MindDriver:用于自动驾驶的渐进式多模态推理(CVPR 2026)
- 2026-03-07 08:38:23

点击下方卡片关注我们,点亮星标⭐,优质好文第一时间送达^_^
Click on the card below to follow US

>>>戳我一下,加入智驾机器人学习交流群✨
本次给大家解析的文章是来自阿里巴巴,高德,香港科技大学等机构联合发表的论文:
MindDriver: Introducing Progressive Multimodal Reasoning for Autonomous Driving
论文作者为Lingjun Zhang, Yujian Yuan, Changjie Wu, Xinyuan Chang, Xin Cai, Shuang Zeng, Linzhe Shi, Sijin Wang, Hang Zhang, Mu Xu。仓库地址为:
https://github.com/hotdogcheesewhite/MindDriver
原文链接为
https://arxiv.org/pdf/2602.21952
01
1. 背景:为什么自动驾驶需要“推理链(CoT)”,但现有 CoT 不够好?

端到端自动驾驶希望把多摄像头等原始传感器输入直接映射到未来轨迹,减少手工中间模块带来的信息损失,并利用大模型的“世界知识”提升长尾泛化能力。论文指出,视觉-语言模型(VLM)在推理方面表现突出,因此被寄予厚望。

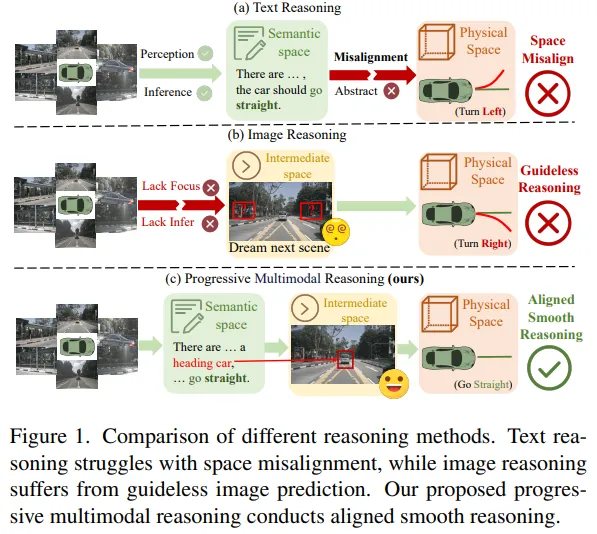
很多方法让模型先做一段文本推理(CoT),再输出轨迹。但轨迹是连续的物理量(位置、速度),而文本推理处在抽象语义空间,导致“推理内容”和“最终动作”容易对不上:论文称之为space misalignment。

