街景重建是自动驾驶仿真中的关键一环。无论是训练感知系统、验证规划策略,还是生成极端场景来测试安全边界,高保真的视觉重建都不可或缺。
过去几年,3D 高斯泼溅(3D Gaussian Splatting, 3DGS) 已经展现出惊人的重建能力。它对几何和外观的捕捉精度远超传统 NeRF。但这种精度的代价是巨大的——为了一条普通街道,现有方法需要动辄上百万个高斯原语,每一帧渲染都要遍历这些体量庞大的数据。
存储空间被迅速耗尽,渲染帧率也掉到了无法实时交互的水平。
这听起来很矛盾:明明自动驾驶场景里,有大量区域是基本静止的——路面、楼宇、远处的树——它们真的需要和一辆移动中的汽车保持同样的表达密度吗?
显然不需要。
来自北京大学、中科院、伊利诺伊大学厄巴纳-香槟分校以及蔚来汽车的研究团队抓住了这个观察,提出了 SparseStreet——一个专为街景高斯溅推设计的即插即用压缩框架。
论文标题SparseStreet: Sparse Gaussian Splatting for Real-Time Street Scene Simulation
项目地址https://sparsestreet.github.io/
论文地址https://arxiv.org/pdf/2606.03909
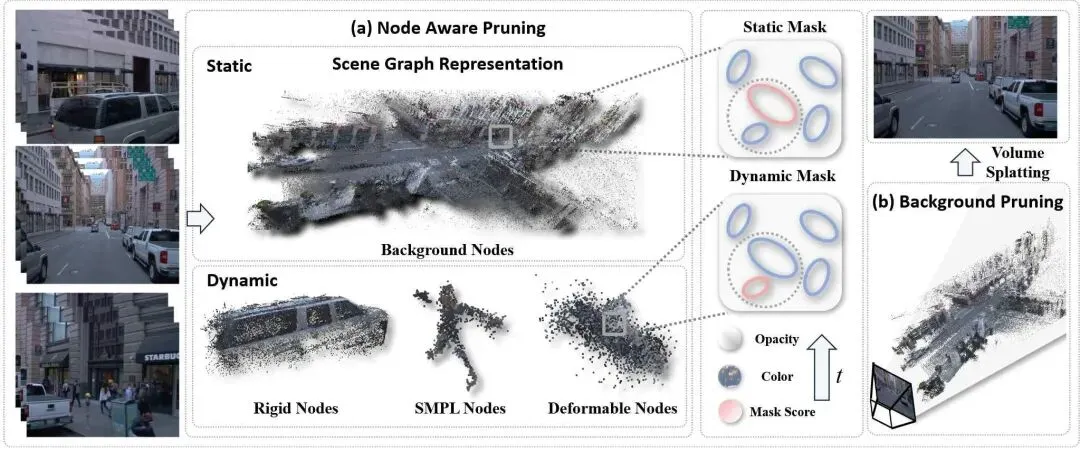
这一思路源于对街景结构本身的重新审视。自动驾驶场景从来不是一片均匀的空间,它天然分割为两个部分:动态前景和静态背景。动态物体(车辆、行人、骑车人)需要精细的高斯表达来保持时序一致性;而静态背景区域,只要几何和纹理没有剧烈变化,用较少的原语就能完成重建。
但现有的 3DGS 方法并未利用这种结构差异,它们对所有区域一视同仁,导致大量计算资源浪费在背景的冗余表达上。
街景的“两面性”被忽略了
我们先来看当前主流方法的处境。
以 StreetGS 和 OmniRe 为代表的有监督街景重建方法,已经能够构建场景图(Scene Graph)——将背景节点、刚性节点(车辆)、可变形节点和 SMPL 节点(行人)分层建模。这种结构本身已经区分了动与静、刚体与非刚体。
但在渲染端,每个节点内的高斯原语数量并没有被差异化对待。
一辆车可能在某一时刻只占画面的很小一部分,但与其关联的成千上万个高斯体仍然完整保留。同样,一片路面上可能堆积了远超表达需求的高斯原语——它们的存在对画面质量的贡献微乎其微,却实实在在地拖慢了每一帧的渲染。
更麻烦的是,全局重要性剪枝在街景中并不适用。一辆车可能在左侧摄像头中出现几帧后就驶出视野,如果仅凭它在所有视角下的平均贡献来决定去留,这辆车随时可能被误删——导致在其他视角中凭空消失。
研究团队在论文中用一组对比图直观展示了这个问题:用全局剪枝处理运动车辆,车身部件在前视摄像头中就会出现明显的缺失。
节点感知的“可学习剪枝”
SparseStreet 的核心设计分为两层。
第一层是节点感知剪枝(Node-aware Pruning)。研究团队为每个高斯原语引入了一个额外的可学习掩码参数。这个参数通过 sigmoid 函数映射为一个保留概率,再经由直通估计器(Straight-Through Estimator) 生成二值掩码——决定这个高斯原语最终是保留还是丢弃。
关键在于:这个剪枝过程不是笼统施加一个全局压强,而是根据场景图里不同节点类型,赋予不同的正则化系数。
背景节点被分配较大的系数,施加更强的剪枝压力。刚性节点(车辆)的系数要低两个数量级。而 SMPL 节点和可变形节点则给出最低的惩罚系数——因为行人的关节点运动和细微形变一旦丢失,视觉质量会急剧下降。
