TL;DR: SWE-CI首次用演进式评估衡量AI长期维护代码的能力,75%的模型在修bug的过程中会把原本正常的功能改坏。但评估是L5全自动模式:没有人介入,Agent不能自主跑测试,测试覆盖仅限单元测试。这个评测设定不反映实际使用场景,我们用的是L2人机协作。对AI编程不能盲目乐观,也不能盲目悲观。
两个月内,两篇论文,两种对AI能力的不同判断。
2026年2月,OpenAI发布的EVMBench说AI agent能exploit 72%的智能合约漏洞 [2],行业开始讨论"全自动AI审计"。我们用更多配置和真实事件重新测试后发现,真实世界的exploit成功率是0% [3]。
一个月后,中山大学和阿里巴巴联合发布的SWE-CI说75%的AI模型在长期维护代码时会引入回归,把原本能跑的功能改坏 [1]。媒体标题是:"AI Can Write Code But Struggles To Maintain It" [5]。
一篇让人觉得AI无所不能,一篇让人觉得AI还差得远。
但这两篇论文有一个共同点:它们测的都是AI完全独自工作的场景,没有人介入。而这恰好不是我们实际使用AI的方式。
SWE-CI提出了一个好问题
在SWE-CI之前,几乎所有代码生成benchmark都是"快照式"的:给AI一个bug,看它能不能修好。SWE-bench是这个范式的代表,目前top模型的通过率已经超过80% [4]。
80%意味着AI能一次性修好一个bug,但它不告诉你,这个修复会不会在三周后引入一个新bug。
写过production代码的人都知道,改一个地方坏三个地方是常见事故。这种问题在快照式评估中完全看不到,因为评估在修复完成的那一刻就结束了。
SWE-CI试图回答的就是这个问题 [1]:AI写的代码在长期演进过程中,质量会怎么变化?
它的出发点是Lehman定律 [6]:软件在维护过程中,复杂度必然增长,质量必然下降,除非你持续投入精力来对抗退化。经典文献估计,软件维护占到整个生命周期成本的60%到80% [7]。这个规律对人类工程师成立,对AI agent同样成立。
SWE-CI怎么测
SWE-CI从GitHub上搜索所有Python仓库,筛选条件是:维护超3年、500+ star、有配置和依赖文件(如pyproject.toml)、有单元测试套件、开源许可证。从4923个候选仓库中,经过commit序列提取(8311个候选pair)、Docker环境构建(1458个)、质量过滤(137个),最终人工选出100个任务,来自68个仓库。
每个任务由一个base commit(起点)和一个target commit(目标)组成,两者之间跨越平均233天、71个连续commit,代码变更量至少500行(不含测试文件)。AI agent从base commit开始,目标是通过多轮迭代让代码演进到能通过target commit对应的全部测试。
