Armor推荐理由
自动驾驶感知最难的地方,已经从单个传感器能力竞争,转向雨雾、远距、小目标、遮挡和实时推理之间的系统级取舍。
这篇 ICMR 2026 综述把 Camera、LiDAR、毫米波雷达、4D Radar 和跨模态交互放到同一张地图里,对 300 多篇论文做了路线分类和性能对比。它的价值不在某个单点 SOTA,而在于把“谁更准、谁更快、谁更便宜、谁更抗天气”这些工程问题摆到了一起。
对自动驾驶感知系统来说,多模态 3D 检测已经进入“传感器拼图”阶段:拼得好,系统更稳;拼得重,成本、延迟和部署复杂度都会反噬。
原论文信息
论文标题: Multi-Modal 3D Object Detection in Autonomous Driving
发表日期: 2026年06月
发表单位: 华东师范大学
期刊: International Conference on Multimedia Retrieval 2026 (ICMR 2026)
原文链接: https://dl.acm.org/doi/10.1145/3805622.3810700
开源代码: 未开源
通讯作者: Xin Lin,华东师范大学
雨雾夜路上,单一传感器为什么会失手?
一辆自动驾驶车在夜雨里靠近路口,摄像头还能看见红绿灯和车道线,但远处行人的深度不可靠;LiDAR 给出空间结构,却会被雨雾和稀疏点云拖累;毫米波雷达能扛天气,还能给速度信息,但轮廓分辨率不够细。真正上车之后,感知系统面对的是一组互相牵制的硬件约束。
这篇综述讨论的核心问题,就是自动驾驶 3D 目标检测里这块“传感器拼图”该怎么拼。
第一个矛盾是精度和成本。Camera-LiDAR 组合在 KITTI、Waymo 等基准上长期占优,因为摄像头补语义,LiDAR 补空间几何。但 LiDAR 价格、安装、标定和恶劣天气稳定性都会进入整车 BOM 和维护成本。
第二个矛盾是鲁棒性和分辨率。Camera-Radar 成本更低,也更适合雨雾、低光和动态目标跟踪。问题在于普通毫米波雷达点云稀疏,角分辨率有限,对小目标、复杂外形和密集交通的表达能力弱。
第三个矛盾是模型能力和实时部署。深度融合、Transformer、跨模态交互能提高精度,但也会增加特征对齐、BEV 表示、注意力计算和多传感器同步的开销。车端嵌入式系统不只看 mAP,还要看 FPS、功耗、片上内存和数据带宽。
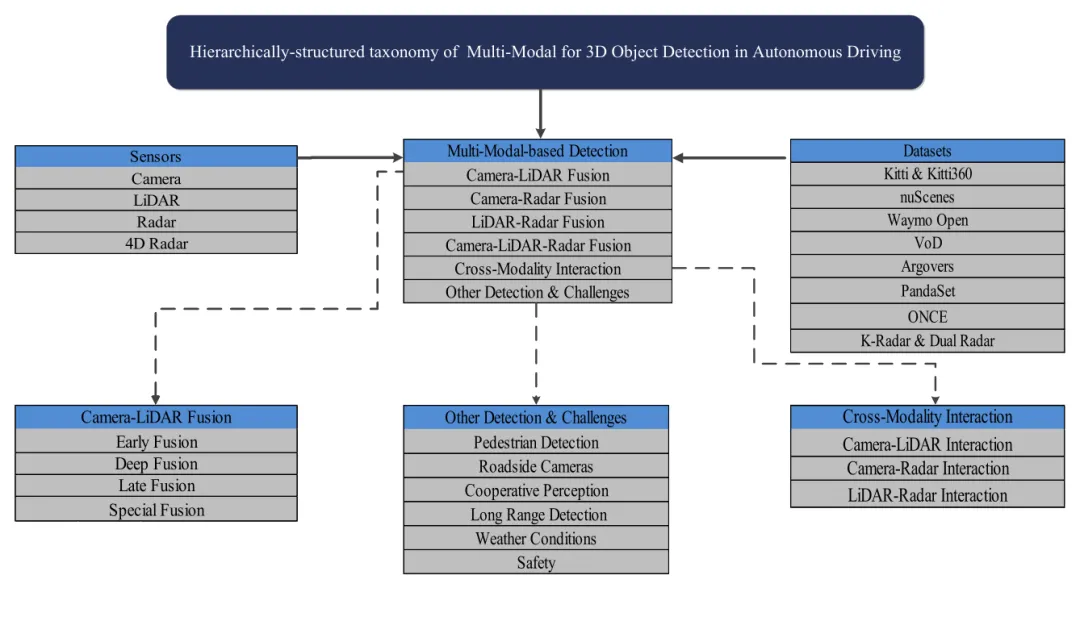
现有路线大致可以分成几类:
🚗 Camera-LiDAR 融合:精度强,空间和语义互补明显,但硬件成本和标定复杂度高。📡 Camera-Radar 融合:更便宜、更抗天气,还能利用速度信息,但检测精细结构时吃亏。🔦 LiDAR-Radar 融合:适合远距和动态场景,但两个传感器的数据稀疏性和成本问题仍然存在。🧠 跨模态交互:通过注意力、对齐和知识蒸馏让模态之间互相补课,但工程上更依赖算力和稳定标定。这些路线共同卡在同一个问题上:多模态检测的关键,是在不同传感器的短板之间寻找最不吃亏的组合。
化繁为简的妙招:从“堆传感器”到感知拼图
