一、大模型如何赋能自动驾驶?
(原创 三丫头 AI电堂)
“忽如一夜春风来,千家万户端到端。”这句调侃清楚地表明了自动驾驶行业玩家们对端到端技术路线的认可和追捧,但是,端到端绝非自动驾驶行业唯一的热词,随着理想汽车端到端+视觉语言模型双系统方案的发布,关于大模型的讨论开始慢慢浮出水面。
鉴于在当下这个阶段,端到端提升自动驾驶性能的幅度更大、更明显,苦苦争夺流量的车企们也不想让大模型这个引发第四次工业革命的概念分散大家的注意力,削弱对端到端的传播力度,所以,和声势浩大的端到端营销形成鲜明对比的是,几乎所有选手在自动驾驶大模型的宣传上都保持了难得的低调。一向稳居其它行业营销C位的大模型到了自动驾驶行业主动退居次位,成了映衬端到端这朵红花的绿叶。
理论上来说,大模型对于自动驾驶的加持既可以体现在云端,也可以体现在车端。在云端,它可以加速自动驾驶算法的开发和验证,在车端,它可以提升自动驾驶系统的性能表现。不过,对于还没有实现全链路端到端方案阶段的本土车企来说,端到端自身的潜力还有很大的挖掘空间,在局面不明朗的情况下,似乎没有必要分散资源研发在车端部署运行的大模型。目前,除了理想汽车孤注一掷地在车端部署视觉语言模型之外,几乎所有其它友商都只是拿大模型来赋能自动驾驶的开发闭环。
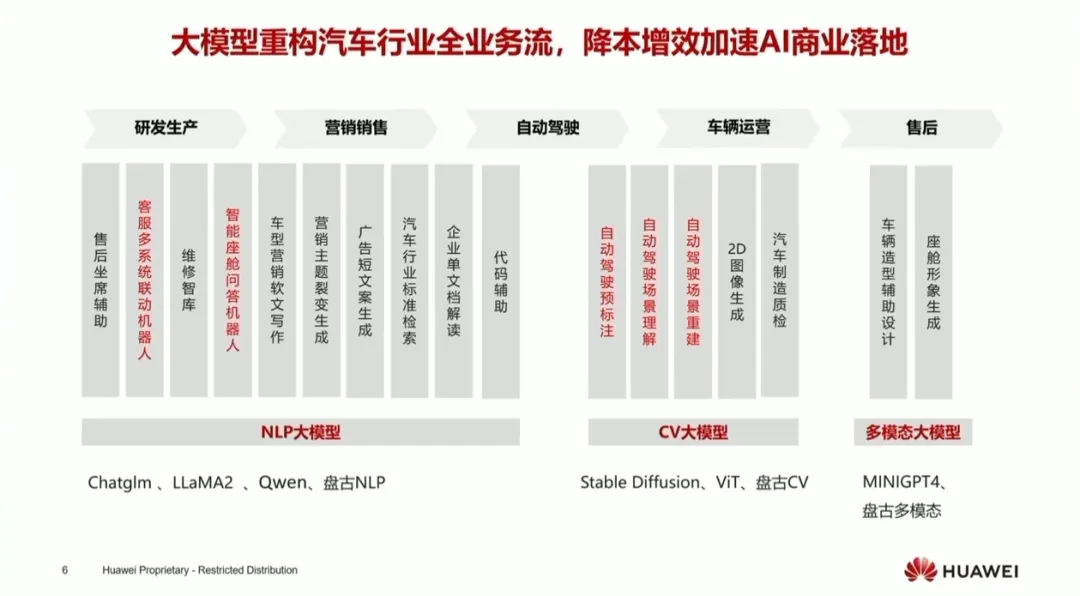
有鉴于此,本文结合实际,谈一谈云端大模型是如何全面赋能自动驾驶算法开发的。 随着大模型技术的进步及其在垂直领域的探索,大模型对自动驾驶的赋能程度也在逐渐加深。4月份的第2届汽车人工智能大会上,华为介绍了以大模型重构汽车行业全业务流的实践,根据华为的总结,在自动驾驶业务上,大模型可以用来实现预标注、场景理解和场景重建。
▲ 图片来源:华为
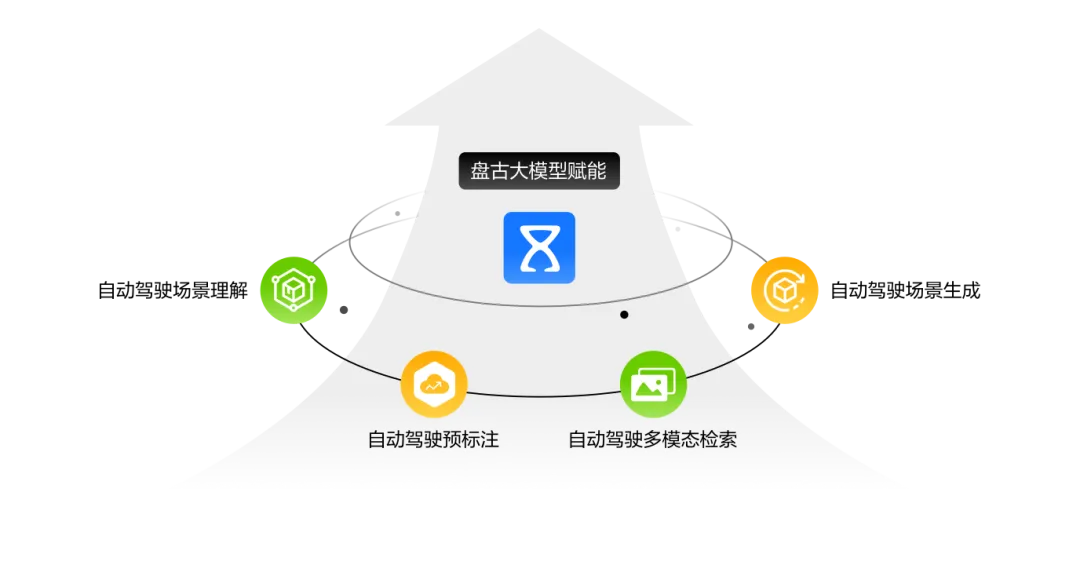
到了6月的开发者大会上,华为正式发布面向千行百业的盘古5.0大模型,参数规模横跨10亿级到万亿级,面向自然语言处理、科学计算、机器视觉、多模态理解和生成、分析预测等各个细分领域。具体到自动驾驶领域,盘古大模型的赋能作用升级,体现在四个方面:预标注、场景理解、多模态检索和场景生成。其中,预标注可以实现2D/2.5D/3D视角下的数据标注,场景理解可以代替人工打标签分类,多模态检索支持以文搜图和以图搜图,用于准备训练数据集,基于NeRF的场景重建和基于AIGC的场景生成用于构建仿真场景,给自动驾驶模型“出考卷”。
▲ 图片来源:华为
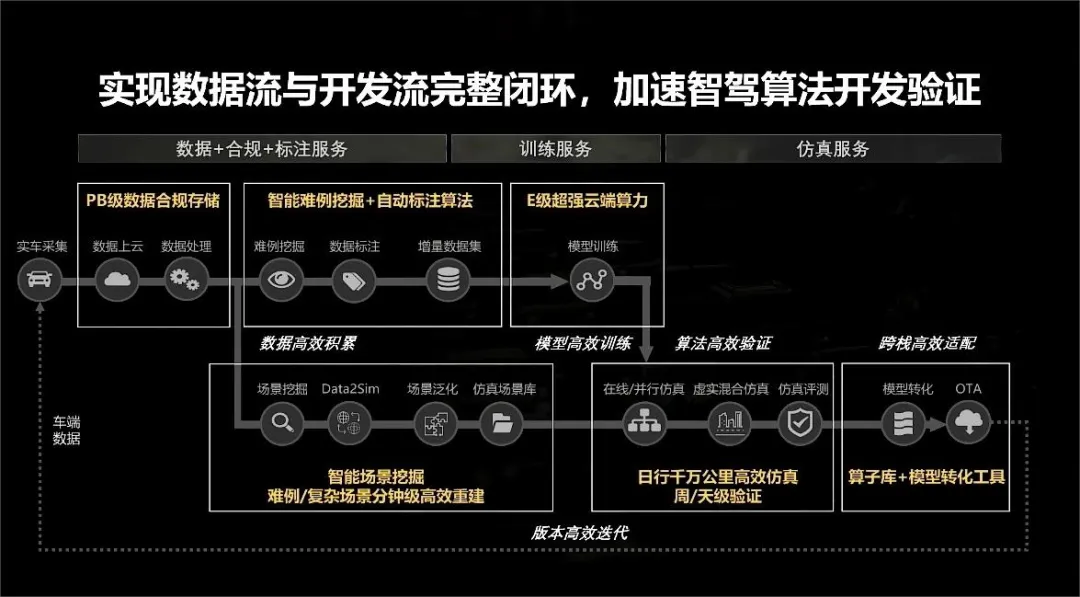
在进一步阐述大模型的作用之前,有必要先拆解一下自动驾驶数据闭环和开发闭环到底分成哪些阶段。
如果以模型训练作为自动驾驶开发流的中间节点,可以把自动驾驶业务流简化成训练前、训练和训练后三个阶段,展开一下,可以把它们划分成数据预处理、数据标注、模型训练、仿真和评估、模型部署5个阶段。将大模型的作用对应到自动驾驶算法开发闭环和数据闭环,可以认为,预标注、场景理解、多模态检索用于模型训练前的数据准备,场景重建和场景生成用于模型训练后的仿真和验证。具体的,场景理解和预标注用于模型训练之前的数据自动标注,通过大模型提高驾驶场景数据的处理速度,实现精标数据集的高效积累;多模态检索用于模型训练之前的场景挖掘;场景生成包括基于真实道路数据的场景重建和基于AIGC的场景生成,重建或生成模型训练前的训练数据集、模型训练中的验证数据集和模型训练后的测试数据集。
通过收集包括各种道路状况、交通标志、人车物以及不同天气、光照条件下的大量多模态数据(激光雷达、毫米波雷达、摄像头采集的数据),利用深度神经网络进行无监督预训练,再在包括多模态数据和文本描述的数据集上进行有监督微调,大模型可以学习到驾驶场景中文本和图片模式的关联,建立起对驾驶场景的理解能力。
▲ 图片来源:理想汽车
有人认为,目前的大模型技术难以精确把握自然语言的模糊性和多义性,基于概率模型的Token预测缺乏真正的创造性思维,所以不具备准确的推理和理解能力。他们的话也许有一定的道理,不过,具体到自动驾驶场景理解上,训练了经过精确标注和描述的上亿张图片和点云数据的大模型,可以通过紧密相连、互相支持的连贯性启发式联想“看图说话”,有效地综合多传感器信息理解场景中的复杂模糊语义,并给出对驾驶场景的精准描述。
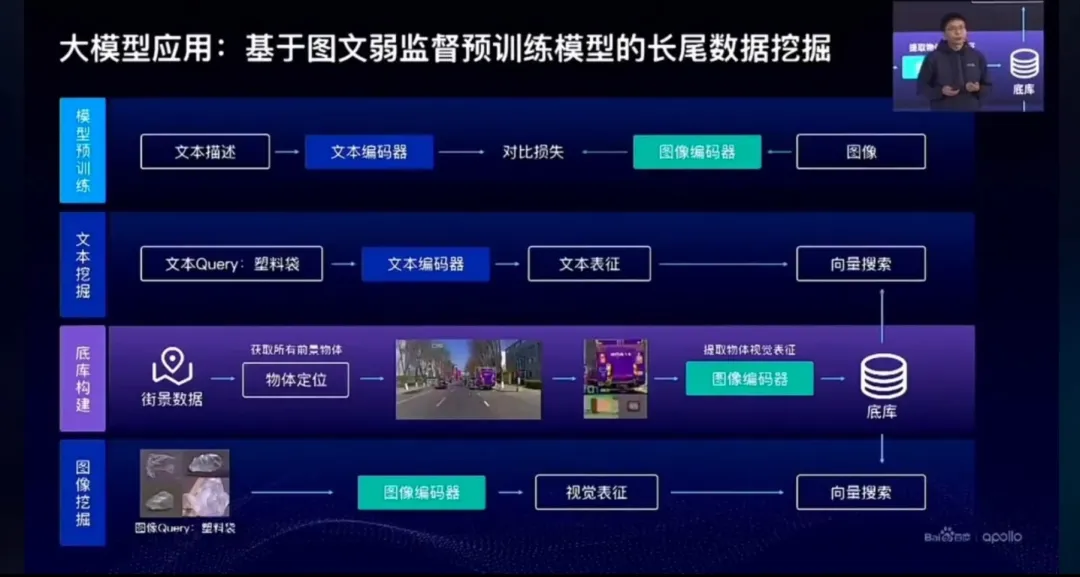
场景挖掘的目的是通过文本的方式进行长尾场景和难例的挖掘,迅速构建用于模型训练、验证和测试的数据集。由于全量训练的成本太高,自动驾驶模型的迭代注定是一个增量学习的过程,通过场景挖掘迅速收集新的、未被充分覆盖的驾驶场景,能够以最小的成本、最快的速度优化和改进自动驾驶系统的性能。在2022年的阿波罗日上,百度曾经分享过基于图文弱监督预训练大模型进行长尾数据挖掘的实践。
▲ 图片来源:百度
如果把场景理解视为从图像模态到文本模态的映射,那么,场景挖掘便是从文本模态映射到图像模态,在这个角度上,场景理解和场景挖掘存在辩证性的对立统一。 自动驾驶算法正处于判别式AI模型为主、生成式AI模型为辅的阶段。判别式AI模型的训练离不开数据的精确标注,生成式AI模型对大规模精标数据的依赖度有所降低,但同样需要在模型训练初期通过标注数据提供一些先验知识,帮助模型更快地学习数据中的特征和模式。所以,数据标注是自动驾驶模型训练的必要前置工作。
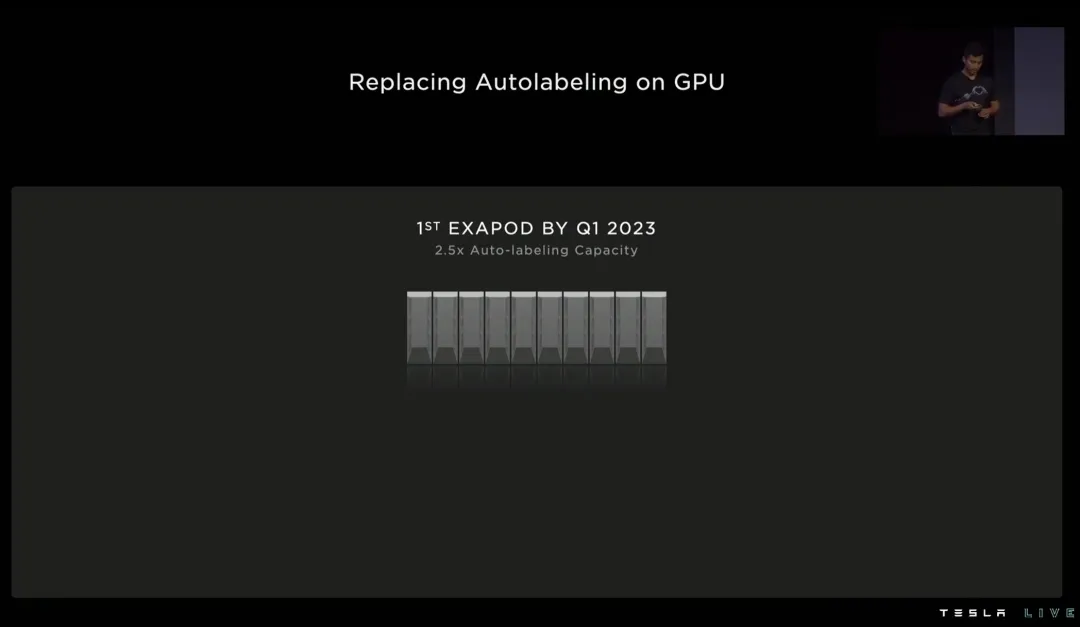
业界一般通过自动为主、人工为辅的工具和系统节省标注时间、提高标注效率。自动标注的原理是通过深度学习模型从大量已标注的数据中学习目标的特征和模式,然后将学习到的这种能力用在新的数据上自动进行标注。自动标注可以大幅度节省人力,但极其消耗算力,特斯拉构建的第1台Dojo就是供数据自动标注使用的,据悉,这台超级计算机的算力高达1.1EFLOPS。