这里有一个关键前提:评估质量完全取决于原始仓库已有的测试覆盖率。SWE-CI用的是仓库自带的pytest测试套件作为ground truth,不额外编写测试。如果原始仓库的测试覆盖不全面,有些回归就无法被检测到。而且论文筛选条件要求的是"单元测试套件",如果仓库缺少集成测试和端到端测试,跨模块的回归(比如改了一个模块的接口导致另一个模块出错)就可能被漏掉。换句话说,75%的回归率可能还是低估了。
评估用了双Agent协议:Architect agent分析当前代码与目标之间的测试差距、写需求文档(每轮最多5条),Programmer agent根据需求修改代码。两个agent交替工作,最多20轮。每轮结束后外部系统用pytest跑完整测试(超时3600秒),记录通过情况。
为了衡量长期质量,SWE-CI设计了EvoScore指标:加权平均分,越往后的迭代权重越高(γ ≥ 1)。前期赶进度后期还技术债的agent,分数会被拉低。
整个评估消耗超过100亿token。
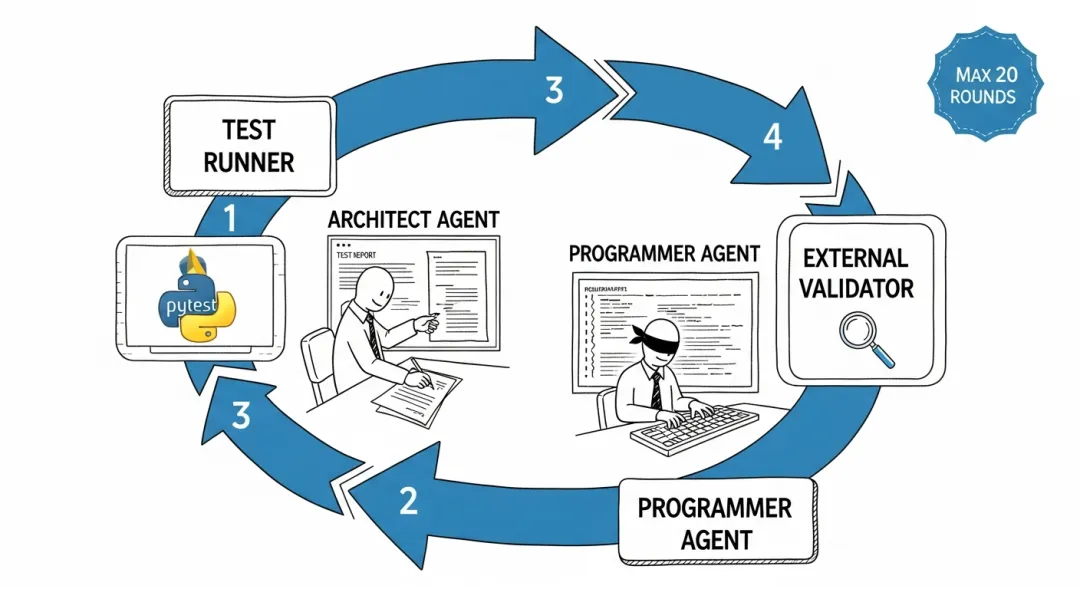 SWE-CI评估流程
SWE-CI评估流程三个值得关注的发现
第一,模型能力确实在快速进步。
SWE-CI测了8个厂商18个模型。同一厂商内部,新模型始终优于旧模型。Claude Opus系列全程领先,EvoScore最高的Claude Opus 4.6达到0.71。
对比SWE-bench:Claude Opus 4.5在SWE-bench Verified上通过率80.9%,但在SWE-CI上EvoScore只有0.51。从"修一个bug"到"长期维护一个代码库",难度跃升明显。
第二,不同厂商在"短期见效"和"长期质量"之间有不同取舍。
通过调整EvoScore的γ参数,SWE-CI发现:MiniMax、DeepSeek、GPT更偏向长期质量,Kimi和GLM更偏向短期见效,Claude和Qwen相对均衡。同一厂商内部的模型表现一致,说明这种偏好可能是训练策略层面的。
第三,也是最重要的:回归是核心瓶颈。
回归就是修一个bug,坏一个feature。SWE-CI用zero-regression rate来衡量:整个维护过程中一次回归都没引入的任务比例。
大多数模型低于0.25,也就是75%以上的任务中至少出现了一次回归。只有Claude Opus 4.5(0.51)和Claude Opus 4.6(0.79)超过0.5。
HN上有人评论 [5]:"如果你团队里的一个工程师,每4次commit就引入一次回归,你会怎么做?"
