做 CV 项目的都知道 LabelMe。
一张一张手动画框、标多边形、打关键点。几千张图标下来,手腕都快废了。
X-AnyLabeling 相当于标注界的自动驾驶——你点一下,AI 自动识别目标画好框,你只需要确认或微调。内置 SAM、YOLO、PP-OCR 等几十种模型,下载打开就能用。
GitHub:https://github.com/CVHub520/X-AnyLabeling
01 LabelMe 十年没变,标注方式变了
LabelMe 发布于 2016 年,核心功能是手动画多边形。这十年 AI 翻天覆地,但标注工具基本没进化。
X-AnyLabeling 做的事情很简单:把 SAM、YOLO 这些模型塞进标注工具里。
点一个位置,SAM 自动分割出物体轮廓。框一个区域,YOLO 自动识别出目标类别。画一行文字,PP-OCR 自动识别出文本内容。
不是「AI 辅助」,是 AI 主导,人确认。
02 几十种模型,想用什么用什么
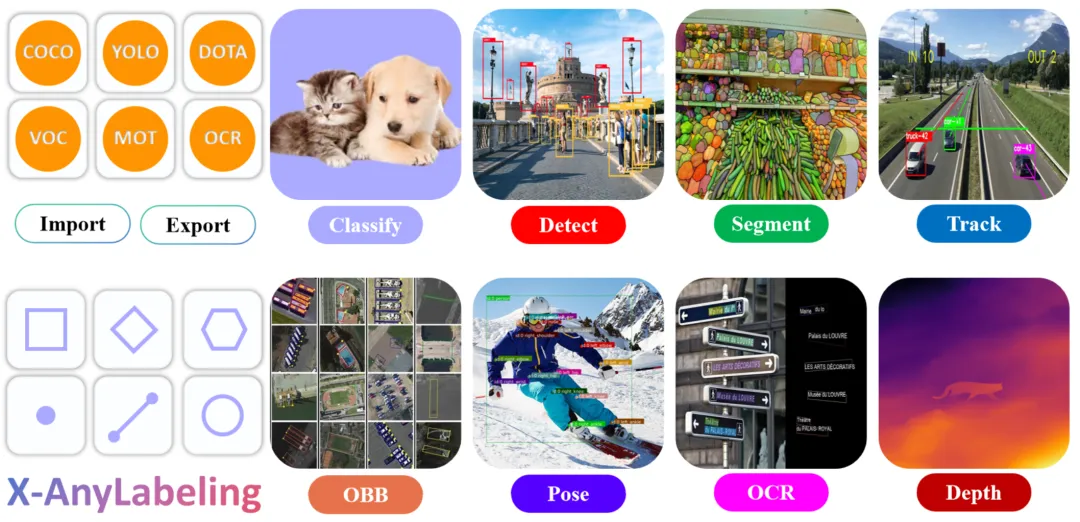
X-AnyLabeling 内置了完整的模型动物园,按任务类型分类:
| |
|---|
| 图像分类 | YOLOv5-Cls, YOLOv8-Cls, YOLO11-Cls, InternImage |
| 目标检测 | YOLOv5~26, YOLOX, RT-DETR, D-FINE, RF-DETR, DAMO-YOLO 等十几种 |
| 实例分割 | YOLOv5/8/11/26-Seg, RF-DETR-Seg |
| 姿态估计 | YOLOv8/11/26-Pose, DWPose, RTMO |
| 分割一切 | SAM 1/2/3, SAM-HQ, MobileSAM, EdgeSAM 等 |
| 多目标追踪 | Bot-SORT, ByteTrack, SAM2/3-Video |
| 旋转框检测 | |
| 深度估计 | |
| OCR | PP-OCRv4/v5, PaddleOCR-VL |
| 文档解析 | PaddleOCR-VL-1.6, PP-DocLayoutV3 |
| 视觉语言模型 | Qwen3-VL, Florence2, Rex-Omni |
| 物体计数 | |
| 开放词汇检测 | Grounding DINO, YOLO-World, YOLOE, SAM 3 |
几乎覆盖了 CV 领域的主流模型。而且支持 ONNX Runtime、TensorRT、OpenCV DNN 三种推理后端。
03 不只是画框
标注界面的功能也比 LabelMe 丰富得多:
- • 标注类型:矩形、多边形、旋转框、3D 立方体、圆形、线条、关键点、线段
- • OCR 标注:文本检测 + 文本识别 + KIE(关键信息提取),一条链路
- • 视频标注:SAM2/SAM3 视频追踪,标记第一帧后面自动跟
- • VQA 标注:图文问答,给图片写问题 + 答案
- • 聊天机器人:内置对话界面,标注同时可与模型交互
04 格式兼容和导入导出
LabelMe 用户最担心的就是数据迁移。X-AnyLabeling 兼容 LabelMe 格式,已有数据可以直接打开。
导出格式覆盖主流数据集标准:
COCO、VOC、YOLO、DOTA(旋转框)、MOT(追踪)、MASK(分割)、PPOCR(OCR)、MMGD、ShareGPT
不管你在用什么框架训练,基本都能导成需要的格式。
05 自定义模型
如果你有自己的训练模型,也可以接进来。
把模型转成 ONNX,写一个 YAML 配置文件,放到指定目录下,X-AnyLabeling 就能用你的模型做自动标注。
这就能形成一个闭环:
手动标一批 → 训练模型 → 模型自动标第二批 → 人工修正 → 训练更强的模型 → ……
写在最后
标注工具是个不太起眼的细分领域,但所有做 CV 的人每天都离不开它。
LabelMe 是开创性的,但十年过去了,标注工具还停留在「画框」阶段,说不过去。
X-AnyLabeling 做的,就是把 AI 能力塞进标注工具,让标注从手动变成自动确认。
GitHub:https://github.com/CVHub520/X-AnyLabeling