▲ 图片来源:特斯拉
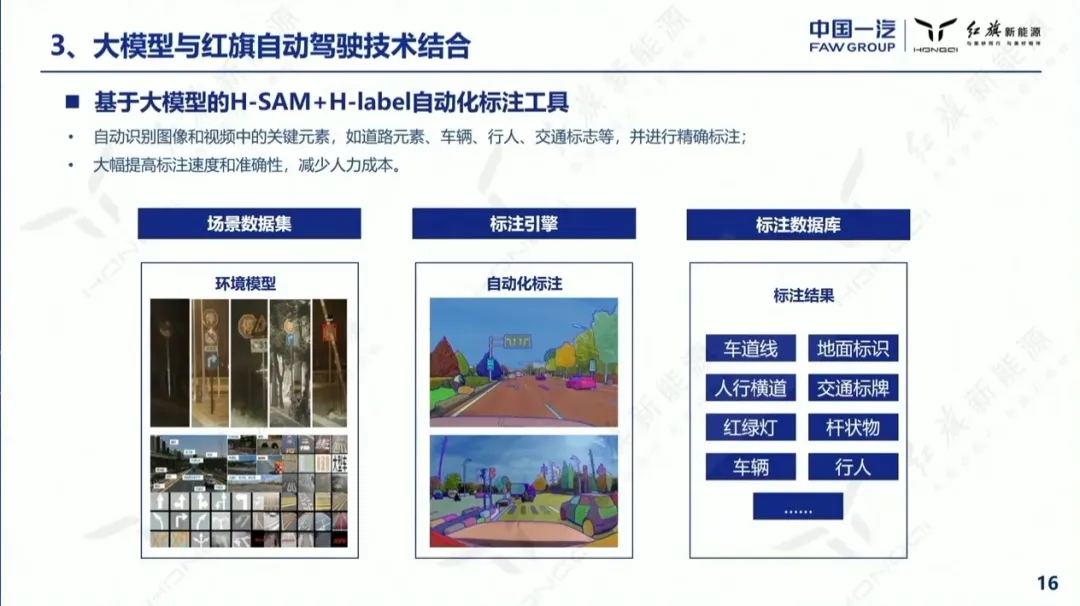
数据自动标注涉及计算机视觉、图像处理、生成式AI等多种技术和算法,是一个综合性的系统工程,具备超强理解能力的大模型的出现简化了自动标注的流程,提高了自动标注的效率。不过,大部分车企和方案供应商其实并不具备大模型的开发能力,而且,数据自动标注大模型在训练阶段需要海量的算力来支持大规模数据处理和复杂模型结构的优化。为了绕开大模型开发能力和算力的难关,业界一般秉持拿来主义的原则,直接使用开源基础模型或者在这些模型的基础上做一些简单的微调。比如一汽红旗将Meta开源的SAM大模型包装成H-SAM,自动识别并精确标注图像和视频中的道路元素、车辆、行人、交通标志等关键要素,大幅度提高了标注的速度和准确性。
正如学生们上完一个学期的课程之后,需要通过期末考试检验学习成果一样。模型训练完成之后,也需要构建仿真场景,验证模型的能力。
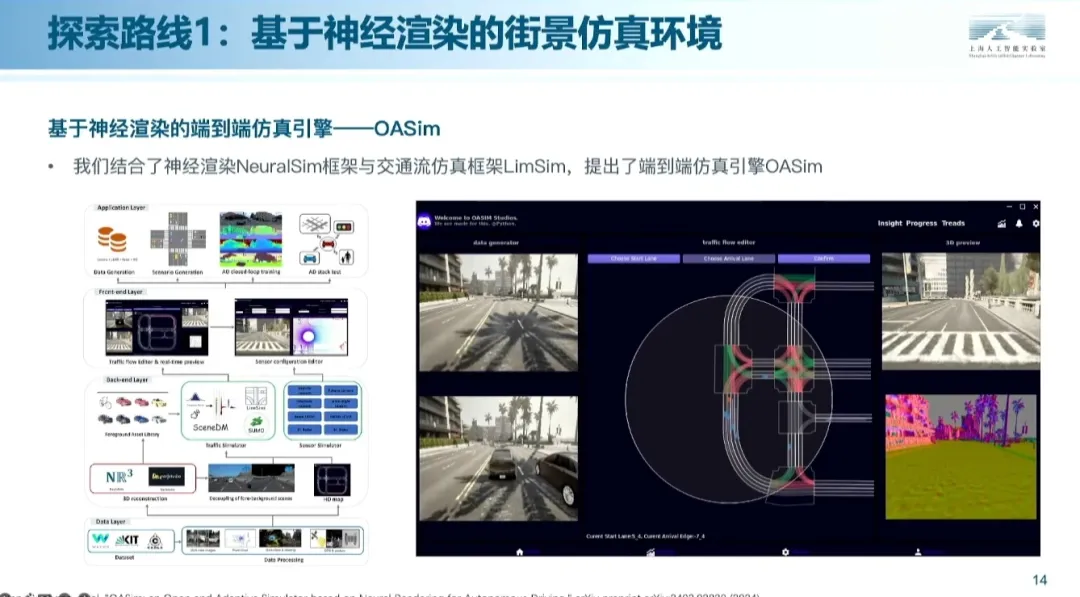
在大模型出现之前,业界一般利用车端采集的实际数据提取图结构表征,基于NeRF技术或3D高斯溅射进行道路背景和交通要素的重建。
▲ 图片来源:上海人工智能实验室
大模型出现之后,仿真场景构建又多了一条可行的技术路线-通过生成模型直接生成可控的仿真场景,来弥补实车数据重建难以复现罕见Corner case的不足。华为的盘古大模型可以通过文本形式的提示词,控制不同光照和天气条件下的视频生成。
▲ 图片来源:华为
大模型赛道的最大赢家、自动驾驶行业的标杆企业英伟达构建了自动驾驶汽车基础模型,可以通过文本描述,生成各种天气、光照、路面下的驾驶场景。
▲ 图片来源:英伟达
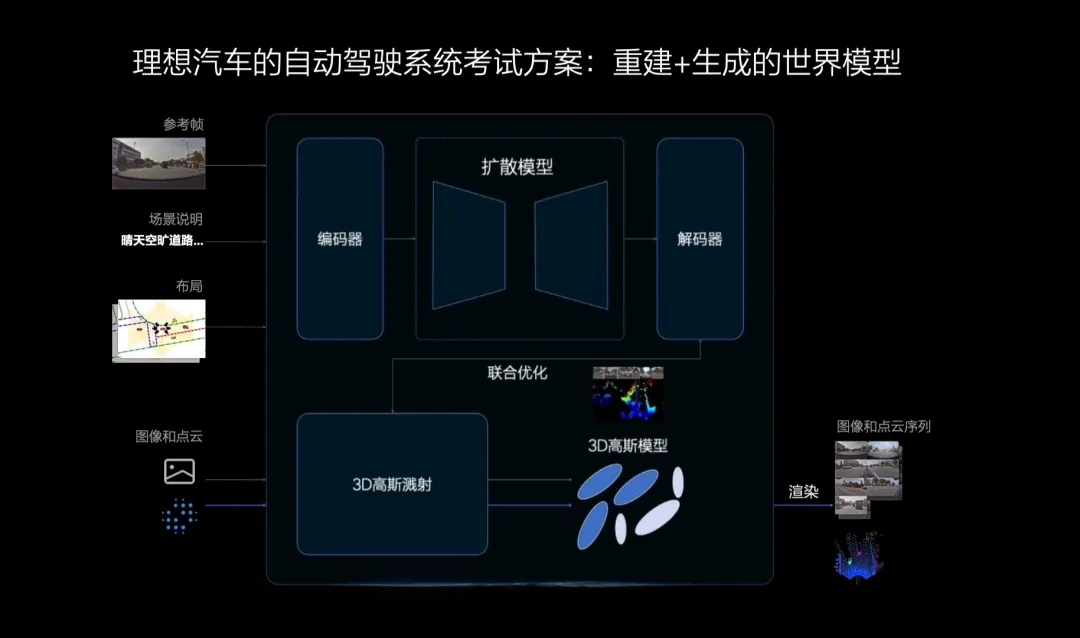
为了保证场景的一致性和连续性,业界还在探索场景重建和生成技术相结合的方式来构建仿真场景。理想汽车的世界模型便是结合了“重建+生成”的自动驾驶系统考试方案。一方面,它可以通过3D高斯溅射技术对来自摄像头和激光雷达的图像和点云数据进行重建和泛化,另一方面,可以通过扩散模型进行文生图和图生图,两相结合,最终渲染出一段时间内的图像和点云序列。
目前,大模型对于自动驾驶的真正价值主要体现在云端。不过,包括蔚来、小鹏、理想在内的头部智驾车企都在探索如何将大模型技术应用于车端的自动驾驶算法里面。理想汽车的双系统方案拿出一整颗Orin X芯片运行视觉语言模型,蔚来汽车正效仿特斯拉,以世界模型赋能端到端,力图将传统端到端方案改造成天生具备端到端结构的世界模型。小鹏汽车XNGP中的XBain也使用了大语言模型的能力。
或许,在将来的某一天,随着算力的升级和模型的迭代,大模型真的可以在车端重构自动驾驶技术栈,把高阶辅助驾驶推进到全自动驾驶的阶段。
二、赋能自动驾驶,大模型是真旺还是虚火?
(原创 张奕雯 中国汽车报)
“万物皆可大模型”成为今年各个产业都逃不开的话题。
年初以来,能够代写论文、写报告甚至写新闻的 ChatGPT ,彻底引爆了社会各方对大模型的关注。在大众纷纷担心自己是否会被AI所取代时,自动驾驶产业已经瞄准大模型的商业价值,纷纷推出大模型。近日,理想汽车在理想家庭科技日发布会上宣布,理想采用大模型算法,自研MindGPT。多方吹捧的大模型,能否为自动驾驶产业带来“第二春”?
大模型成新宠
“自动驾驶技术正进入以数据和知识双驱动的多模态感知和认知理解为代表的新阶段。” 中科院雄安创新研究院认知智能实验室副主任黄武陵 在接受《中国汽车报》记者采访时表示,大语言模型(LLM)、跨模态大模型的出现,为自动驾驶产业的发展带来突破口。目前,行业对大模型的定义是只有在参数达到千亿以上才能够被称为大模型。当AI模型足够大,经过不断地训练与学习,就有可能实现智能化。因此,被看作能够改变世界的大模型,成为自动驾驶的新希望。
在数据闭环和仿真环节,大模型将赋能自动驾驶。 商汤科技 联合创始人、首席科学家王晓刚 表示,在人工智能1.0时代,大量的人工标注导致数据标注时间长、成本高、挖掘难度大。但在人工智能2.0时代,基于大模型可以实现自动标注,大大降低成本,可快速进行优化和迭代。另外,还可通过 AIGC 利用人工智能做内容生成,模拟生成高度真实的场景,助力自动驾驶技术更好地进行测试和优化。“在大模型的辅助下,研发人员可以更多集中在关键算法及其提升体验上,集中打磨出更多满足用户体验、效果良好的产品。”黄武陵说道。
在王晓刚看来,多模态大模型的应用还可实现从感知到决策、规划、控制,端到端一体化的优化。“当前大多是感知输出一个结果,基于规则做一些判断,做出决策,然后再基于手动规则,实现规划控制。”他认为,未来大模型通过人工智能,可以实现端到端自动驾驶,提供更加可靠、像人开车一样的体验。
目前行业普遍认为,在技术方面,自动驾驶的底层架构和大部分技术问题已得到解决,但由于现实道路场景复杂,即便现有技术已实现90%以上场景的自动驾驶,剩下10%的长尾场景始终无法覆盖。黄武陵表示,随着大模型在垂直领域的应用逐渐成熟,成本可控且性能效率良好的前提下,大模型有望在环境认知理解、智能决策等算法功能上得到应用,将交通指示和驾驶经验得以沉淀和应用,缓解自动驾驶的“长尾问题”。
此外,大模型还能为自动驾驶“抛弃”高精地图提供助力。要想实现高级别自动驾驶,高精度地图不可或缺,但实时更新难度大、法规风险高、成本极高三座“大山”始终难以跨越。摆脱高精地图,成为不少企业的选择。随着大模型渐受关注,安信证券研报指出,AI大模型将助力企业实现“脱高精度地图”。BEV感知算法通过将不同视角的摄像头采集到的图片统一转换,相当于车辆实时生成地图,补足自动驾驶后续决策所需的道路拓扑信息,实现“脱图”。