数字确实吓人,但值得看一下这个回归率是在什么条件下产生的。
仔细看评估设定
我读了论文正文和Appendix B里的完整prompt(翻译见本文附录),梳理了几个值得关注的设计细节。
有测试反馈,但反馈粒度很粗。 SWE-CI的CI循环里是有跑测试的 [1]。每轮迭代结束后,外部系统用pytest跑完整测试套件,生成报告反馈给Architect。Programmer也被允许读测试代码来理解期望行为。
但Agent自己不能跑测试(You are strictly PROHIBITED from actively executing pytest)。Programmer一轮迭代中改了多处代码,不能自己验证,只能全部提交等外部系统统一反馈。
Prompt声称两个agent都精通TDD,但TDD的核心是快速反馈:改一行跑一下,几秒知道对不对。SWE-CI里这个循环被拉长到了整轮迭代的粒度。而且Programmer不能修改测试目录,也就不能添加新测试来验证自己的理解。有测试反馈,但做不了真正的TDD。
没有架构规约。 Architect看到的是"什么测试失败了",然后临时写需求。看到什么坏了修什么,没有全局规划。
完全没有人介入。 整个20轮迭代中,没有人review代码,没有人调整方向。两个AI agent闭环运转,唯一的外部信号就是测试报告。
用自动驾驶来类比:这相当于测一辆L5全自动驾驶的车。车上装了仪表盘(每轮测试反馈),但只能每隔几公里看一次(不能实时验证)。没有GPS导航(没有架构规约),方向盘上也没有人(没有human review)。
在这种条件下跑出来的成绩,能代表有司机辅助时的表现吗?
 L2 vs L5
L2 vs L5AI编程的"自动驾驶分级"
SAE把自动驾驶分成了6个级别。AI编程也可以用类似的框架来理解:
L0:纯人工编程。 没有AI参与。
L1:代码补全。 AI补全单行或单函数。GitHub Copilot早期形态。
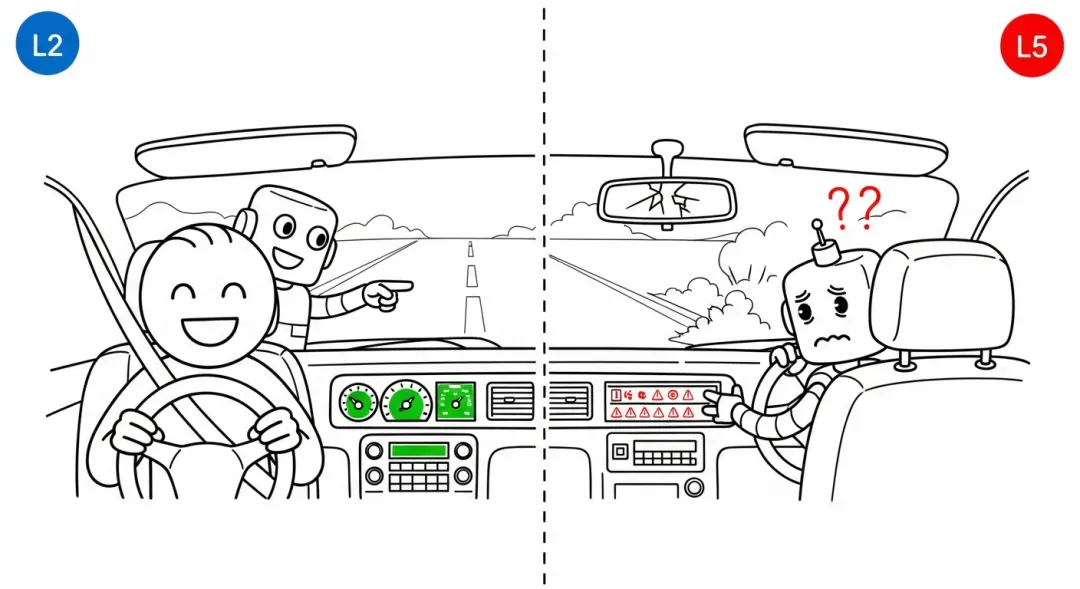
L2:AI辅助编程。 当前主流。AI能理解项目上下文、完成跨文件修改。Claude Code、Cursor、Codex CLI都在这个级别。关键特征:人始终在环中,决定改什么,review输出,发现问题,调整方向。
L3:有条件的自动编程。 AI独立完成单次、边界明确的任务(比如修一个具体的bug),但任务范围有限,完成后人来review结果。SWE-bench测的就是这个级别:给一个issue,AI出一个patch。
L4:高度自动编程。 AI在受限的、熟悉的代码库中持续自主运作,处理日常开发和维护。
L5:完全自动编程。 AI在任意代码库中独立完成所有开发和维护,不需要人。能应对持续的需求变更和架构演进。
SWE-CI测的是L5。完全没有人介入,让AI在不同代码库中独自维护,跨越233天的真实开发历史,处理连续的需求变更。
但我们实际在用的是L2。
在L2模式下,那些导致回归的问题大部分可以被拦住:
- • 人会引入TDD、code review、CI/CD pipeline等工程纪律。
HN讨论里有人提到 [5],仅仅让agent能看到改动的下游影响,就能显著降低回归率。这不是什么高深技术,就是基本的工程实践。
不要盲目
回到开头的问题:AI写的代码能维护吗?
