理想MindVLA 最核心的亮点,就是把 V(空间智能)、L(语言智能)、A(动作策略)这三大块彻底重构,搞成了三位一体的统一架构 —— 不再是各自为战的零散模块,而是串成一条线的 “统一大脑”。
先说说输入层面,还是摄像头、激光雷达、自车姿态、导航这些数据,但处理路径完全变了:所有信息都往一条统一的串行流程里走。第一步是V 模块(空间智能),所有传感器输入先进这里,通过 3D Tokenizer 处理,把 3D 场景理解透,还做成 “令牌化” 的形式;接着这些 “3D 场景令牌” 会送到 L 模块(语言智能),核心就是理想自研的 Mind GPT 大模型,专门基于 3D 视觉信息做推理决策;最后 L 模块输出的 “决策令牌” 再给到 A 模块(行动策略),靠 Collective Action Generator(比如 Diffusion 扩散模型)生成最终的行驶轨迹。这架构最绝的地方就是 “无缝衔接”,信息从 V 到 L、再从 L 到 A 顺顺当当,整个系统能端到端联合优化,既兼顾了强大的空间和语言推理能力,又实现了行为的集体建模与对齐。
一、V 模块革命:从 BEV 到 3D 高斯建模,彻底告别 “栅格” 束缚
为啥非要搞这场革命?还不是因为传统BEV 有硬伤 , 又离散又容易丢信息,计算量还大得吓人,实在跟不上高阶自动驾驶的需求。
而3D 高斯建模(3DGS)这技术,简直是颠覆性的存在!它直接把 “栅格” 那套扔了,不搞连续世界的离散化,而是换了个新思路:用数百万个 tiny 的、连续的、还能微分的 “高斯球”,把 3D 场景给建模出来。每个 “高斯球” 都带着精准的位置、形状(是椭球哦)、颜色和透明度信息,把这些球一渲染,就能以超高保真度和效率,还原出逼真的 3D 场景,这可比 BEV 靠谱多了。
V 模块的完整工作流程,一步步拆给你看:
第一步,先做多源输入融合与特征提取。系统会先接收各种数据—— 既有摄像头的多视图、多帧图像(比如 T、T-1、T-2、T-3 这些时刻的)、激光雷达的点云这种高维感知数据,也有车辆定位、自车姿态、导航信息这类低维状态数据。然后这些数据会分两路并行编码:高维数据送进强大的 3D Encoder(就像 GaussianAD 里展示的,多帧图像会先过 CNN+FPN 提取多尺度特征),低维数据就交给一个相对简单的 Encoder。重点是,3D Encoder 不只会处理当前帧,还会结合历史帧信息,把蕴含时空上下文的 3D 特征提取出来;低维 Encoder 则输出车辆自身状态和目标相关的特征,不过这两路特征这会儿还不着急融合。