产品接连发布
受到各界追捧的Chat-GPT,全称为“Generative Pretrained Transformer”,其采用了谷歌在2017年提出的Transformer架构。对于自动驾驶领域而言,Transformer架构则并不陌生。早在2021年,特斯拉便将Transformer架构引入自动驾驶领域,推出基于Transformer的BEV感知方案。这是大模型技术在自动驾驶行业的首次亮相,也成为特斯拉实现纯视觉自动驾驶方案的关键所在。随后,华为、商汤科技、百度Apollo等企业相继在“BEV+Transformer”上展开布局。中信证券研报指出,随着小鹏城市 NGP 、华为城区NCA功能、毫末智行城市NOH等城市领航功能的相继落地,“BEV+Transformer”将引领自动驾驶感知范式。
如今,大模型绝不仅限于自动驾驶感知领域。今年4月,毫末智行正式发布自动驾驶生成式大模型DriveGPT“雪湖·海若”。据 毫末智行首席执行官顾维灏 介绍,毫末DriveGPT通过引入驾驶数据建立 RLHF (人类反馈强化学习)技术,对自动驾驶认知决策模型进行持续优化,现阶段主要用于解决自动驾驶的认知决策问题,终极目标是实现端到端自动驾驶。顾维灏表示,毫末DriveGPT将率先探索智能驾驶、驾驶场景识别、驾驶行为验证、困难场景脱困四大应用场景,首先将开放智能驾驶、驾驶场景识别两大应用场景。
在自动驾驶领域,商汤科技开发了业界首个感知决策一体化的端到端自动驾驶解决方案——UniAD,在多目标跟踪准确率、车道线预测准确率等多项关键技术指标上超越SOTA方法,整体系统和性能得到大幅提升。“未来,我们将利用多模态大模型,进一步推动自动驾驶技术发展,如通过AIGC产生大量困难样本,用环视感知的数据,和多模态数据作为多模态大模型的输入,实现感知和决策一体化的集成。”王晓刚表示。
于不久前正式亮相的Mind GPT,则是属于理想汽车自研的认知大模型。理想现已用1.3万亿个token为其进行基座模型训练,让其对话生成、语言理解、知识问答、逻辑推理等多项能力更安全、更准确、更有逻辑。在Mind GPT的赋能下,理想汽车所搭载的智能语音助手——理想同学,将像人一样主动感知环境和他人、学习和思考、表达和互动。此外,在智能驾驶方面,理想AD Max 3.0可通过大模型AI算法,摆脱对高精地图的依赖,实时感知、决策、规划,识别准确度相当高。 理想汽车智能驾驶副总裁郎咸朋 表示:“在先进的技术架构和高效的训练平台共同推动下,智能驾驶将会很快在家庭出行中实现大规模普及,AI驾驶员替代人类驾驶员的时代也不再遥远。”
此外,百度此前也表示,要将文心一言大模型应用在自动驾驶上,以加深Apollo自动驾驶车辆对复杂城市路况的理解,进一步提升其自动驾驶安全性和可靠性。斑马智行则基于阿里巴巴通义千问大模型,打造了第三代汽车AI能力体系Banma Co-Pilot,构建云端一体的全栈AI能力。日前,特斯拉首席执行官马斯克也表示,特斯拉会迎来自己的“ChatGPT时刻”,如果不是今年,肯定也不会迟于明年。一系列大模型产品的相继发布,可见大模型在自动驾驶领域的“受宠”程度。
商业化为时过早
“目前大模型究竟能给行业带来什么影响尚不明晰,一些有能力、有资金的企业只是处于率先探索阶段,商业化还为时过早。” 全联车商投资管理(北京)有限公司总裁曹鹤 表示。
聚焦自动驾驶大模型,就此前发布的几款大模型产品究竟含金量几何, 自动驾驶行业从业者吕兆波 并没有太大信心。他直言:“DriveGPT很不现实,就算大企业投资研发,没有5~10年很难见到成果。这个大模型的概念很大,他们可能就是做一个简单的数据融合。”
在吕兆波看来,大模型的优点就是能够将各组数据融合在一起,对外界环境的感知更为准确。但是,要想使用大模型,首先就面临部署问题。“如果大模型部署在云端,延迟问题很难解决;而如果部署在车端,如此庞大的数据量,延迟问题同样不容小觑。”他说道。上不上车,成为困扰自动驾驶大模型商业化的首要问题。
对此,地平线创始人兼首席执行官余凯在参加2023中国电动汽车百人会论坛时提出,车端的能量供给与散热等现实困难,使得自动驾驶无法采用类似ChatGPT云端计算中那样庞大的模型与计算量。顾维灏在接受媒体采访时则表示,云端模型与车端模型的大小并不是完全等同的关系,目前DriveGPT参数规模已达1200亿,但并不意味着把这1200亿的参数大模型都上到车端,关键是留住核心能力。
此外,成本问题也是困扰之一。有业内人士指出,自动驾驶系统如果要上大模型,至少要增加5万美元成本,随着大模型进一步变大,成本或许会进一步增加。对此,吕兆波称,成本问题可通过云端部署解决,但前提是解决云端的延迟问题。即便是大模型自身,也认为成本问题是一大重要考虑因素。在回答“如果将ChatGPT应用到自动驾驶中,是否会成本过高?”这一问题时,Chat-GPT给出的回复表示,将ChatGPT应用于自动驾驶系统会涉及一定的成本,主要涉及计算资源、数据收集和训练、模型开发和集成等几方面。
舆论火热 资本冷静
前有创新工场董事长兼首席执行官李开复宣布筹办全球化公司Project AI 2.0,后有搜狗创始人王小川投资5000万美元成立百川智能。此前,红杉中国种子基金也表示正在密切关注并开始布局AIGC领域的早期企业。一方是资本盛宴,另一方则略显冷清。2022年以来,裁员、倒闭、关停的消息充斥自动驾驶产业,不少人感叹自动驾驶进入“寒冬期”。虽说大模型在自动驾驶领域的应用还为时过早,但不可否认,大模型的出现给正处于寒冬的自动驾驶产业重新燃起一把火。这波与大模型的联动,能让渐失热度的自动驾驶重获资本宠爱吗?
