯提供了一定的便利。而世界模型的套路是让机器直接学习并掌握物理世界运行的基本规律,在内部构建一个可与真实世界对齐的模拟器。不需要自然语言作为诠释者,而是系统自行推理,类似生死有命富贵在天。仍然是以华为提出的WEWA架构为例,该架构分为两部分,云端的世界引擎和车端的世界行为模型。云端的世界引擎是一个超大规模的物理仿真环境,它不仅能生成常规驾驶数据,更致力于构建海量的、极端罕见的长尾场景,模拟各种物体间复杂的相互作用与因果链。这些数据用于训练车端的世界模型,使车端不仅学会在数据中统计关联性,更能内化物理规则,具备因果推理与反事实推理的能力。例如,它需要理解因为轮胎打滑,所以车辆失控的因果关系,并能推演如果当时提前减速,结果会如何。正如刘若英的歌中所唱,后来我总算学会了如何去爱,可惜你早已远去消失在人海。世界模型可以一定上解决后来的消失不见而前置结果勇敢一点。因此,基于世界模型的自动驾驶系统,其决策不依赖于对历史驾驶行为的模式匹配,也不依赖于通过语言进行的二次转译,而是基于对当前状态的编码,在内部模拟器中推演未来多帧的状态变化,直接评估不同动作序列的后果,从而选择最优解。这好比一位天赋型物理学家,无需用语言描述小球滚下斜坡的过程,就能直接计算出其轨迹。虽然不知道题目如何分解步骤,但是就是能给出正确答案,你说气不气人。VLA和世界模型技术路径的差别,并不是技术迭代差异,不会呈现先后顺序或者从VLA可以迭代到世界模型,其根源深植于对智能本质的不同哲学理解。所以,那些划分第一阶段是VLA,第二阶段是世界模型的宣传绝大多数都活在自我的幻想之中。举个简单的例子,人类是黑猩猩进化而来,但是饲养一只黑猩猩最终绝对不会变成人。VLA和世界模型不是小孩到大人的成长关系,而是从用地图导航到自己绘制地图这两种本质不同的能力。VLA本身很难通过迭代长成世界模型。VLA的核心目标是学会行为映射。例如在驾校学员照猫画虎学开车,把教练教的看到后视镜到库角就打死方向的套路记熟,考试侧方位停车没问题,遇到斜列车位就容易慌。VLA是从海量的人类数据中学习,通过感知建立某个场景到语言思维链最后采取某个动作之间复杂的统计关联。它追求的是在给定场景下,输出最像人、最合理的动作。而世界模型的核心目标是学会内在的物理规律,目标是构建一个内部的模拟器,能够理解场景中各种元素,包括车、人、路、物理法则如何相互作用,并能推演如果我这样做,未来几秒世界会变成什么样。它追求的是掌握世界运行的底层因果机制。就像开了十几年的老司机,懂路况、懂车的物理特性,不用死记规则,凭直觉就能预判踩油门、刹车会有什么结果。再进一步思考,无论是杨立昆还是辛顿甚至是何恺明,这些AI大神和而不同的关键就是对于AI的理解其实都是各自哲学的数字化体现。VLA模型的哲学基础,更接近于一种功能主义与实用主义的结合。它并不执着于追问机器是否真正理解世界,而是关注其是否能以高度的可靠性完成驾驶任务,只管结果不问东西。例如,遇到路口红灯,VLA系统不用理解红灯为什么要停车,只要记住感知输入红灯就等于踩刹车停车的场景到动作关联,能稳定完成停车动作就够了。这就是功能主义的核心,结果优先,不问本质。在这种视角下,智能的一个重要体现是有效的信息抽象与沟通能力。无论是人类还是机器对自然语言处理的能力提升,本身就是对混沌世界的一种强大抽象工具。自然语言将连续的感官体验、复杂的逻辑关系,压缩为离散的符号序列。VLA模型借用语言作为中间层,实质上是借用了人类生物进化而来的一套已经验证有效的世界压缩与推理算法,因为人类的语言表达其实就是已经经过压缩,这也是和机器处理最大的不同之处。