第二步是核心操作—— 高斯中心场景重建,这可是整个流程的灵魂。一开始会先做 “高斯均匀初始化”,说白了就是在 3D 空间里 “撒” 一堆随机的初始高斯球(看起来就像彩色点云)。接着这些初始高斯球会进入一个迭代优化循环,要重复 B 次哦。每次循环都有两个关键操作(对应论文里的 Gaussian Encoder):一个是 4D Sparse Convolution,用来处理高斯球之间的时空交互,让模型能看懂场景的动态变化和高斯球之间的关联;另一个是 Deformable Cross-Attention,会把第一步里 3D Encoder 输出的 3D 特征当成核心输入,把多帧图像提取的视觉特征融入每个高斯球,做交叉注意力计算。经过 B 次自监督学习的迭代优化后,每个高斯球的参数(位置、形状、颜色、透明度、语义)都会被慢慢打磨好,最终形成一个统一、高保真的场景表示 —— 不再是离散的框或栅格,而是数百万个优化后的 3D 语义高斯球组成的 “数字孪生世界”,想想还挺酷的。
第三步,聊聊这波操作的优势和实际应用。首先是自监督的优势,这个核心的场景表示是靠数据自身的信息(比如多视图图像的一致性)学出来的,不用依赖昂贵的人工3D 标注,大大降低了成本。其次,这个 “稀疏但全面” 的 3DGS 表示,直接取代了传统流程里那些离散、丢信息的中间步骤(比如显式的 3D Boxes 和 Map 构建)。而且它能直接用在下游任务上:比如通过专门的 Flow Head 预测每个高斯球未来的位移(也就是高斯流),直接搞定未来的场景表示(T+1、T+2、T+3),把整个场景(包括动静元素)的演化都建模清楚;规划模块则能基于对当前和未来 3D 场景的深刻理解,直接生成驾驶轨迹。当然,也能选择性解码出传统输出当辅助 —— 比如通过 Gaussian-to-Voxel Splatting 转换成密集体素特征,用于 3D 占用栅格;把高斯当 “语义点云”,经 3D Sparse Convolution 和 Sparse Max-Pooling 处理,输出 3D 包围盒、矢量化地图元素;也能用 Self-Attention 处理高斯表示,预测特定物体的运动状态。
第四步,是连接V 模块和 L 模块的关键 —— 最终投影与 Token 化。V 模块的最后一步,就是把信息顺利传给下游的 L 模块,而 3D Projector(3D 投影器)就是这个 “接口”。它会同时接收两路输入:一路是高维路径来的 3D 特征(也就是第二步生成的高保真场景表示),另一路是低维路径 Encoder 的输出(代表车辆自身状态和导航目标)。之后 3D Projector 会把这两路信息融合,再把这个高维、连续的表示 “投影” 或者说 “Token 化”,变成 L 模块(比如 Mind GPT)能看懂、能处理的格式(比如一系列嵌入向量或 Token)。