中国生产力促进中心协会常务副理事长兼秘书长、研究员王羽 认为,大模型的出现提供了一个群体性的突破机会,能够提振行业信心,重塑单车智能技术路线。不过,在汽车行业分析师邵元骏看来,尽管资本对于大模型热情高涨,但经过多年发展,资本已经认清自动驾驶产业的发展现状,不会在大模型萌芽期贸然进行大手笔投资。
据王晓刚介绍,ChatGPT这样的大模型仅训练一次便需要上千万美元的成本投入,商汤科技近几年在AI研发中已累计投入上百亿元,仅临港AIDC基础设施投入便超50亿元。动辄成百上千亿元的投入,在自动驾驶领域却很难短时间实现盈利。
“现在受经济形势影响,整个资本行业本身就面临寒冬,钱不多,出手就会更加谨慎。”邵元骏说。如此看来,炙手可热的大模型似乎也难解当前自动驾驶产业之寒。
三、实现真正的自动驾驶,需要大模型真的上车?
(汽车商业评论)
“冰箱、彩电、大沙发还是属于电动化的东西,其实真正的智能车还是要看自动驾驶的能力到底如何。” “智能驾驶很重要,但是光把智能驾驶做好,好像还不够,汽车还是非常难做的一个木桶,有一块板落水就完蛋了,其他板再长都不行。” “有可能通过明年的竞争以后,车企的竞争除了大吃小以外,还会出现快吃慢,所谓快吃慢就是OTA的频次”。 今年是NOA的落地年、爆发年,明年应该是决胜年。城市NOA有两个关键词,一是无图,用重感知,抛弃了高精度地图;二是端到端,让NOA技术性能水平急剧上升。 大模型的确可以解决深度学习模型带来的安全长尾难题(corner case)边缘场景,但是大模型的运算能力要求太高,目前是上不到车上的。 12月13日,同济大学汽车学院教授朱西产在题为《智能驾驶与城市立体交通趋势》的演讲中指出,特斯拉提出端到端以后,今年国内企业迅速跟上,一种新的AI模型(深度学习模型)的新的组装方式,就是用Transformer组装起来的端到端模型,性能水平急剧上升,所以今年3月份到6月份,NOA技术已经有了一个飞跃式的发展。但要实现真正的自动驾驶,还得大模型真的上车,要具有举一反三的推理能力。 中国汽车通过创新,在电动化和智能化方面都已经有了非常快的突破,今天我分享一下汽车智能驾驶和今年特别热的低空飞行,低空飞行域的飞行器也是汽车产业的延伸,用的产业链跟电动汽车产业链和智能化产业链一脉相承,低空飞行器肯定是电动多旋翼,这两块东西也是我们的强项。 电动化经过差不多十年左右的推动,近三年左右的高渗透率,今年一边喜,一边悲,喜的是中国的汽车通过电动化走到了世界前列,悲的是大部分企业要倒下,大吃小的现象已经发生。 智能化,从智能座舱到智能空间,随着电动化已经出现了,车上如果有20度以上的电,这个车已经可以成为生活空间了,和内燃机汽车不一样了。原来内燃机汽车是纯粹的交通工具,到了目的地肯定马上就下车,因为你不下车,发动机就得响着,否则就没电了,谁也不会在响着发动机的车里待两三个小时,受不了。发动机一断,电也没了,也没法待。 刚才孟为提到冰箱、彩电、大沙发,这些还是属于电动化的东西,其实真正的智能车还是要看自动驾驶的能力到底如何。 今年是NOA的落地年、爆发年,明年应该是决胜年。令人唏嘘的是极越,它在智能驾驶NOA领域绝对是头部企业,还未到决战就倒下了。它的智能驾驶NOA做得不错,得亏今年极越没报名,以我对驾驶这个车的感觉,十佳应该能进去的,如果能进去的话,蛮尴尬的,这边在发奖,那边倒闭了。 智能驾驶很重要,但是光把智能驾驶做好,好像还不够,汽车还是非常难做的一个木桶,有一块板落水就完蛋了,其他板再长都不行。 智能化即将成为汽车企业面临的第二个难题,是原来传统汽车行业不熟悉的芯片、人工智能,以及用户数据怎么能够快速迭代,它是OTA的迭代方式。 有可能通过明年的竞争以后,除了大吃小以外,还会出现快吃慢,所谓快吃慢就是OTA的频次,因为人工智能的产品不是开发好了以后慢慢迭代。传统汽车的开发,从最早36个月缩到18个月,有些企业可能是10个月,10个月以下再推车不实现了。通过OTA,利用用户数据,现在头部企业的OTA频次每月1.2-1.5次,意味着2个月左右就得有3次左右的迭代。 这对传统汽车企业的安全问题是一个巨大的挑战,因为这是我们不熟悉的一个领域。 在汽车智能化里,现在语言模型的应用非常普及。智能驾驶的目标是无人驾驶,现在NOA已经可以使用了,接管平均里程(MPI),现在国内头部企业在高速上普遍已经接近300-400公里,这个车开上高速公路大概率是用不着接管的。 城市NOA今年是热点,全国都能跑的技术是无图,用重感知,抛弃了高精度地图。所以今年我们看到的NOA,第一个词是无图,因为抛弃了高精度地图以后,一旦推出,开城这个事没有了,全国都能跑,已经做到了。 第二个词是端到端,特斯拉提出端到端以后,今年国内企业迅速跟上,一种新的AI模型(深度学习模型)的新的组装方式,就是用Transformer组装起来的端到端模型,性能水平急剧上升,所以今年3月份到6月份,我们的NOA技术已经有了一个飞跃式的发展。 为什么留在L2+,而不敢承认是自动驾驶?这里横在我们面前的就是深度学习模型带来的安全长尾难题(corner case)边缘场景。我们寄希望于大模型,大模型的确可以解决这个问题,但是大模型的运算能力要求太高,目前是上不到车上的。 现在在构建的用户数据闭环,基本是从用户那边获取数据,在后平台、云端使用大模型处理,大模型处理完了数据以后,训练一个小模型,再把这个小模型布置在车上。 哪天能够实现真正的自动驾驶呢?我觉得,大模型要真的上车,要具有举一反三的推理能力。因为边缘场景靠Scaling law、靠大量的数据,我们开车在路上总会有没见过的东西,即使四五十岁的人,看到没见过东西的概率也还是有的。 用小模型的话,什么东西都要见过,这件事情很难做到,而大模型是能够解决没见过的东西的问题,可以举一反三地推理。但大模型现在只能在后平台、在云平台,还无法到车上。 现在在深度学习模型上,边缘场景在所难免,现在智能驾驶卡在L2+,所以L2和L3之间出现了L2+。欧洲的L3已经有法规了,但是这个法规遇冷,ECE R157在2021年就推出,一直到现在只有4款车型做了认证,并且市场上也见不到过了认证的车,大家还是留在L2,我们叫做L2+。 但是留在L2+也有隐患,今年欧盟出了ECE R171 DCAS,对留在L2的智能驾驶NOA的车也要进行监管,其实ECE R171就是我们今天的NOA,所以到底是留在L2,还是向L3走? 给市场提供自动驾驶功能的车,一旦发生交通事故的话,是要承担法律责任的,并且有产品责任,现在这块留在L2+的状态,即便是NOA留在辅助驾驶,DCAS也是作为一类特殊的辅助驾驶,新的品类已经出现,新的国标也在起草中。 对无人驾驶的看法,还是蛮难的。在美国,特斯拉要摆脱制造业的低利润,All in AI,特斯拉的市值一直在涨,其实在特斯拉2024年年报中,销量肯定是下降的,中国比亚迪挑起价格战,他不回应,销量肯定下降,但市值还在上升。 他抛出来两个东西,一个是Robotaxi、一个是人形机器人(擎天柱),华尔街对它的估值非常高,Robotaxi的估值为5万亿美元,人形机器人的估值甚至高达25万亿美元,这两个加起来高达35万亿美元,已经可以把美国整个外债抵消殆尽,所以他是要完全走科技这块。 社会的确进入了人工智能时代,今年我们可看到,诺贝尔物理学奖和化学奖全部给了深度学习,都是人工智能。在8月底时,中央电视台也和我做过一个节目,在行业里,对人工智能这一新技术支持下的自动驾驶,大家对它的信心还是非常足的。 最后一块是创新的步伐不能停下,因为在创新的路上会有很多先烈,这些先烈如果停滞不前就会完蛋,比如推新能源,动力电池的上了,但是燃料电池的没人用。我觉得创新还得继续往前走,既然创新,思路可能要更宽一点。所以最后想谈一下低空经济下的城市立体交通。 这些低空飞行器运行的600米以下的低空区域,空管委已经同意下放给地方政府管理,这样给低空飞行域就提供了非常广阔的空间。我们在城市里,道路交通存在用地不足的问题,600米低空区域其实是很好的补充。 从产业角度来说,随着智能新能源汽车发展产业链的壮大,把这些飞行器生产出来没有任何问题,因为它是多旋翼的,跟新能源和智能化的产业链是一脉相承的。 国内国际汽车企业都已经进入了这个领域,应该是两大类机型,一个是多旋翼,一个是复合翼。如果在城市里跑的用多旋翼就行,但多旋翼飞不快,效率也不高,如果城市之间要跑到200公里、300公里就要用复合翼。多旋翼的好处是不需要机场,现在民航对机场需求依赖太强,这个可以原地起降、可以悬停,这些飞行器造出来没问题。 这是清华车辆学院和奇瑞合作的三件套,来解决飞行和汽车之间的矛盾。在道路上行驶时,机翼是碍事的,飞行时底盘重量也是碍事的,三件套想解决这个问题,道路行驶时无须折叠巨大的翅膀,在蓝天翱翔时也用不着带着沉重的底盘,这些创新在继续。 无人驾驶到底是单车智能还是网联智能,车路云这个思路、创新性很好,但是5G实在不给力,现在走不下去。 从云控角度来说,汽车已经在道路上自由行驶了130年了,凭什么控我?车路云网联智能的概念在车上很难实施,但是在飞行器上,毫无疑问,如果飞行器要起飞,就要向空管申请航道,批准后才能升空。 另外,光靠动力电池的话,低空飞行器在空中的滞空时间只有20分钟,如果加上燃料电池,现在已经可以做出滞空时间高达2小时的机型。 汽车领域过于创新超前的技术不要停下创新的步伐,继续往前走,可能会有一个更好的未来,我们不愿意在创新过程中看到一些先烈的存在,但创新要不断。 四、AI大模型能拯救自动驾驶仿真吗?