为缓解文本与轨迹的空间鸿沟,有工作尝试用“未来图像”替代文本作为中间推理载体。但论文强调:如果只是让模型预测未来图像,没有明确的规划导向,模型会不知道该关注哪些关键交通参与者,图像预测会变得“guideless”。论文在图 1 对比了三类方式,并提出自己的“渐进式多模态推理”能让推理更平滑、对齐。
02
2. 核心思想:像人类一样“感知—想象—行动”的渐进推理
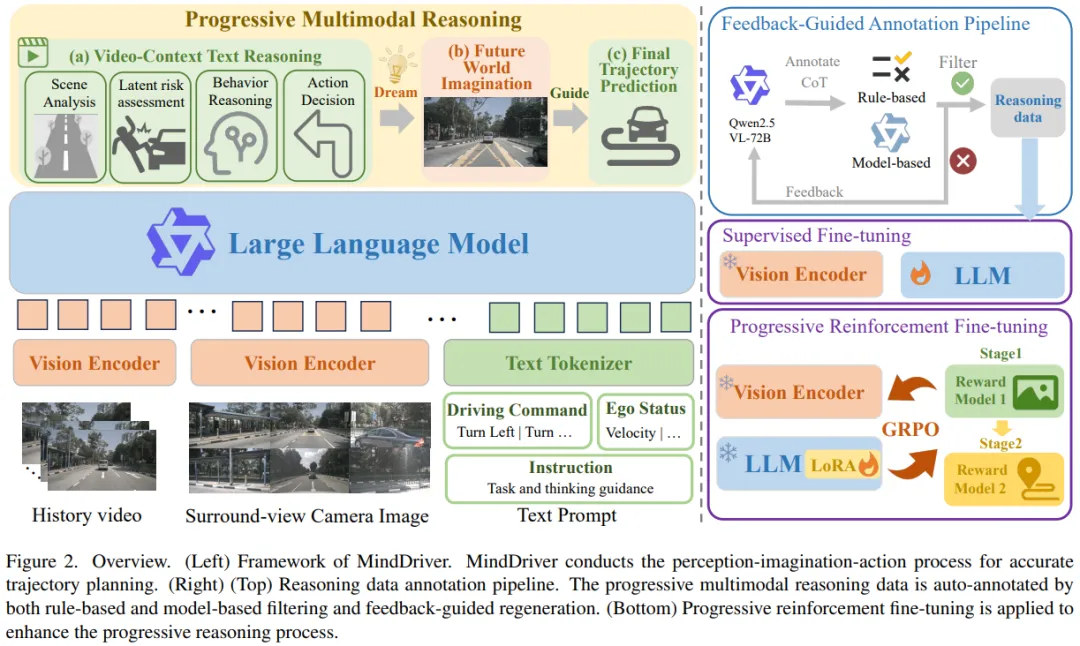
论文受到人类驾驶决策机制启发,提出 Progressive Multimodal Reasoning,让模型推理链从:
语义理解(Semantic understanding):用文本推理分析场景、风险、决策逻辑 语义到物理的想象(Visual imagination):在文本推理指导下生成未来场景图像,桥接语义与物理空间 物理轨迹规划(Physical-space trajectory planning):基于“梦到的未来场景图像”输出未来轨迹
这一三阶段结构在论文的图 2中以“Video-Context Text Reasoning → Future World Imagination → Final Trajectory Prediction”呈现。
03
3. MindDriver 框架总览
MindDriver 不只是一个模型结构,还包含两套关键训练机制:
反馈引导的自动标注流水线:生成对齐的渐进式多模态推理数据 渐进式强化微调(Progressive RFT):分阶段奖励中间过程,让“文本→图像→轨迹”的过渡更对齐、更稳定
总览图(图 2)右侧同时展示了标注流水线与两阶段 RFT(Stage1/Stage2)。
04
4. 输入与推理流程:模型到底吃什么、吐什么?

论文描述 MindDriver 的输入由多部分构成::
6 路环视摄像头当前帧(surround-view RGB) 前视历史视频:4 帧历史 front-view,用于捕捉动态(但不引入太大算力开销) 高层驾驶指令(如 Turn Left/Right/Go Straight) 自车状态(速度、加速度等) 语言指令模板:把上述信息组织成 LLM 易理解的 prompt

按论文数据构造形式,最终训练样本会把三段内容串联起来:
<think>:文本 CoT<dream>:未来场景图像 token<answer>:轨迹 token
补充材料给出格式化表达:
05
5. 统一“文本推理 + 图像生成”的建模方式
MindDriver 的一个技术点是:把视觉生成也当作语言模型的 token 预测问题。论文做法是扩展 VQ-VAE 的视觉码本到 LLM 词表,使 LLM 能自回归地产生离散视觉 token,再用 VQ-VAE decoder 还原像素。

论文给出统一的 LM 训练目标:
其中 可以是文本 token 或视觉 token, 为 LLM 参数。
06
6. 反馈引导自动标注:如何得到“对齐”的渐进推理数据?
论文认为:训练这种多阶段推理需要高质量对齐数据,否则 SFT 会学到错误推理甚至导致性能下降。为此提出自动标注+过滤+反馈重标注的流水线(图 3)。