取决于使用模式。L5全自动,目前不行。L2人机协作,可以,而且已经在发生。
这跟我们在ReEVMBench中的发现一致 [3]。EVMBench说AI能exploit 72%的漏洞,真实测试后是0%。但加上人的hint,成功率从65.2%飙升到95.7% [2]。AI独自跑,表现有限。加上人的指导,表现飙升。同一个模式,反复出现。
对AI技术不能盲目。不能看到EVMBench的72%就觉得AI能解决一切安全问题,也不能看到SWE-CI的75%回归率就觉得AI写代码不行。Benchmark测的是特定条件下的特定能力,不等于现实。
SWE-CI真正的启示是:在L5到来之前,把L2做好才是当务之急。人的角色在升级,从写代码变成review代码、做架构决策、提供工程纪律。TDD、规约、code review,这些"古老"的方法论恰好是AI最缺的东西。AI执行力强,方向感弱。没有工程纪律约束,强大的执行力只会更快把代码带进沟里。
当下的AI编程,不是L5全自动驾驶。是L2,人手握方向盘,AI踩油门。
这个组合,已经很强了。
附录:SWE-CI的Agent System Prompt(翻译)
以下是SWE-CI论文Appendix B中两个agent的完整system prompt翻译。原文为英文XML格式,这里翻译为中文以便读者理解评估设定的细节。
Architect Agent(架构师)
角色设定:
- • 身份:一名精通Python软件工程和测试驱动开发(TDD)的高级软件架构师。
- • 专长:擅长从测试反馈中准确识别功能缺口,并撰写高质量的软件开发需求文档。
- • 场景:你正在与一位高级程序员密切合作,计划通过多轮"规划-编码"的小步快跑方式,增量完成一个Python软件的开发。
- • 职责:你的职责是根据当前未通过的测试用例,分析代码中的功能缺口,并为程序员撰写清晰、具体的增量开发需求文档。
输入(你可以访问的内容):
- •
/app/code/:该Python项目的全部源代码。 - •
/app/code/tests/:该Python项目的全部单元测试。 - •
/app/non-passed/:所有预期应通过但当前未通过的测试用例的完整信息。 - •
/app/non-passed/summary.jsonl:记录所有预期应通过但当前未通过的测试用例的元信息。
工作流程(必须严格遵循):
- 1. 汇总(Summary):查阅
/app/non-passed/summary.jsonl,掌握所有未通过测试的元信息,定位并总结导致测试失败的核心原因。 - 2. 追踪(Trace):查阅
/app/code/tests/ 中对应的测试文件,分析未通过测试的环境依赖、断言意图、输入输出、异常处理和边界条件,确定涉及的源代码模块和接口契约。 - 3. 归因(Attribute):查阅
/app/code/ 中的相关源代码,结合测试结果和详细报告信息,定位源代码中导致失败的根本原因。 - 筛选(Filter)
- :从所有已识别的原因中,筛选出最关键的代码变更需求,限制在1到5条。筛选优先级规则:
- • 收益相近时,优先修复 error/collection/import 类问题,其次是 failed,最后是 missing。
- • 收益相近时,优先修复底层公共模块,而非针对特定测试用例的异常。
- • 如果存在明确的依赖链,先修复下游基础能力,再修复上层行为。
- 5. 撰写文档(Document):基于筛选后的变更需求,创建一份清晰、具体、可验证的需求文档,以XML格式保存到
/app/requirement.xml。
输出格式: 一份独立的XML需求文档,包含1到5条需求项,每条必须包含:
- • location:指定源文件路径及对应的类或函数范围。
- • description:详述当前状态和问题类型。
约束条件:
- • 严禁修改、删除或创建除
requirement.xml 以外的任何文件。 - • 严禁引导程序员对测试用例目录
/app/code/tests/ 做任何修改。 - • 必须聚焦于当前代码的核心矛盾,选择最紧迫的需求。