不仅如此,动态物体的高斯原语还有一个时间维度的问题:某些高斯体只在特定时间段参与渲染。研究团队为此设计了一个时间依赖掩码模块,用一个轻量的 MLP 网络,根据归一化的时间t、可学习的时序特征f和三维空间位置p,动态输出每个时刻的掩码值。
这样一来,一个只在第 2 秒到第 5 秒之间出现的行人,其高斯原语不会因为其他时间段的“沉默”而被错误剪掉。
背景压缩:在稳定之后“精准清场”
第二层是背景压缩(Background Compression)。
当场景表达在前两万多步训练中趋于稳定后,SparseStreet 会在训练的第 24,000 步到第 28,000 步之间,对背景节点执行第二阶段的深度剪枝。
具体做法是计算每个背景高斯体在所有训练图像上的全局重要性分数。这个分数结合了混合权重(blending weights) 和投影面积——一个高斯体如果在最终渲染中被频繁调用,且投影面积大,它的重要性就高;反之,那些几乎没有参与像素混合的冗余高斯体,会被标记为低贡献并移除。
这个设计避免了在场景尚未充分优化时就过早删除高斯体——信息不足时做出的删减决策往往是不可逆的,而等到表达稳定后再精准清理,可以在几乎不影响质量的前提下,大幅压缩体积。
80% 压缩率下的质量坚守
在 Waymo-NOTR 数据集上,研究团队将 SparseStreet 分别嵌入到 StreetGS 和 OmniRe 中进行评估。
OmniRe+Ours 的组合交出这样一份答卷:高斯原语数量从 1.55M 压缩到 0.46M,减少了约 70%,同时全图 PSNR 仅从 34.26 微降至 34.05,SSIM 从 0.956 降至 0.952。在车辆和行人的局部指标上,PSNR 降幅也都在 0.5dB 以内。
但 FPS 的变化是惊人的:从 46.15 跃升至 80.22,真正达到了实时渲染的水平。
StreetGS+Ours 甚至更激进——原语数从 0.87M 压缩到 0.29M,缩小到原来的三分之一,FPS 从 21.60 翻倍到 57.66。
在 nuScenes 上,趋势保持一致。StreetGS 搭配 SparseStreet 后,高斯原语数从 0.72M 压缩到 0.26M,FPS 从 117.80 飙升到 461.17——接近 4 倍的渲染加速。
在消融实验中,研究团队对比了仅使用节点感知剪枝、仅使用背景压缩,以及两者的组合。结果显示:单独使用节点感知剪枝虽然能保持较高的重建质量,但高斯原语数仍然偏高(0.65M)。单独使用背景剪枝可以大幅压缩(0.39M),但在动态物体的保护上不如组合方案。Full Model 在 0.32M 的原语数下拿到了最佳的 SSIM 和 LPIPS,体现了两种策略的协同效应。
一个巧妙的“结构利用”思路
SparseStreet 最打动人的地方,在于它没有重新设计渲染管线,也没有引入复杂的压缩编码。
它只是认真审视了街景本来就有的结构——场景图里静与动的区分,然后据此决定把计算资源花在刀刃上。背景可以稀疏,动态物体必须密集;暂时的沉默不该被惩罚,冗余才该被移除。
研究团队还测试了新轨迹合成(Novel Trajectory Synthesis) 的能力。在 Waymo 数据集上,使用 SparseStreet 压缩后的 OmniRe 模型,在不同的横向偏移下(1m、2m、3m),FID 指标与原始 OmniRe 基本持平——说明压缩并没有损害模型的泛化能力。
目前 SparseStreet 依赖有监督的场景图标注。研究团队也在论文末尾展望了与自监督街景方法结合的可能性——如果未来能够在不依赖语义标签的情况下自动识别和区分动静态区域,这套压缩策略的适用范围将进一步拓宽。
对于正在努力让高质量街景重建从实验室走向实际部署的研究者和工程师来说,SparseStreet 提供了一个方向清晰、落地成本可控的答案。