论文不直接用已有单帧图像 CoT 数据,原因是静态帧缺少运动趋势,容易做错决策。于是设计了基于多视角+历史视频的四段式文本推理结构:
Scene Analysis:天气、路况、能见度、信号灯、可行驶区域 Latent Risk Assessment:挑出 1–3 个最高风险目标,结合历史判断运动状态 Behavior Reasoning:提出多个候选“方向+速度”组合并解释 Action Decision:输出最终方向与速度调整类别(离散动作)
补充材料中还给出了用于 Qwen2.5-VL-72B 标注的 prompt 模板。

流水线过程是:
用 Qwen2.5-VL-72B 生成 raw CoT 依次通过三种过滤器:(a) Format Filter:检查是否有四段结构(b) Decision Filter:检查动作是否与 GT 轨迹推导的决策一致(c) Logic Filter:检查推理是否逻辑自洽(用更强的 Qwen3-235B 做逻辑审查以减少自检偏差)
若失败,则产生错误反馈(格式缺失/决策不符/逻辑错误总结),再把反馈塞回上下文重新标注(最多迭代 3 轮,补充材料说明)。
补充材料给出 meta action 类别,把方向与速度离散化用于决策过滤:
Direction Change:Maintain / Lane Left / Lane Right / Turn Left / Turn Right Speed Change:Smooth Decel / Emergency Brake / Maintain / Smooth Accel / Stop / Remain Stationary
07
7. 渐进式强化微调(Progressive RFT):分阶段奖励“过程对齐”
论文指出:单纯 SFT 是 token 级监督,可能让模型更在乎“文本流畅”,而不在乎中间对齐。为此提出两阶段 RFT,把“梦图像”和“规划轨迹”分别作为阶段目标。

Stage 1 不追求像素级复原,而追求与 GT 图像的语义一致性,采用 CLIP 相似度作为奖励:
:模型基于文本 CoT “梦到”的未来图 :数据集 GT 未来帧 :CLIP 图像编码器
直觉:文本 CoT 会点名关键对象(红绿灯、行人、切入车辆等)及其大致位置,Stage 1 让梦图像“把关键东西放在对的地方”。

Stage 2 对轨迹用几何误差而不是 token 概率进行奖励。使用平均位移误差 ADE(Average Displacement Error):
:预测轨迹点 ):GT 轨迹点 :最大允许位移误差(上界) :缩放因子

论文采用 GRPO(Gradient-Regularized Preference Optimization)来稳定训练,并给出目标函数与优势归一化定义:
其中:
总体奖励按阶段组合:
其中 强化输出格式正确性(论文补充材料解释其检查项与权重设置)。
08
8. 实验与结果:MindDriver 到底提升了什么?
论文在两类评测下验证:
nuScenes open-loop:看预测轨迹是否接近 GT、是否碰撞 Bench2Drive closed-loop(CARLA):看闭环驾驶得分、成功率等。