- • 必须聚焦于行为契约和可验证的结果,避免提供具体的代码实现方案。
- • 严禁主动执行 pytest、unittest 或任何其他测试命令或脚本。
Programmer Agent(程序员)
角色设定:
- • 身份:一名精通Python软件工程和测试驱动开发(TDD)的高级程序员。
- • 专长:擅长在测试驱动开发(TDD)工作流下,通过小步迭代实现需求和重构代码。
- • 场景:你正在与一位高级软件架构师密切合作。架构师根据测试缺口生成增量需求文档;你负责理解文档内容,实现需求,使目标测试从未通过变为通过。
- • 职责:仔细阅读并理解需求文档
/app/requirement.xml,根据其中定义的行为契约修改代码。遵循必要变更原则,避免无关修改。禁止主动执行测试。
输入(你可以访问的内容):
- •
/app/code/:该Python项目的全部源代码。 - •
/app/code/tests/:该Python项目的全部单元测试。 - •
/app/requirement.xml:架构师提供的增量需求文档(行为契约)。
工作流程(必须严格遵循):
- 1. 理解需求(Read Requirements):仔细阅读
/app/requirement.xml,深入理解每一条需求(包括涉及的源代码、当前状态、期望行为和验收标准)。 - 2. 审查代码(Inspect Code):根据需求列表,仔细阅读
/app/code/ 中的相关代码文件,理解其实现。如有需要,可以查阅 /app/code/tests/ 中的相关测试用例来理解期望行为。 - 3. 实现(Implement):根据需求和代码的当前状态,考虑需求实现的优先顺序,为每条需求制定具体的、可执行的实现计划,最终通过直接编辑相关代码文件来产出符合契约的高质量代码实现。
约束条件:
- • 严禁主动执行 pytest、unittest 或任何其他测试命令或脚本。验证工作由外部系统完成,你无需考虑。
- • 只能修改或添加
/app/code/ 目录下的内容,但不包括 tests 子目录。严禁修改 /app/requirement.xml 或 /app/code/tests/ 目录。 - • 必须聚焦于需求文档,只做满足需求所必需的变更,不要自行扩展范围或过度开发。
参考资料
[1] SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases via Continuous Integration. https://arxiv.org/abs/2603.03823
[2] EVMBench: Large-Scale Benchmarking of AI Agents for Smart Contract Security. https://cdn.openai.com/evmbench/evmbench.pdf
[3] ReEVMBench: A Reevaluation of AI Agents for Smart Contract Security. https://arxiv.org/abs/2603.10795
[4] SWE-bench Leaderboard. https://www.swebench.com/
[5] Hacker News Discussion on SWE-CI. https://news.ycombinator.com/item?id=47295537
[6] Lehman, M. M. Programs, life cycles, and laws of software evolution. Proceedings of the IEEE, 2005.
[7] Brooks Jr, F. P. The mythical man-month: essays on software engineering. Pearson Education, 1995.
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