总结下V 模块的革命逻辑:先并行处理多源传感器输入,靠 3D Encoder(用 4D 稀疏卷积处理时序)提取高维 3D 特征和低维状态特征;再用 3D 特征和初始随机高斯球,通过包含 4D Sparse Convolution 和 Deformable Cross-Attention 的自监督迭代优化循环,生成连续、高保真的 3D 高斯场景表示,取代传统的多阶段离散感知管道;最后把这个 “3D 数字孪生世界” 和车辆自身状态特征融合,通过 3D Projector “翻译” 给 L 模块,为后续的 3D 空间推理、未来场景预测和规划打下坚实基础。
二、L 模块革命:从 “拿来主义” 到 “从零自研”,打造专属驾驶大脑
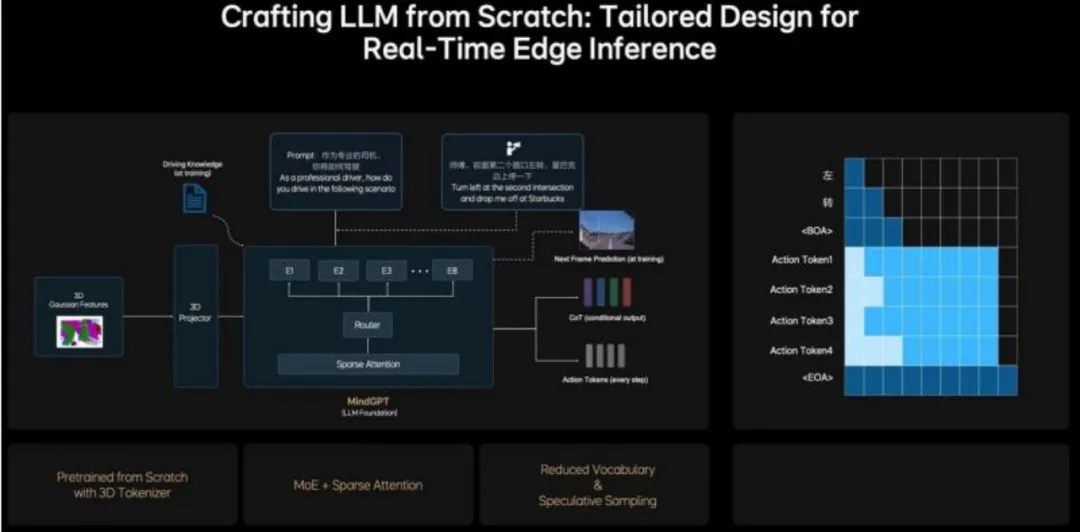
理想这次是真下血本,不搞现成的大模型“拿来就用”,而是 “从零开始打造 LLM”,还专门为 “实时边缘推理” 做了量身定制 —— 最终的产物就是 Mind GPT。从 Tokenizer(3D 高斯特征)到架构(MoE + 稀疏注意力),再到解码方式(Parallel Decoding),全都是全新设计,就为了适配自动驾驶的需求。
革命点一:天生懂3D,专为驾驶场景训练
MindVLA 的 “大脑” 可不是先学 “说话”,而是先学 “看懂空间”,这一点太关键了。传统 LLM 的 “词汇表” 是一个个单词(比如 apple、car),但 Mind GPT 的 “词汇表” 是 “高斯预训练的 3D Tokenizer”—— 说白了,它用来 “思考” 的基本单元,直接就是 V 模块经 3D Projector 处理后输出的 “3D 高斯特征”。它的 “母语” 天生就是 3D 空间,而不是 2D 文本,这和传统 LLM 完全不是一个路子。
再看训练任务,传统LLM 练的是 “完形填空” 或者预测下一个单词(比如 “今天天气很___”),但 Mind GPT 练的是 “未来帧预测” 和 “GoT(条件输出)”。这就逼着模型不能只靠 “记忆”,而是要真正 “理解” 世界的物理因果律 —— 它必须搞明白:“如果我(自车)以这个速度开,旁边那辆车的 3D 高斯特征这么变化,那‘下一帧’的 3D 高斯特征应该是什么样?” 靠着这种原生 3D 输入和面向物理的训练任务,Mind GPT 在预训练阶段,就拿到了传统 LLM 没有的两大核心能力:超强的 3D 空间理解能力和深刻的时序推理能力。
而且Mind GPT 还会模仿人类的思维模式,能自主切换 “快思考” 和 “慢思考”:慢思考的时候,会输出精简的 CoT(用固定的简短 CoT 模板),再给出 action token;快思考的时候,就直接输出 action token,效率超高。
革命点二:适配车端芯片,架构设计太懂行