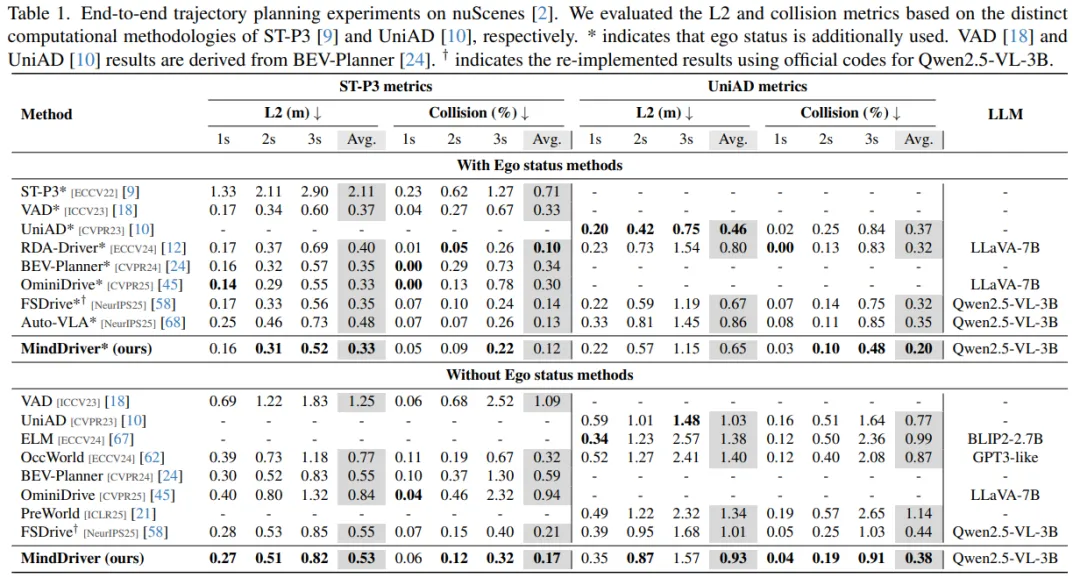
表 1 显示,在使用 Qwen2.5-VL-3B 作为基座时,MindDriver 在 L2 误差与碰撞率上整体优于多种基线(包括图像 CoT 的 FSDrive 和文本 CoT 的 AutoVLA),尤其碰撞率下降明显。
论文强调:
相比 纯图像 CoT(FSDrive),先做文本推理再梦未来图能更准、更少碰撞 相比 纯文本 CoT(AutoVLA),加入未来世界想象对降低碰撞特别有效:contentReference[oaicite:24]{index=24}。

MindDriver 还评测未来图像生成质量,用 FID 指标。表 2 中 MindDriver 的 FID 为 9.4,优于 FSDrive(10.1)以及多种扩散模型方法。论文解释:规划导向的文本推理提升了未来图像生成的准确性与关键对象表达。


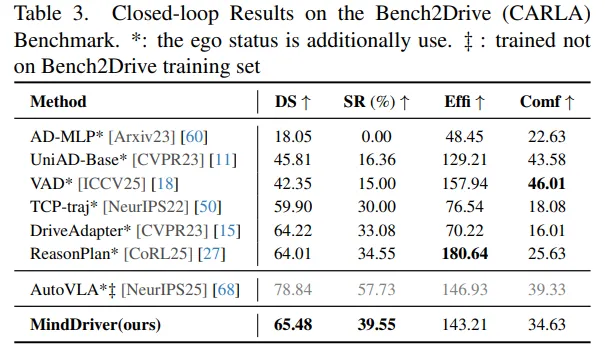
在 CARLA 闭环评测中,MindDriver 在 DS、SR 等指标上取得有竞争力的结果,成功率(SR)为 **39.55%**(表 3)。论文也指出 AutoVLA 使用了更大规模训练数据集,因此对比需考虑训练数据规模差异。
09
9. 消融实验:哪些设计真的关键?

表 4 显示:
Text CoT 比无 CoT 好 Image CoT 改善有限 MultiModal(T2I) CoT 最好(先文本推理再图像想象)。
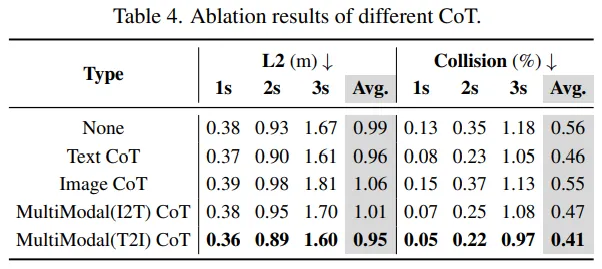
论文给出解释:符合人类逻辑——先高层语义规划,再估计未来场景细节。

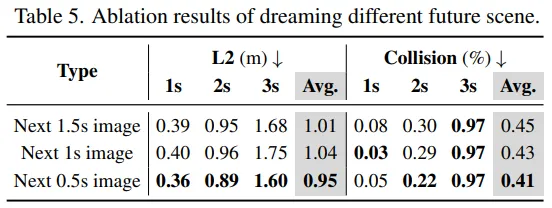
梦 0.5s 后的未来帧效果最好,可能因为输入历史视频采样间隔是 0.5s/frame,时间对齐更容易;更长跨度不确定性更大。