如果只按“用了哪些传感器”来分类,多模态检测很快会变成方法名列表。论文作者更有用的处理,是把传感器组合、融合阶段、跨模态交互和应用挑战拆开看,让读者能从系统设计角度判断一条路线适合什么场景。
第一层是传感器维度。摄像头、LiDAR、Radar、4D Radar 分别提供语义、几何、速度、全天候和更高维运动信息。它们更像能力互补关系。摄像头看得“像不像”,LiDAR 看得“在哪儿”,雷达看得“动不动”,4D Radar 进一步补上高度和更细的运动结构。
第二层是融合位置。早期融合把原始或浅层数据尽早拼起来,延迟低,但容易被噪声和坐标误差影响;深度融合在特征层学习互补关系,精度强,但算力更重;晚期融合把各自检测结果再合并,速度快、工程改造成本低,但信息交互不足。
第三层是跨模态交互。2023 年之后,很多工作不再满足于把特征拼接起来,而是显式建模 Camera-LiDAR、Camera-Radar、LiDAR-Radar 之间的对应关系。常见做法包括把 2D 图像特征提升到 3D 空间,把 3D 点云投影回图像平面,用注意力做局部匹配,或者用知识蒸馏让一种模态学习另一种模态的强项。
这套分类的好处是,它把“传感器拼图”拆成了可讨论的工程问题。一个团队如果目标是城区低速 Robotaxi,可能更愿意承受 LiDAR 成本换精度;如果目标是量产辅助驾驶,Camera-Radar 的成本和天气鲁棒性就会变得更关键;如果目标是高速远距感知,Radar、4D Radar 和协同感知的权重会继续上升。
从分类地图到选型流程
真正做系统选型时,工程师不会先问“哪个方法最新”,而会先问三个问题:目标场景是什么,硬件预算是多少,延迟上限在哪里。这篇综述最适合被当成一张路线地图来看。
面向高精度 3D 定位,Camera-LiDAR 仍然是主线。论文汇总的代表方法里,深度融合和跨模态交互在 KITTI、nuScenes、Waymo 上表现最稳。它们通过 BEV 表示、多尺度特征融合和空间对齐,把图像语义和点云几何合在一起,适合对检测精度要求高的自动驾驶场景。
面向低成本和恶劣天气,Camera-Radar 是更现实的方向。Radar 能提供速度信息,在雨、雾、低光和远距动态目标上有优势。论文中 RCBEVDet 这类 Camera-Radar 方法在 nuScenes 上达到 28 FPS,mAP 在 55% 左右。这个数字不如 Camera-LiDAR 深度融合漂亮,但对成本敏感的量产系统更有参考意义。
面向更远距离和更复杂协同,LiDAR-Radar、Camera-LiDAR-Radar 和 V2X 感知会继续扩展边界。单车传感器有视角盲区,路侧摄像头和车车协同可以补充被遮挡区域。不过,多主体感知会带来通信时延、时间同步、坐标对齐和安全攻击面的问题。拼图变大了,缝隙也会变多。
从计算资源看,融合模块通常会吃掉车端算力预算。特征对齐依赖投影和采样,BEV 表示依赖大量栅格特征,注意力交互的开销会随 token 或候选区域增长。论文也提到,轻量网络、剪枝、量化、ROI 裁剪、动态推理、AI 芯片和 FPGA 加速,都是多模态 3D 检测走向嵌入式部署时绕不开的工具。
谁在精度和速度之间更接近实车?