(来源:焉知汽车 ,作者陈康成)
仿真测试在智能驾驶领域的应用大致可以划分为两个阶段:
沛岱汽车CEO曹鹏博士解释说:“第一阶段的仿真是假设感知是100%正确的前提下,去测试规控算法。但问题在于,现实中感知永远不可能是100%正确,导致测试的结果跟实际的感知算法会存在‘Gap’。因此想要通过第一阶段的仿真调整规控层面的算法,去解决感知层面的问题是行不通的。只有传感器和场景能够更真实地被仿真模拟,才有可能仿真出感知模块所遇到问题的症结所在,然后才好判断下游的规控模块是否能够帮其收拾‘烂摊子’。”
在仿真测试的第二阶段,AI大模型有了发挥的空间,那么它究竟能够在哪些地方发挥作用呢?
一、AI大模型在自动驾驶仿真测试领域的应用探索
目前,AI大模型在自动驾驶仿真测试领域的应用探索主要有:
结构化场景的生成与泛化
提升仿真测试端人机交互效率
生成合成数据
1.1 结构化场景的生成与泛化
随着大语言模型开始逐步融入到仿真测试工作当中,AI大模型在场景自动化生成、加速场景库建设等方面发挥着越来越重要的作用。
通常智能驾驶相关的测试场景会被拆解为静态场景和动态场景两大部分。其中,静态场景主要是指一些交通基础设施,比如道路、车道线、路灯、周边的建筑等元素。动态场景主要包括多种交通参与者,比如机动车,非机动车,行人等,如何构建交互性强,覆盖度广的逻辑场景是智能驾驶仿真测试的一项关键任务。
常见的场景构建方式
静态场景
通过传统的方式去构建,比如用场景编辑器资产库去程序化生成场景。可以对道路周围树木及信号灯等标识根据不同拓扑结构进行自动的排布组合,生成更多的衍生虚拟场景。
通过采集真实数据,进行三维重建,比如基于NeRf或者3D高斯的方案。
通过生成式AI大模型去生成一些结构化的场景;通俗来说就是通过AI大模型去“脑补”场景。
动态场景
通过实采的海量真实数据,经过算法抽取,结合已有的高精地图,做动态场景重建。
对多元类型数据进行整合与加工,通过算法构建逼近真实的智能体行为模型,实现差异化动态场景的快速搭建。
通过生成随机交通流来模拟复杂的交通环境,通过设置车辆、行人、非机动车的密度,根据统计学的比例自动生成,大大提升了整个场景搭建的速度。
静态场景和动态场景的常用构建方式
“以前逻辑场景的设计和编辑需要大量的专家经验,即使有编辑器来辅助,也是一项技术门槛比较高的工作,现在我们可以使用大语言模型 —— 直接将自然语言的输入作为Prompt,直接生成逻辑场景。这个过程需要基于我们已有的一些场景库和相关场景描述,构建自己的一套 RAG系统。”51Sim CEO鲍世强介绍说,整体来看,大语言模型(LLM)适合用于场景库中的场景生成,多模态的大模型对于场景挖掘、描述生成和场景搜索,也可以大幅提升效率和灵活性。文生视频大模型主要用于直接生成感知层面的合成数据或者提升传统方式下生成合成数据的质量,构建更多的多样性等任务。
1.2 提升仿真测试端人机交互效率
腾讯数字孪生仿真技术总监孙驰天介绍说:“不管哪个行业的仿真,去配置仿真系统的各种参数和场景将会占用80%的时间,真正运行仿真可能只占20%的时间,大部分时间都用在仿真场景的生成和搭建上。我的判断是:AI大模型在仿真场景的生成和搭建上能够提升效率。举个例子,利用大模型,我们可以通过Prompt描述,直接输入 —— 一个北京城市路段上多车拥堵的十字路口场景,车速在30km/h以下,要进行无保护左转,车辆密度如何等等。仿真系统便可以根据 Prompt自动生成成千上万个测试场景出来,测试效率会提高很多。”
AI大模型有利于仿真测试端人机交互效率的提升。此处的人机交互效率是指仿真系统的用户使用仿真系统时的效率,比如配置仿真场景、参数等方面。
1.3 生成合成数据
随着自动驾驶仿真测试进入数据驱动阶段,需要的数据量越来越大。但是真实数据的采集和标注成本太高。因此,业内开始探索在仿真测试中用合成数据来替代一大部分真实数据。
目前,合成数据的主要用途是用于给感知模块去做训练。曹鹏举例说到:“大模型生成的图片或视频,可以用来丰富摄像头感知算法的学习素材库。训练集变多了,那么,感知算法的性能也会变得越来越好。”
对于感知用的合成数据,一般都有哪些类型呢?鲍世强告诉焉知汽车:“我们的合成数据一般给到客户的感知团队用于感知算法训练。目前我们已经落地了非常多的商业化案例,大致需求主要分为两类,一类是面向Corner case;另一类是面向特定需求,比如,车企布局海外业务,因为车要卖到国外的某个地方去,但是国内车企没有国外的训练数据,例如,一些国外泊车的场景或者道路交通类的场景,这个时候我们可以生成合成数据给到他们去做算法训练。”
上面提到的面向Corner Case的合成数据需求,又是怎么理解呢?“对于智能驾驶的测试场景,以前所使用的数据都是靠实车采集和标注来完成,现在智能驾驶的水平已经比较高了,但这也意味着基于大量的采集和标注数据去进行感知系统训练的边际效应已经开始递减。但高阶智驾的感知系统在落地过程中还是会遇到很多问题,这些问题可以理解为是大量的Corner Case ,但是真实采集的数据中这类数据比较少。那么,怎样能够生成一些高价值的合成数据去加到真实数据一起去做训练,是目前大家比较迫切的需求。”鲍世强解释说。
那么,目前,生成合成数据的方式都有哪些呢?经过调研分析了解到,生成合成数据的方式大致可以分为以下三种:
1) 基于图形渲染和程序化生成方式 ,也就是说通过渲染引擎(游戏引擎或者传统渲染引擎 )的方式去做。
孙驰天说“游戏引擎的好处在于它能够方便地实现传感器的仿真,基本上所有常用的车载感知传感器,包括激光雷达、摄像头、毫米波雷达及超声波雷达都能实现。优点在于它能输出所匹配的真值,尤其是摄像头仿真,做得比较成熟,可以配套输出包括深度值、语义值等在内的各种信息。缺点是生成图像不够真。但是,我们会在游戏引擎的基础上再加一层AI推理算法,将游戏引擎输出再转换成真实风格的图像,能够比较好的去解决摄像头仿真不够真的问题。”
2) 基于三维重建的方式 ,比如采用NeRf、3D高斯等图像拟合的算法直接生成。
目前,3d高斯的方法应用更多一些,优点是真实感非常强,缺点就是泛化性比较差。想构建哪个路段的场景必须要重新采集一遍,会带来比较高的成本。并且,对采集数据的质量要求又比较高,基于量产车采集的回来的数据基本没办法使用。
3) 基于大模型直接生成的方式 。大家非常看好它的未来,但现在还属于早期的发展阶段。另外,因为此方式生成的数据没有配套的真值,所以没有办法直接用于感知算法的训练和测试。
鲍世强谈到:“合成数据好坏的判断有两个关键评价指标:一个是真实性。另一个就是如何在单位成本内获得更多的多样性。
“目前的生成合成数据的几种主流方式各有特点和优劣势。图形渲染的路线,灵活度和确定性比较强,目前也相对最成熟;NeRF和3D高斯的路线对于重建真实的静态的场景,或新视角合成效果很好;基于大模型的路线,在真实感和泛化性上有较大的优势。我们需要有效地把这几种方式结合起来以发挥各自的长处,而生成式AI在这个领域毫无疑问会发挥越来越大的作用,这也是公司依托既有实践和技术重点布局的重点方向。”
二、AI大模型生成的数据还存在哪些问题?
2.1 大模型生成的数据没有配套的真值信息
用大模型来生成合成数据,目前挑战的点在于:现有大模型一般用于生成图像,用于点云生成的工作较少,也不成熟。并且它生成的图像没有配套的真值,即我们并不知道图像里每一个要素是什么,具体的三维坐标、包围盒以及语义要素是什么。“如果拿去跑感知算法的测试,跑完测试之后,没有真值就没办法评测感知算法识别的准不准,没有真值更不可能低成本去做感知算法的训练。因此,大模型生成的合成数据,用于感知算法的测试和训练,目前我觉得在技术上还不够成熟。”孙驰天认为。
另外,现在类似Sora的文生视频大模型,可以生成一小段视频。相对来说,画面也非常逼真,是否可以应用到自动驾驶仿真测试领域呢?对此,孙驰天持否定的观点,他认为,这些视频里面的物体并没有匹配的真实信息。首先,大模型生成的结果未必是物理真实的,可能会有一些在物理特性上并不合理的存在,因为他们在被训练的时候并不包含显式的物理规律约束在里面。其次,他们没有匹配的真值,对于感知算法测试和训练来说没法低成本使用。总之,基于AI大模型生成的图像或者视频,在自动驾驶仿真测试中,目前还没有看到比较好的实战结果出来。”
2.2 大模型生成的合成数据遍历性差
大模型生成的合成数据还存在另外一个问题,就是遍历性差;因为大模型是一个黑盒,没法证明它的遍历程度。比如,我们怎么能证明自己通过大模型生成的100万个视频片段就几乎包含了所有想要的情况呢?
“现在通过AI大模型生成的视频,很多都是去评价它的合理性,比如水滴是否是向下落的,人是否是有影子的,但还没办法证明它的遍历性。对于非机理的模型,要证明它的遍历性,只能反向从结果证明。比如,AI生成交通流,会用一些交通流相似性指标跟真的交通流去对比,核查是不是真实交通流中所有的被关注的情况都被覆盖到了。”曹鹏解释到。
三、AI大模型是否可应用于交通流仿真?