要让大模型在车端顺畅运行,算力是大难题,而Mind GPT 的架构设计正好解决了这个问题 —— 核心就是 MoE(混合专家)+ 稀疏注意力(Sparse Attention)。就像图里展示的,当一个 “3D 高斯特征” 输入进来,首先会经过一个 “路由器”。这个路由器特别智能,会判断这个任务该交给哪个 “专家”(比如 E1、E2 到 E8)来处理:比如和 “刹车” 相关的 Token,可能就分给 “E1 刹车专家”;和 “变道” 相关的,就交给 “E3 变道专家”。这样一来,每次推理的时候,只有一小部分专家(比如 2 个)被激活,不是整个庞大的模型都在运转,用 “稀疏激活” 换来了极高的推理效率,完美实现 “低算力跑大模型”。
还有个“杀手锏” 是并行解码(Parallel Decoding),这是实现实时动作输出的关键。传统 LLM(比如 ChatGPT)生成文本是自回归的,一个字一个字往外蹦(比如 “我 - 今 - 天 - 很 - 高 - 兴”),慢得不行。但 Mind GPT 分清了 “思考” 和 “行动”:需要输出 “思维链”(CoT)解释的时候,能慢慢 “蹦” 字;但要输出动作(Action Tokens)的时候,就用并行解码 —— 转向、油门、刹车这些 Action Token,在一个步骤里同时生成,不是挨个来,这大大压缩了动作生成的时间,刚好满足 30Hz 实时响应的要求,这波工程优化太到位了。
可以说,Mind GPT 就是一个天生懂 3D、会推理,还为车端芯片深度优化的 “驾驶大脑”,再也不是之前 “快慢双核” 里那个笨拙、缓慢、只会 “说教” 的 VLM,而是真正高效、统一的 “决策核心”。
三、A 模块革命:从 “轨迹点” 到 “Diffusion 策略”,驾驶动作更智能
优势一:轨迹超丝滑,堪比老司机的“拟人化” 操作
Diffusion 模型最擅长的就是生成连续、平滑还带 “风格化” 的输出,用到驾驶轨迹上简直绝配!它生成的轨迹,再也不是冷冰冰的、由直线和圆弧凑出来的 “机器轨迹”,而是特别精细化、高度 “拟人” 的平滑轨迹。
理想的工程师打了个特别形象的比方,这就像经典的“旋轮线”(最速降线)问题:传统规划器可能找个 “代数函数”(比如一条斜线或抛物线)凑活,能走但颠簸得很;而 Diffusion 模型能找到物理上最优的 “旋轮线”,这才是安全、效率和乘坐舒适度(比如 G 值)都拉满的 “黄金轨迹” 啊!
优势二:从“被动反应” 到 “主动博弈”,懂预判才够强
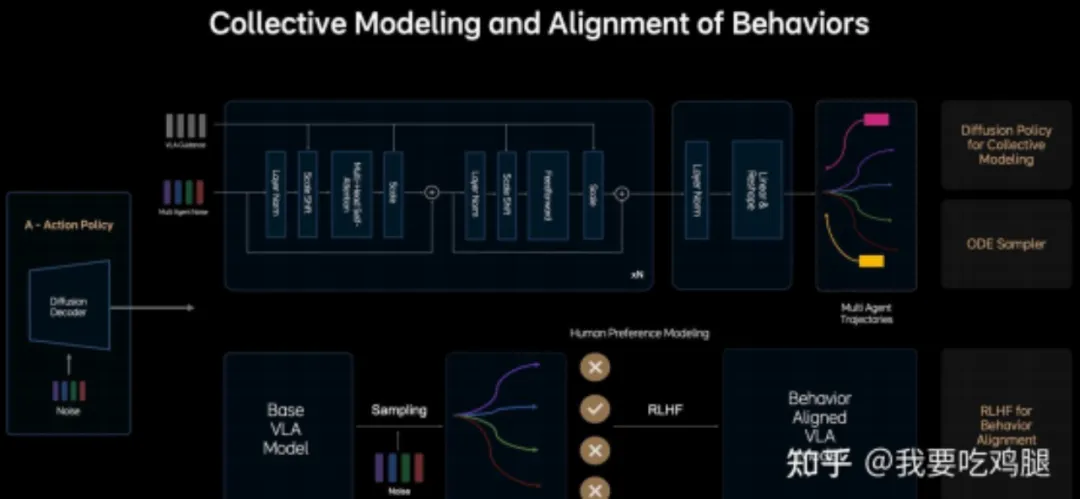