要实现高级智能,或许不必从零开始重构世界的物理法则,而是可以站在人类认知的肩膀上,通过学习和模仿人类用来描述和理解世界的方式,来间接地掌握在世界中行动的能力。这种路径认为理解或解释可以等价于能够用一套有效的符号系统进行描述和推理。世界模型路径更多是理性主义与本质主义色彩。机器对客观物理世界的真知,而不仅仅是行为上的拟似。再回到路口红灯的问题,世界模型不仅会停车,还能理解红灯停车是为了避免和横向车辆碰撞。更能推演,如果闯红灯,会和横向来车产生怎样的物理碰撞。这就是本质主义的核心,先理解世界的底层逻辑,再做出动作。这一派观点认为,真正的自主智能体,必须拥有一个独立于外部观察的内在模型,这个模型能够表征世界的基本实体、属性及其相互作用规律。这种思想深受认知科学中心智的物理符号系统假说及生成模型理论的影响。智能体通过主动构建并不断修正内部模型,来预测感官输入,减少认知不确定性。驾驶任务中的体现出来的智能,在根本上被认为是物理直觉的体现,也就是一种对质量、速度、惯性、摩擦力、因果关系等基本物理量的内隐掌握。因此,这一派吐槽VLA的方式是绕过物理本质,是一种短期的作弊行为,仅仅通过语言关联来学习驾驶,是一种捷径或表象模仿而非内在的智能涌现,遇到训练数据未曾覆盖的、需要根本性物理推理的极端场景时,系统可能暴露出脆弱性。世界模型的理想是让机器获得接近人类孩童通过交互摸索世界而习得的朴素物理学。前面提到VLA和世界模型并不是递进的技术关系,而是对物理世界不同的解。虽然当下呈现出路线之争的左右互搏态势,但更深层次地看,VLA与世界模型并非对立,而是代表了构建机器智能的两个互补维度。一个是基于语言符号的抽象推理能力,另一个是基于模型的物理直觉能力。通过大厂的一些研究和大神的言论,VLA和世界模型很可能走向一种辩证的统一。一种融合范式是世界模型为体,语言模型为用。例如英伟达最近发布的开源物理AI推理模型Alpamayo。以世界模型COSMOS作为核心的认知与预测引擎,确保系统对物理规律的基础性把握和长程预测的准确性。同时,引入语言模型作为高级规划器、异常解释器与人机接口。语言模型可以基于世界模型提供的状态预测,进行更复杂的逻辑规划、价值判断,并在需要时,用人类可理解的方式解释系统为何做出某项决策;另一种是工具层面的相互借鉴。VLA路径为了提升物理真实性,可能会在其感知编码或动作生成模块中,嵌入小规模的、专门化的物理动力学模型。而世界模型路径为了提升推理效率和可解释性,也可能在其高层规划模块引入符号化或语言化的抽象工具。二者在技术上取长补短,让自动驾驶系统既拥有VLA的高效性和可解释性,又拥有世界模型的物理直觉和未知场景应对能力。说到底,无论是VLA 的实用主义探索,还是世界模型的理想主义追求,亦或是未来二者的融合,最终的目标都是一致的,那就是让机器能与物理世界进行安全、流畅的互动。这场技术路线的探索,不仅是自动驾驶产品和技术的创新,更是人类对机器如何认知世界、什么是机器智能的不断深度思考。而对于自动驾驶行业来说,其实无需纠结于哪条路是对错或者更优,两条路径的并行探索和相互融合,才是推动自动驾驶技术走向成熟的核心动力。 对于企业来说,得依据自身资源而定,不管哪条路径都会出现产品应用,关键是投入的资源。
对于企业来说,得依据自身资源而定,不管哪条路径都会出现产品应用,关键是投入的资源。
感谢,每一次阅读都是作者前进的动力,每一次点赞都是加油站!