交通流仿真不仅可以用于传统交通行业,帮助其改善路网与交通管理效率,并且还能应用于自动驾驶行业,辅助构建虚拟城市场景、生成自动驾驶车辆测试场景的动态交通环境。
根据交通仿真模型对交通系统的模拟细节程度的不同,可分为宏观、中观和微观三种交通仿真模型。其中,在自动驾驶仿真测试中,我们讲到的交通流仿真其实是属于微观交通流仿真,主要研究每个车辆-驾驶员单元的行为交互。
类型划分
研究对象
基础定义
特点
宏观交通流
整个交通流
用流体力学的方法对交通流进行建模,从整体层面对交通流进行分析和预测,着重表现道路网络的总体运行状态和特征。
该类模型对计算机资源要求较低,仿真速度较快,比较适合对大规模路网进行交通仿真。
中观交通流
若干车辆构成的车队
描述车队在路段和节点的流入流出行为,对车辆的车道变换之类的行为也能用简单的方法近似描述。
该类模型介于宏观和微观之间,可用来评价较大范围的交通流,但由于模型中的变量太多,难以实时求解,在应用上会受到一定限制。
微观交通流
个体车辆和驾驶员行为
从运动学角度对车辆的加速度、转向和制动行为进行建模,着重考虑个体车辆之间的相互影响和交互,能够较为精准的描述车辆在道路上的跟驰、换道、超车等行为,并且能够提供直观的交通流动画演示。
该类模型对计算机的资源要求较高,仿真速度慢,一般用来研究交通流与局部道路设施的相互影响。不过当采用并行处理技术时,微观模型也可用于大型路网的交通仿真。
交通流类型划分与定义(信息来源:赛目科技公众号)
3.1 交通流仿真技术路线
传统交通流建模是基于各种物理学原理(主要是运动学),使用微分方程、偏微分方程等数学工具来描述道路上车辆的跟驰、换道等行为。其特点是交通流模型的限制条件比较苛刻, 模型推导过程比较严谨, 模型物理意义明确。
然而,现代交通流建模以现代科学技术和方法(如神经网络、人工智能等) 为主要工具来描述车辆行为。其特点是所采用的模型和方法不追求严格意义上的数学推导和明确的物理意义, 而更重视模型或方法对真实交通流的拟合效果。
目前,现代交通流仿真建模的主要技术路径有:
专家通过组合一些Rule-based模型来生成交通流仿真模型,比如基于城区或者高速不同交通特征的模型,然后再去训练和标定参数。
孙驰天介绍说:“传统交通行业交通仿真通常是基于Rule-based方案。他们通常会先跑一个中观仿真模型出来,计算出不同路段上车流的流密速,包括路径分配等结果,然后再用中观仿真模型的结果去指导下一层的微观仿真 ,这便会涉及到车与车之间的精细交互。此方案的优点是体系比较成熟,而且能够基于中观来指引微观,模型仿真出来的结果在中观上也会比较真实,同时,这种方式对于 CPU消耗相对也会比较低。”
通过大量采集的交通数据去训练出一个交通仿真模型,在某种程度上能够更好地去展现一些博弈的行为。优点是车与车之间的极微观的交互比较真实。缺点:一是CPU算力消耗会高一些;二是无法接受中观仿真模型对于微观模型的一些分配,所以中观层面上准确率可能会低一些。三是,要实现产品化落地,会对成本很敏感,目前此方案尚未达到商品化的程度。
曹鹏给出的观点是:“用AI去做交通流仿真,比较成熟的技术是用GAN(生成式对抗网络)去做,也就是深度学习的方法。使用采集到的交通数据不停地训练模型,使得其越来越像我们在某一个城市采集到的交通流。
“ 我认为生成交通流主要有两种方法:1)一种是随机交通流;2)另一种是基于GAN的交通流。随机交通流的特点在于它所有交通行为都是随机的。随机做出来的交通流更加适合自动驾驶的验证和优化,基于GAN做出来的交通流更加适合用于自动驾驶的评价。”
3.2 AI大模型对交通流仿真的影响
如果用大模型来做交通流仿真,本质上是通过大模型将交通仿真做模型计算的过程,直接黑盒化,然后用数据来做训练。直到现在,行业里还没有看到比较好的落地案例,还处于比较早期。
“传统的交通仿真用于智驾仿真测试其实不是特别适合,因为传统的交通仿真做的是宏观和中微观的事情。即使是微观,它研究的重点也是交通本身。智驾其实关注的是更加微观的行为。基于大模型做出的交通流,可以体现出很多的微观层面的博弈行为。它虽然也是拿真实数据训练出来的,但又跟直接采集数据还原出来的轨迹不一样,它具有较高的灵活性。整体而言,这也是一个很有前景的方向。”鲍世强认为。
四、目前来看,AI大模型对仿真测试来讲还不是刚需
大模型在仿真测试领域的应用,虽然说技术还不成熟,但技术路线是可行的。但自动驾驶仿真测试终究是要为量产项目服务,我们在关注AI及大模型技术应用的同时,也应该着重关注一下自动驾驶仿真测试当前最核心,并且也最迫切需要解决的问题:仿真测试的一致性问题。
孙驰天说:“可以无数次重现同一场景的仿真一致性是仿真系统最核心的能力。相较于真实世界的测试,仿真测试最大价值在于仿真测试的一致性。但是,仿真测试的一致性达成什么程度算好,目前行业还没有达成共识。
“我们整个行业与其无止境的卷仿真模型的真实性,倒不如优先保证并解决仿真一致性问题。比如,大家在资源有限的情况下,仿真模型真实性在提升到85%~ 90%的情况下,再往上提升已经比较困难,这个时候,我的建议是我们需要优先考虑把仿真测试一致性做得更好,而不是继续把仿真模型的真实性卷到更进一步的90%~95%,但仿真一致性却不稳定。仿真测试一致性得不到很好地解决,把仿真模型真实性卷得再高也没有意义。”
那么,仿真测试一致性会受到哪些因素影响呢?其实,仿真测试的一致性会受到很多因素的影响,比如,仿真模型与实际被测件的标定真实性和特性匹配程度,以及仿真测试各系统之间交互反馈时钟同步与实际测试的一致性等。
曹鹏认为,“在感知部分,模拟传感器可能会存在一些一致性问题,如果用的是随机算法,传感器模型的一致性很差。如果是通过模拟物理过程模拟传感器,得出的结果一致性会高得多。另外,一致性跟时间的同步性也有关系。在操作系统调用模型的过程中,如果模型调用的频率,以及调用时间点每次都有波动,最后得出的结果可能就不一致。”
五、结语
AI大模型与仿真测试契合度非常高,从某种意义上来讲,仿真本身就是在做生成数据的事情。当然也有业内仿真专家持不同意见,他们认为,使用大模型的核心目的不是为了生成新的数据,而是帮助用户更快捷地通过自然语言的方式提高场景制作的效率。
仿真测试基本都是建立在物理学的基础之上,现在AI也开始逐渐渗透并融入到仿真测试之中。“AI和物理科学其实就是描述世界本质的两种不同方式:一种是用近似的方式;另外一种是用抽象的方式。AI是非物理的,属于一种科学的近似,是对现象的一种近似和模拟。它试图通过将一模一样的神经元排到一起,去近似出世界的规律。而物理学则是追求规律的精确和确定性,注重假设、归纳和抽象规律,习惯于把复杂的问题简单化,尽量用一个简单的公式去解释某种复杂的现象。我们其实一直在寻找AI跟物理学的结合点。”曹鹏从另外一个比较有意思的角度谈到。
整体来看,AI大模型在自动驾驶仿真测试领域的应用方向是比较明确的,只不过目前还存在很多问题待解决。总之,前途是光明的,但通向成功的道路却是不平坦的,仍需要行业“上下而求索 ” 。 五、大模型系列 | 自动驾驶大模型
(Vision 自动驾驶之心)
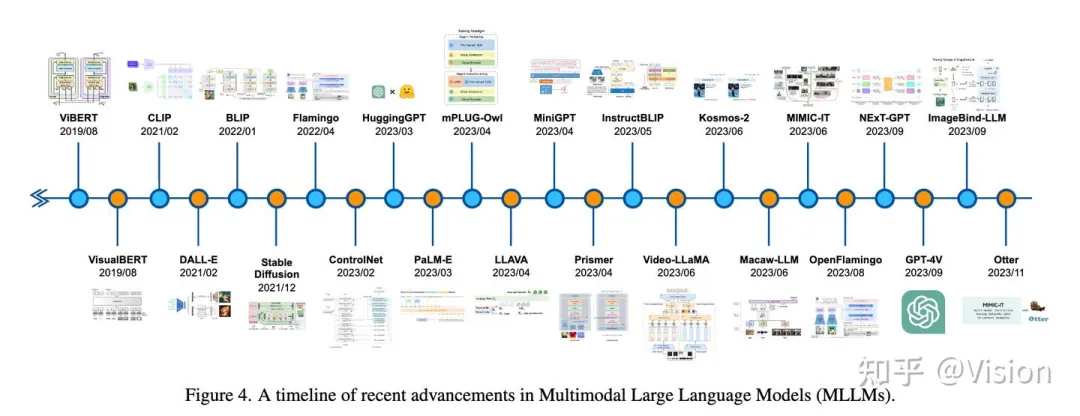
前言 按照之前Vision:大模型系列00 - 前言 规划,带来第5篇文章-大模型在自动驾驶的运用调研。由于大模型的强泛化能力,引起了其在自动驾驶领域的关注。传统自动驾驶主要聚焦模块化提升性能效果,存在的上限问题显而易见。另外一方面,原来学术界研究重点还是如何提高单模块的上限,比如感知/预测/强化学习/模仿学习(具体分模块介绍见Vision:自动驾驶系列00 - 前言系列),2023年得益于cvpr 2023 best paper uniad 开始才转向端到端在自动驾驶的运用。所以整体调研内容会涉及到大模型和大模型based的端到端工作,大多数paper集中在2023年度(文章新,大部分还在peer review中),很多是从arxiv上直接search得到,揉杂了很多参差不齐的文章也很正常。整体涉及约70篇左右,为了保证阅读质量和提升阅读效率,重复文章会舍弃,并首次增加 推荐程度 (高/中/低),来highlight推荐阅读的文章。
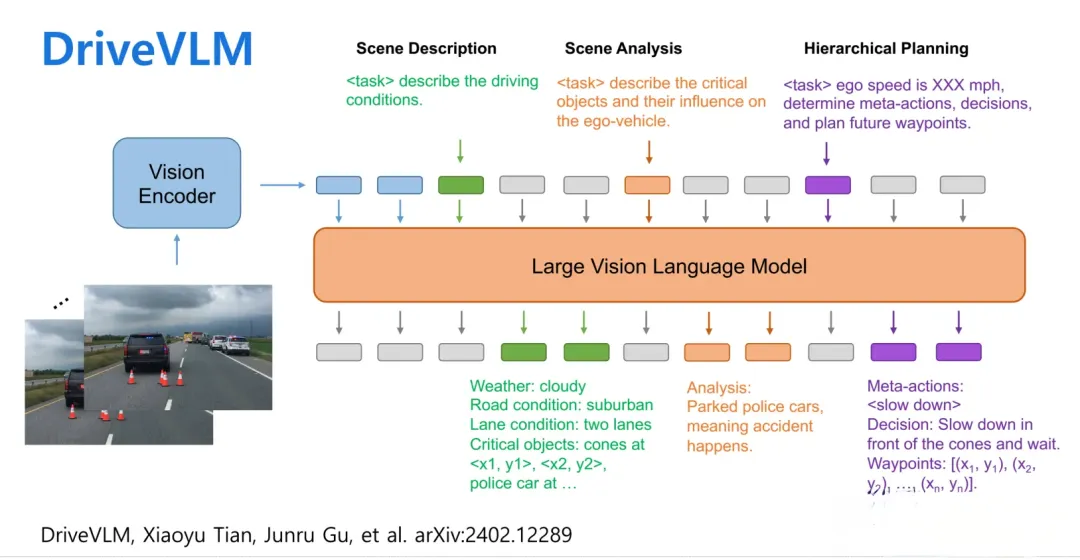
大模型在自动驾驶运用的方向(5个) 自动驾驶场景仿真数据生成 内容 :这个跟上一篇图像生成博客Vision:大模型系列04 -文本图像生成有点相关,但这里更多是3d scene数据(包括动静态元素)和2d图像/2d环视图像等等的生成,会多涉及一些3d空间的概念。当然点云数据生成自然也是一个方向。基本的原理还是基于diffusion/nerf/guassian splat(还没来得及研究)等。 运用方向 :仿真团队来做一些高级点的传感器仿真/交通流仿真/worldsim等方向的工作 “world model“场景预测生成 内容 :这个方向最近比较火,gaia最早提出,后来cvpr2023 tesla学者提了一下,后续工业界也赶紧跟上了。这个主要结合多模态信息(更主要是high-level commond,譬如左转)来生成预测接下来的图像和3d scene的信号。当然也可以输入一些文本(比如雨天等)做condtion,生成对应场景的数据。这个方向跟基于上一个方向-自动驾驶场景仿真数据生成基础上的,所以是渐进的关系。 “world model“打引号原因 :目前大家习惯把通过加入一些condition信号就能生成图片或者video的基础模型成为“world model”,跟原本提出的概念不太一样(见前面“两个基础概念”阐述)。不过既然学术圈大家都达成共识这样提,我们就默认把自动驾驶领域的world model当作这样的定义。 但目前基于未来场景的预测,对planning和整个ad系统有什么确定性的改进,目前大家都没有在工作中提到,一种可能的影响是基于未来场景精确的预测,提升类似感知超视的感知结果或者推衍逻辑,来辅助现有模块化ad或者大模型reasoning架构的效果。 感知自动标注 内容 :这里更多是利用多模态领域的大模型的一些经验来帮助做一些图像/点云 open vocabulary(公开字典)的长尾问题的标注,并进一步提升云端标注结果的精度。 运用方向 :感知团队/数据标注团队/数据挖掘团队(离线) 利用多模态大模型能力做决策及规划或者end2end 内容 :这个topic 算是目前大模型在自动驾驶领域研究的火热方向,但受限于其先进性和不确定性,更多工作集中在学术界。简要概括就是利用大模型的推理和泛化能力能直接接入感知或者原始sensor信号,然后做language的决策信号输出,并能对ad的各个模块有一定reasoning/justice/relection的能力。由于其耗时大和可部署性,很难短时间在边缘设备上运用起来。但其实这种交互方式就很自然,就像我开车跟租出车司机交流一样,不跟他说话时他自动开,跟他说话时,让他在前面路口左转他就能左转。 希望模型蒸馏/减支,硬件创新等都能比较大的突破,期待早一日实现ai代驾司机的体验。当然云端继续验证肯定没错,证明其上限能力。 端到端联合训练自动驾驶(不一定是大模型) 内容 :这个方向其实是新型的端到端联合训练,各个模块通过feature直接共享,中间每个模块会输出一些结果。但整体planner做的比较学术,而且基于nuscene的开环测试参考意义不大。但工业界都能看到这是一步可以达到的棋,就看在planning这个模块,是采用传统的强化学习还是模仿学习来做,还是利用一些新的但是又不需要大模型这么重的算力方式来解决。 