MindVLA 的 A 模块可不止规划自车该怎么走,它玩的是更高级的 “行为的集体建模”(Collective Modeling and Alignment of Behaviors)。输入端就很不一样,核心处理模块(带 Multi-Head Self-Attention 的 Transformer 结构)不仅接收代表自车意图的 “VLA Guidance”,还会接收 “Multi-Agent Noise”—— 说白了,就是模型对环境中其他关键智能体(比如旁边的车、前面的行人)未来行为不确定性的一种表示或采样。
模块内部的Multi-Head Self-Attention 结构,能让它联合建模自车意图和其他智能体潜在行为的复杂交互 —— 不再是孤立规划自车,而是在同一个空间里,同时考虑 “我” 和 “他” 的未来可能性。最关键的是,它最终输出的不是单独的自车轨迹,而是 “多智能体轨迹”(Multi Agent Trajectories):生成自车最优轨迹的同时,还会同步预测和生成周围车辆、行人最可能的轨迹。
这就实现了从“反应式” 到 “博弈式” 的进化:简单的 “反应式” 系统就像新手司机,只盯着前车,“他刹车我才刹车”“他变道我才减速”,没什么预判,复杂路况下很容易慌神;而 MindVLA 的 “博弈式” 系统,就像经验丰富的老司机,会预判、会博弈 —— 比如 “我猜那辆车可能要往我这边变道,那我提前稍微减速,再往右打一点方向,给他留足空间”,这种前瞻性规划,安全性和舒适度直接拉满。
关键突破:ODE Sampler 让 Diffusion 模型 “快起来”
Diffusion 模型虽强,但有个致命弱点:慢!标准的 Diffusion 要成百上千步 “去噪” 迭代才能生成结果,可自动驾驶的控制循环必须在 30Hz(大概 33 毫秒)内完成,这要是按标准流程来,根本来不及。
还好理想的工程师搞出了工程突破:用“基于常微分方程的 ODE Sampler”(ODE 采样器)。这个采样器把 Diffusion 的生成过程加速太多了,不用成百上千步,大概 2 到 3 步就能让轨迹 “收敛”,正是这个突破,才让 Diffusion 这种 “AIGC” 技术,终于能塞进自动驾驶的实时控制循环里。
到这儿,MindVLA 通过 V、L、A 三个模块的彻底革命,已经建成了一个能看懂 3D 世界、会深度思考、还能生成完美动作的 “统一大脑”。但还有个终极问题:这个 “大脑” 生成的动作,怎么确保安全、舒适,还符合人类的价值观呢?这就得看后续的优化和验证了,但单就目前的技术架构来看,MindVLA 确实给自动驾驶带来了不少新可能。
扫描下方二维码,添加智驾派小助理微信,免费领取以下材料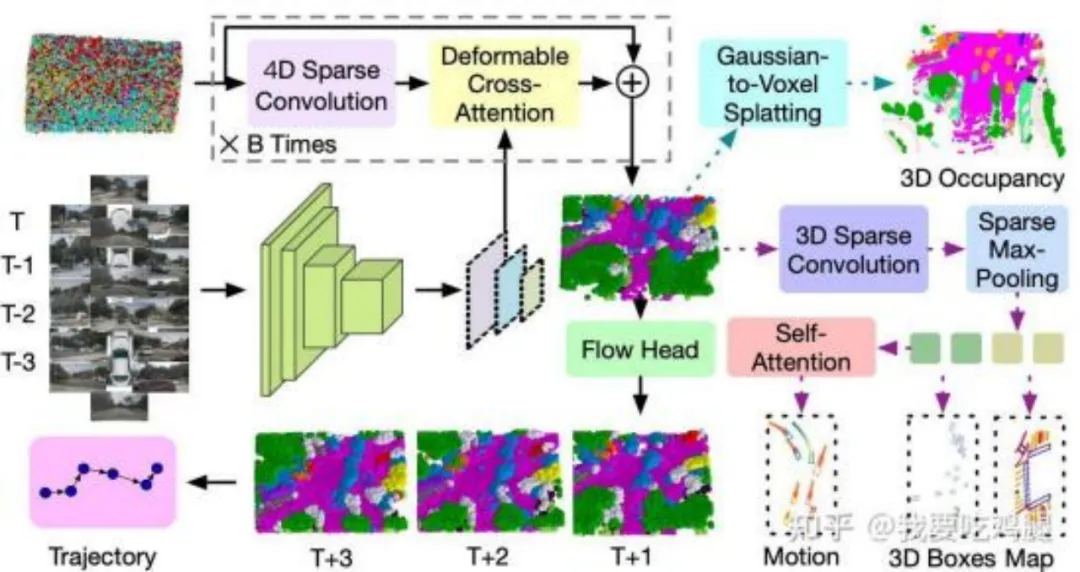



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