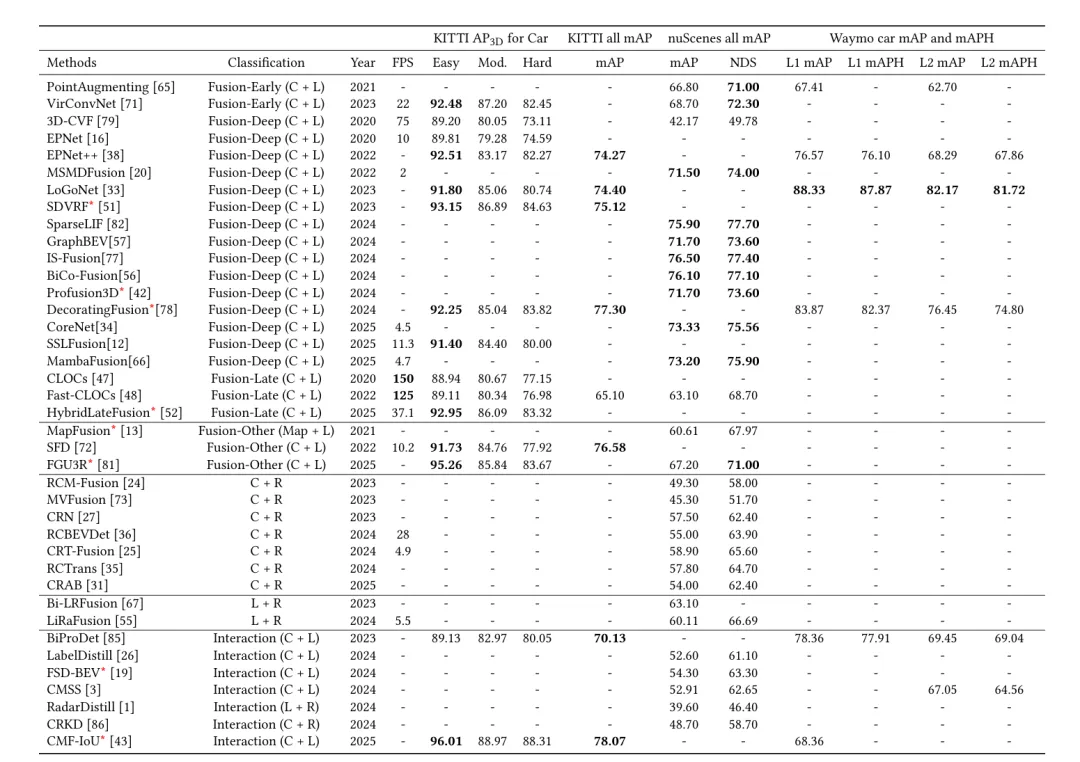
只看排行榜会误导人。自动驾驶检测系统真正要比较的是“同样的硬件预算下,能不能稳定跑完一帧”。论文的表 3 把 FPS、KITTI AP3D、KITTI mAP、nuScenes mAP、NDS、Waymo mAP 和 mAPH 放到了一起,能看到几条很清楚的工程趋势。
Camera-LiDAR 深度融合的精度优势最明显。IS-Fusion 在 nuScenes 上达到 76.50% mAP 和 77.40 NDS;SparseLIF、BiCo-Fusion 等方法也在 75% mAP 附近。KITTI 上,CMF-IoU 的 easy AP3D 达到 96.01%,all mAP 达到 78.07%。这说明跨模态交互和精细对齐已经把 Camera-LiDAR 的上限继续往上推。
速度侧则更有意思。CLOCs 能做到 150 FPS,Fast-CLOCs 有 125 FPS,但它们属于晚期融合,精度上不占优。3D-CVF 有 75 FPS,VirConvNet 有 22 FPS,RCBEVDet 作为 Camera-Radar 方案达到 28 FPS。CoreNet、MambaFusion 这类 2025 年方法在 nuScenes 上保持 73% mAP 以上,但 FPS 只有个位数级别。工程上,这意味着“更强的融合”常常会把延迟账单留给车端芯片。
Camera-Radar 的定位很明确:它给成本、天气鲁棒性和实时性留空间。RCBEVDet 的 28 FPS 配合约 55% nuScenes mAP,放在量产辅助驾驶语境里比单纯追求 76% mAP 更有讨论价值。因为车厂真正关心的是,一套方案能不能在目标 SoC 上稳定运行,并覆盖足够多的低光、雨雾和动态目标场景。