参考核心综述paper list(7篇,强推荐3篇) [推荐]End-to-end Autonomous Driving: Challenges and Frontiers comment : 20230629李弘扬联合香港大学的部分学者发布了一篇端到端自动驾驶综述文章,大约是在uidad获得2023cvpr best paper之后的一周后放出来。这篇文章首先介绍了end2end ad的演变roadmap,从最开始1988年的alvinn到2023年的uinad;后面大概将端到端学习分别两个技术大类(模仿学习(行为克隆,反向最优控制)和强化学习),并简单进行阐述;紧接着介绍了benchmark(着重介绍闭环在线评测,离线开环检测简单罗列);后面系统介绍了端到端系统的8个挑战和相应已经做的一些工作(1. 输入模态(多模态,自然语言)2. 语义抽象 3. model-based的强化学习 4. 策略预测导向的多任务训练 5. 策略蒸馏 6. 可解释性保证(注意力可视化,可解释任务,中间结果cost学习,语言化的解释,不确定度的建模和衡量)7. 因果混淆 8. 鲁棒性(长尾问题分布,covariate shift,domain adaption));最后介绍了未来方向(zero-shot泛化,模块化的端到端planing,数据引擎,基础模型,v2x)。整体文章我感觉作为新手还算不错,特别是把端到端的一些挑战(可解释性等)重点highlight出来,并列举了一些目前解决的方案和办法。但对整个端到端技术的罗列上比较欠缺,但文章也特别说明这部分可以去参考其他综述。缺点:1. 如何在实际系统中的部署难度问题(比如时延和算力)也没有明确指出来,或许学术界就不太关注这块,毕竟效果上都还有很多问题亟待解决。2. 没有涉及到大模型方面结合的工作,但也提出了language输入等小topic,但重心还是在端到端的驾驶设计上,没有充分利用大模型在多模态上的泛化能力。
recommend level :高,挑战点集中罗列
[推荐]Vision Language Models in Autonomous Driving and Intelligent Transportation Systems comment : 2023年10.22 慕尼黑工业大学学者上传一篇多模态在自动驾驶和智能交通上的运用综述文章。我仅关注自动驾驶方面。首先分了 5个模块(感知理解,导航规划,决策控制,端到端,数据生成)来做归纳运用;然后介绍了自动驾驶数据集和语言增强的自动驾驶数据集(15个,算是比较全的);最后讨论了部署大模型到自动驾驶的6个方面细节(自动驾驶基础模型,数据获取与格式,安全对齐,多模态adaptation,时序场景融合,算力和处理速度)
recommend level :高,总结的数据集全
A Survey of Large Language Models for Autonomous Driving comment : 2023.11.02上海交大严骏驰团队和李弘扬团队合作共同发布了一篇大语言模型在自动驾驶上的运用综述。文章分了4个方面(规划控制,感知,问题对话,数据生成)来介绍运用,每个方面除了介绍实现方法,还单独给了一个小段落来总结评测的metric,但是感觉很多都不一样。最终介绍了8个大语言自动驾驶驾驶数据集。实现文章基本所有分析paper均在2023年黄裕发的那篇paper里都有描述;同时8个自动驾驶数据集在202310月慕尼黑工业大学那篇综述里也全部被包含(总共介绍了15个)。所以这篇paper整体质量并没有那么高,不过可能同样的文章和数据集描述的角度不同。在看具体paper时,可参考该文的具体描述。
recommend level :中
[推荐]Applications of Large Scale Foundation Models forAutonomous Diving comment : 20231120知乎大佬黄浴在arxiv上上传了一个大模型在自动驾驶方面运用的综述文章。分了3个大方向(仿真及世界模型22篇(传感数据合成9篇;交通流数据合成4篇;世界模型11篇),自动标注7篇,决策规划和端到端21篇(大规模语言模型集成13篇;类似nlp的tokenization预测5篇;预训练基础模型3篇))。当然除了介绍运用,在前面还详细罗列了大语言模型,多模态模型,diffusion model,nerf这4大技术基础领域的进展。整个文章的技术完整度还是挺好,但缺少了数据集(可以看慕尼黑工业大学那篇综述)、评测指标(参考yanjunchi那篇综述)及目前难点问题讨论。文章的表格罗列也是很赞。整体是推荐阅读深究的。可以结合其他两篇综述,合并下每个人习惯的总结分析角度。
recommend level :高,涉及多模型运用方向全
A Survey on Multimodal Large Language Models for Autonomous Driving comment : 20231121普渡大学学者和国内腾讯等单位发表的综述(组织了WACV 2024 LLVM-AD),介绍了多模态大语言的今年来发展趋势,然后介绍其在自动驾驶的文章和数据集(比较少),另外disscuss部分罗列了几个挑战(可以阅读)。整体没有很大的信息量https://github.com/IrohXu/Awesome-Multimodal-LLM-Autonomous-Driving。
recommend level :中
Towards Knowledge-driven Autonomous Driving comment : 上海ai实验室shitianbo团队发布的以agent-envorment交互为模式的自动驾驶,具体还未细看。项目链接 https://github.com/PJLab-ADG/awesome-knowledge-driven-AD
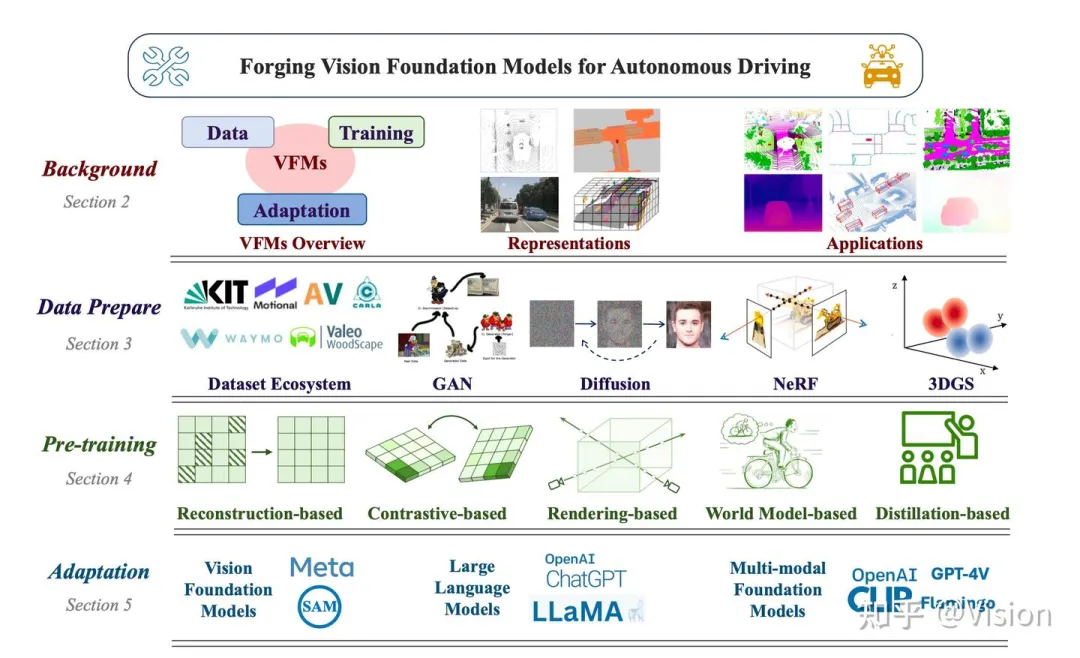
Forging Vision Foundation Models for Autonomous Driving: Challenges, Methodologies, and Opportunities comment : 2024年1月,华为nora实验室发布关于一些自动驾驶领域的视觉模型的运用,算是比较全面的总结(不仅仅限于大模型),但还未细看。项目链接:https://github.com/zhanghm1995/Forge_VFM4AD
两个基本概念(world model/foundation model)paper World Models comment : 2018 google:提出了world models,利用在仿真环境中强化训练,可迁移到现实场景中。整个系统分为3部分,v/m/c。v是利用vae方法训练得到一个hiddle state z(高斯分布假设参数),M是通过一个rnn模型来encode时序和空间表达信息得到ht. c是一个简单的mlp,接受【ht,c】和当前的action_t,得到action_t+1, loss为最后c的强化学习奖励函数激励
recommend level :高,基础定义paper
On the Opportunities and Risks of Foundation Models comment : 2021年8月stanford发布了foundation models的研究,提出foundation model的两大特性emergance and homogenization。文章很长,整体会涉及fm是什么,有什么能力,在哪些方面有运用,社会影响,以及一些report报告汇总等。但youtoube上1个半小时视频整体以ppt的方式讲解了一下,了解的算是比较全面。链接https://www.youtube.com/watch?v=ZshcPdavsdU。另外foundation model这个名词原来21年就有了,但今年2023才大活起来,还是要多看paper,看好paper。
recommend level :高,基础定义paper
前序基础知识参考paper NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis comment : 202003 uc berkeley(2020eccv):nerf 提出一种新的2d数据合成的方法。基于神经发射场,利用mlp学习一个空间连续函数映射。(color,density)= mlp(x,y,z, θ, φ ), 利用光线积分法得到2d图像上的显示色彩,为了加速,设计corse-to-fine的积分方法,通过corse得到概率密度函数,再通过fine密集采点,整个函数训练loss为图像的误差。 recommend level :高,基础定义paper
方向1.1 - 自动驾驶场景数据生成-传感器数据方向(7篇,强推荐1篇) READ: Large-Scale Neural Scene Rendering for Autonomous Driving comment : 202205 浙大and 陈俊波 AAAI2023 paper,提出w-net(u-net)变形,通过2d重建3d point,加3d point编辑重新生成不同相机内参2d图像的方法。
recommend level :低
[推荐]Street-View Image Generation from a Bird's-Eye View Layout comment : 202301 ucla:bevgen,通过bev layout生成多视角图像,保证bev和2d view一致,cross-view也一致,具体会把image和bev layout都会通过vq-vae的方式量化成离散向量;然后利用内外参坐标转换到车体坐标系下,然后通过cross attentionn方式交互。整体是vae的架构,gpt-like的结构。
recommend level :高,首次生成3d/2d多相机和3d一致性图片
Generating Driving Scenes with Diffusion comment : 202306 zoox:scene diffusion 利用diffusion结构,基于map-condition生成bev下的目标集合(好像只生成位置和朝向,没有速度),方便pnc等下游利用bev下的3d结果去做一些实验。
recommend level :低
DriveSceneGen: Generating Diverse and Realistic Driving Scenarios from Scratch comment : 202309 新加坡国立大学:driveSceneGen, 利用diffusion生成前背景,然后对前景做预测。整体细节描述比较少,而且diffusion过程没有condition的引导,不知道在实际infer过程中的输入noise是怎么来提供特定场景信息从而生成专向场景
recommend level :低
WEDGE: A multi-weather autonomous driving dataset built from generative vision-language models comment : 202305 cmu: 利用dalle2弄了个仿真检测的数据集,并验证训练的有效性
recommend level :低