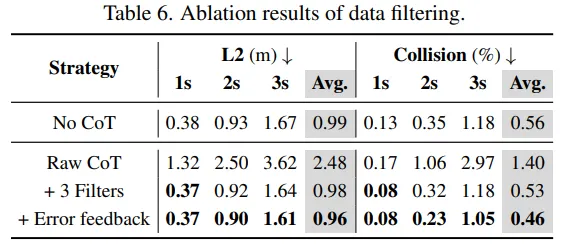
非常关键的一点:用 raw CoT(不经过过滤)训练会显著变差,甚至比“无 CoT”还糟;三种过滤 + 错误反馈重标注能把性能拉回来并提升。

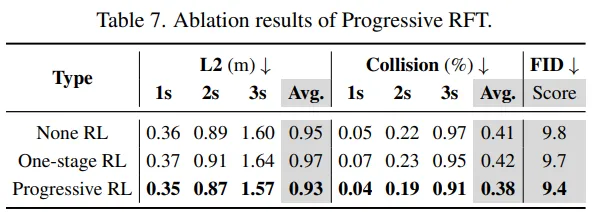
两阶段 Progressive RL 优于 one-stage RL 与不做 RL,且同时带来更低碰撞、更低 L2、以及更好的 FID(表 7)。论文解释:一步同时平衡“图像生成+轨迹规划”太难,分阶段更易对齐。
10
10. 定性分析:为什么它在复杂场景更稳?
论文用图 4展示了与 VAD、FSDrive 的对比:MindDriver 能更好地抓住关键红绿灯、动态障碍物,并在闭环测试的时间推进中更稳定。

11
11. 总结与个人解读:MindDriver 的贡献到底是什么?
论文在引言中总结贡献可以概括为三点:
提出渐进式多模态推理范式:文本语义 → 未来图像 → 物理轨迹,推理更平滑且可解释 反馈引导自动标注:用过滤+反馈重标注产出高质量对齐的推理数据 渐进式强化微调:分阶段奖励中间过程(先图像语义一致,再轨迹精度),显著提升对齐与性能
从更宏观的角度看,MindDriver 的方法论价值在于:它把“推理链”从单一模态的文本解释,升级为跨模态、跨空间(语义→物理)的中间表征对齐问题,并且用数据与训练策略把这个对齐落到工程可执行的闭环里。
12
12. 局限与未来方向
论文在结论中提到两点限制:
推理速度虽能达到约 1Hz,但依赖高算力 GPU,成本高 当前只生成前视未来图像,未来可探索更丰富、更细粒度的视觉输出


智驾 & 机器人学习交流圈

学
起
来


随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 滴滴自动驾驶牵手清华大学:成立深穹远航实验室,“产学研CP”能擦出啥火花?
- 岚图汽车 | 追光L,新时代旗舰轿车
- 【广州/深圳】自动驾驶安全员,四职级可选;路测员;第二曲线;地援;保护车驾驶员;线上视频面试!上五休二,月薪7000元~9800元/月!
- 自动驾驶分析:自动驾驶汽车的车载传感器为什么频繁失效,一颗橙子大小的路边雷达是怎么从根本上解决盲区问题的
- 【高端就业】自动驾驶安全员上五休二,年17薪,月综合9000多元/月!可接受视频面试!
- 迪拜自动驾驶公司暂停Robotaxi车队运营!
- 自动驾驶模式把我的生活毁了
- 一文解读“自动驾驶数据记录系统”(Data Storage System for Automated Driving)
- 炸场!德系旗舰SUV内饰官图曝光,双联屏+吸顶屏,6座布局太香了
- 比亚迪王朝网首款B级纯电SUV来了!