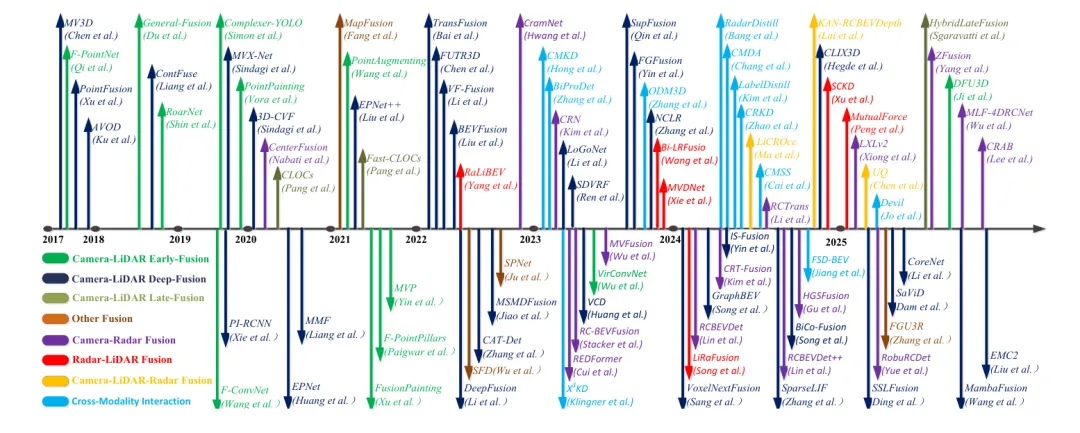
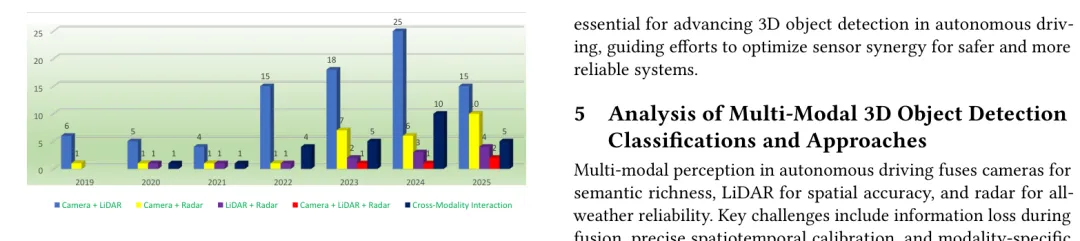
论文对 2019 到 2025 年方法数量的统计也透露了趋势:Camera-LiDAR 仍然最多,Camera-Radar 和跨模态交互在 2023 年后增长更快。行业正在从“谁的单点精度最高”转向“谁能更好地组合传感器能力”。
从榜单到路面:这张地图能怎么用?
同一套感知模型,在晴天开放道路上可能表现很好,一到雨雾、逆光、施工路段和密集行人场景就会暴露问题。综述把长距离检测、恶劣天气、安全、行人检测、路侧摄像头和协同感知单独拉出来讨论,说明多模态 3D 检测已经不能只靠 benchmark 精度讲故事。
长距离检测需要更强的动态目标建模。远处车辆和行人的点云更稀,图像目标更小,Radar 的速度信息反而变得重要。RangeFSD、RCBEVFusion、SaViD 这类工作代表了一个方向:按距离段处理目标,让近距离和远距离不再共用一套粗暴的特征策略。
恶劣天气会放大传感器短板。雨雪会干扰 LiDAR,低光会削弱摄像头,Radar 会带来散射和虚警。REDFormer、RIDERS、ContextualFusion 等路线说明,未来系统需要把天气条件纳入模型设计,而不是只在训练集里多塞一些雨天样本。
安全问题更值得警惕。论文把检测安全和系统安全分开:前者关心漏检、误检、遮挡、小目标和效率;后者关心攻击、传感器失效和网络安全。多模态系统看似更稳,但攻击面也更多。图像攻击、frustum 攻击、后门攻击和传感器欺骗都可能让“传感器拼图”出现错位。
这也是这篇综述对工程读者最有用的地方:它没有把多模态融合说成万能答案,而是把每种拼法背后的代价摊开。上车系统最怕的是只在论文指标里赢,到了真实道路上却被成本、标定、延迟和安全打回原形。
从车端到路侧:多模态检测下一步往哪走?
如果把 2017 到 2025 年的方法谱系连起来看,自动驾驶多模态 3D 检测正在从“车端多传感器融合”走向“跨模态、跨视角、跨主体协同”。这条路线会让感知系统更强,也会让工程问题更硬。
第一条方向是更高质量的跨模态对齐。Camera 和 LiDAR 的坐标系、分辨率、时间戳和噪声模式都不同。未来模型要解决的是稳定对应关系,让不同模态在 BEV、3D query 或语义空间里真正对齐。
第二条方向是雷达价值回归。毫米波雷达长期被认为精度不如 LiDAR,但 4D Radar 数据集、Radar-LiDAR 蒸馏、Camera-Radar BEV 检测正在改变这个判断。对量产车来说,Radar 的成本和天气鲁棒性决定了它不会只是配角。
第三条方向是协同感知。路侧摄像头、V2X 和车车通信能看到单车看不到的遮挡区域。问题是,通信带宽和时延会直接影响检测可信度。一个晚到 100 毫秒的外部目标框,在高速场景里可能已经不再安全。
第四条方向是部署友好的融合。论文提到的轻量网络、剪枝、量化、传感器预处理、ROI 裁剪、动态传感器管理,本质上都在回答同一个问题:如何让“传感器拼图”不把车端算力拖垮。未来有价值的方法,应该同时报告精度、FPS、功耗、硬件平台和极端天气表现。
Armor三问
问 1:Camera-LiDAR 已经这么强,Camera-Radar 还有必要吗?
有必要。Camera-LiDAR 更像高精度方案,Camera-Radar 更像量产友好方案。Radar 的速度信息、低成本和全天候能力,在雨雾、夜间和动态目标场景里很难被替代。它的问题是分辨率和小目标表达,所以更适合与图像语义、BEV 表示和蒸馏方法结合。
问 2:跨模态交互是不是一定比普通融合更好?
不一定。跨模态交互提高了信息交换能力,但也带来更多计算、更多标定依赖和更多时延风险。如果车端平台算力有限,晚期融合或轻量深度融合可能更稳。工程判断要看目标场景,而不是只看方法名字。
问 3:这篇综述对毫米波雷达方向最大的提醒是什么?
雷达的价值正在从“低成本补充传感器”变成“恶劣天气和动态目标的关键模态”。但雷达要进入高精度 3D 检测主线,必须解决角分辨率、虚警、稀疏点云和跨模态对齐问题。4D Radar 数据集和 Radar 蒸馏会是后续重点。
Armor测评
学术 / 科研价值:★★★★☆
这篇综述的学术价值在于重新整理了多模态 3D 目标检测的分类体系,把 Camera-LiDAR、Camera-Radar、LiDAR-Radar、三模态融合和跨模态交互放在一套框架下比较。它覆盖 300 多篇文献,并把 2017 到 2025 年方法演进、主流数据集和指标体系放到一起,对新进入这个方向的研究者很有参考意义。
工业 / 工程价值:★★★★☆
工程价值主要来自性能表和约束分析。论文没有只看 mAP,而是同时讨论 FPS、恶劣天气、长距离检测、嵌入式部署、功耗、传感器安装和协同感知。对做自动驾驶感知选型的人来说,这比单篇算法论文更接近真实决策。
商业 / 产品价值:★★★☆☆
商业价值取决于读者是否需要做传感器方案判断。综述本身不提供可直接落地的新模型,但它能帮助团队判断 Camera-LiDAR、Camera-Radar、4D Radar 和 V2X 感知各自适合什么产品阶段。对量产辅助驾驶来说,Camera-Radar 和轻量融合部分尤其值得关注。
可能的问题:
作为综述,它没有提出新算法,也没有统一复现实验。表 3 汇总了不同论文在不同数据集、验证集或测试集上的结果,横向比较时需要谨慎。部分方法缺 FPS,硬件平台也不统一,所以不能把表中数字直接理解成严格公平的工程排名。此外,论文对 4D Radar 的未来价值点到了,但受限于公开数据和成熟方法,分析深度还不够。
主要参考文献
Peng Zhang and Xin Lin. (2026). Multi-Modal 3D Object Detection in Autonomous Driving: A New Survey. International Conference on Multimedia Retrieval 2026. https://doi.org/10.1145/3805622.3810700
以上内容为论文阅读解读,不构成自动驾驶系统选型建议。对多模态感知、毫米波雷达和自动驾驶 3D 检测感兴趣的朋友,欢迎关注 Armor知道公众号!
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