MARS: An Instance-aware, Modular and Realistic Simulator for Autonomous Driving comment : 202307 air清华:提出部分开源的基于nerf的图像仿真框架,前景和背景模块化,且生成pipeline模块化,效果逼真。
recommend level :中
Adv3D: Generating 3D Adversarial Examples in Driving Scenarios with NeRF comment : 202309香港科技大学-广州:adv3d,通过2d patch加攻击,通过nerf生成3d 驾驶场景来欺骗3d 检测器。整个生成过程的loss是降低目标周围附近的检测障碍物的confidence
recommend level :中
方向1.2 - 自动驾驶场景数据生成-交通流方向(5篇,强推荐1篇) Guided Conditional Diffusion for Controllable Traffic Simulation comment : 202210 nvidia: ctg,提出可控的交通流仿真,离线训练一个diffusion的model,在线通过传入传统规则的stl rule来作为condtional guide来保证交通流,具体的diffusion的数学推导没认真看
recommend level :中
RITA: Boost Autonomous Driving Simulators with Realistic Interactive Traffic Flow comment : 20221117 上海交大&huawei :rita,基于2020年发布的smart仿真器集成的交通流仿真插件工具。相比于原来的sumo等,这次采用的一种数据驱动的仿真流方法。整体分ritbackend和ritakit,也可以放到sumo等架构中。kit制定感兴趣区域和基本仿真策略,后端利用模仿学习和diffusion来生成轨迹。具体细节没有太描述。
recommend level :中
TrafficBots: Towards World Models for Autonomous Driving Simulation and Motion Prediction comment : 202303 icra 苏黎世理工:提出一个交通流仿真及轨迹预测的文章,跟之前有一篇将drivescene生成的有点像,对于每个目标设置一个导航方向来确保可配置性,所有agent公用一个场景context来确保可扩展性。整体文章我觉得没撒很创新的点。
recommend level : 低
[推荐]Language-Guided Traffic Simulation via Scene-Level Diffusion comment : 202301 cmu&nvidia: ctg++,基于ctg的升级版本,提出scene-level diffusion model的结构,避免了ctg的单agent diffusion model。另外condtion引入了自然语言的promot,通过gpt4变为一个lossfunction来去guidance。整体做了比较详细的相对ctg的改进,附录部分阐述了比较多细节。
recommend level:高,利用nlp,且附录细节充足
SurrealDriver: Designing Generative Driver Agent Simulation Framework in Urban Contexts based on Large Language Model comment : 202309 清华: 提出surrealdriver,通过设计拟人的driver agent来加强模拟车辆的智能性。通过人工驾驶描述数据来作为cot的promot来生成coach driver来引导合理的驾驶行为。另外整个perxeption./decison-making/action都有显示的condition输入。整个框架还是auto-gressive的。整体llm的细节并未完全描述清楚,而且agent与agent的强交互并没有显示建模,而是通过promot的方式来制定(不一定坏)
recommend level :中
方向2 - “world model“场景预测生成(9篇,强推荐6篇) [推荐]UniSim: A Neural Closed-Loop Sensor Simulator comment : 202306 wabbi:提出一种数据驱动的传感器仿真数据(camera&lidar),利用神经特征grid的方式来建模动态和静态,然后也训练了一些网络来预测恢复动态车的不同view,从而可以生成逼真的drving grid,然后通过原理生成对应的lidar和camera结果,整个训练的loss包括lidar和camera senor的l2重建loss等。视频效果比较amazing。代码未开源,估计会中2024cvpr
recommend level: 高,惊艳仿真圈的工作
[推荐]UniWorld: Autonomous Driving Pre-training via World Models comment : 202308 北大 uniworld:通过lidar点云-环视相机,训练预训练模型,通过生成4d occ grid的方式来反向传播,然后再用于做下游任务,比如检测/分割/预测,整体思路比较简单,而实际中bev feature的构建是比较耗时的,各个任务的要求是不一样的。所以bev transformer和feature encoder是否一定要做成预训练,方向是对的,就看算力问题了
recommend level:高,3d点云生成工作
[推荐]GAIA-1: A Generative World Model for Autonomous Driving comment : 202309 wayve:利用video+text+atction 训练world model,然后接decoer生成视频。整体结构利用autogresssive transfromer结构(65亿参数)。整体利用预测next token的方式来训练。
recommend level:高,高参考性工作
[推荐]DriveDreamer: Towards Real-world-driven World Models for Autonomous Driving comment : 202309 极佳科技&清华:提出drivedreamer,整体原理跟百度的drivingfusion系列很像,通过生成视频的方式来体现world model的能力。可以通过一些condtion,比如把交通流信息投影到图像上得到2d view的condition,另外又有一些文字描述,或者driving action(刹车油门,方向盘)等信号。文章训练分两个阶段,一个是auto-am, 通过输入多模态的condition训练diffusion生成vedio,然后第二个阶段actionformer,通过gru等结构和cross-attetntion得到新的feature,然后condtion输入到auto-am结构生成进一步的视频。在这里提一下,world models是强化学习领域表达时间和空间信息的一个抽象模型,从这一点看来现在ad领域讲的world model都有点像。但实际上这两者还是有点区别,我们现在更多是通过所谓构建世界模型去生成图像/视频。而直接用于原有world model对三维空间的表达的直接验证还没有说明效果。
recommend level:高,可接入文字等多模态信息输入
[推荐]DrivingDiffusion: Layout-Guided multi-view driving scene video generation with latent diffusion model comment : 20231014 baidu vis:利用diffusion生成自动驾驶场景多相机视频。利用3d layout和text信息做condition指引,保证生成的图片跨相机和跨时序都有一致性。相对于bevgen多了个时序建模,同时多相机的一致性建模也有些区别(本文采样view-wise的attention,bevgen采用token-wise)。另外方法也不一样。文章也采用了后处理refine model来解决时序长时遗忘问题,因为时序都是由第一帧promot出来的。具体还有光流的condition,不知道这个是如何提取的。文章也提到了可以扩展到其他的mode condition。
recommend level:高,3d layout使用
[推荐]LEARNING UNSUPERVISED WORLD MODELS FORAUTONOMOUS DRIVING VIA DISCRETE DIFFUSION comment : 202311 waabi: 类似之前usim的生成文章,这篇提出了如果通过历史3d数据 + action 生成未来3d点云数据,利用vqave将点云转化为hidden state,然后通过world model,最后通过类似nerf建模恢复3d世界。其中利用了masked gpt的思路,来使得训练效果更好。
recommend level:高,点云生成
MUVO: A Multimodal Generative World Model for Autonomous Driving with Geometric Representations comment : 202311 kit(德国一所科研大学):提出通过视觉和点云生成将来的自动驾驶场景的rgb和pointcloud/occ world,引入action作为condition,利用calar仿真环境生成的。整体思路跟其他类似的drivedreamer等大多数文章都比较类似。
recommend level :中
ADriver-I: A General World Model for Autonomous Driving comment : 20231120 旷世:类似其他生成网络,利用图片,action作为condtion,直接生成action和对应的predict图片。整体思路都差不多。
recommend level :中
Driving into the Future: Multiview Visual Forecasting and Planning with World Model for Autonomous Driving comment : 202312 中科院学者:类似world model预测,细节还没来及看
recommend level :未知
方向3 - 感知自动标注(8篇,强推荐1篇) Talk2Car: Taking Control of Your Self-Driving Car comment : 201909 比利时学者:提出通过nlp commond 来对数据做标注,nlp和image的交互识别方法好像没特别提出,提到了亚马逊的工具。应该是个数据集文章。
recommend level :中
OpenScene: 3D Scene Understanding with Open Vocabularies comment : 202211 google(2023cvpr):利用clip特征,联合3d点云训练后,可用于3d点云下的open vocabulary的检测。整体实现思路比较简单,估计是第一篇做这个运用的文章,所以中了cvpr。代码已经开源。
recommend level :中
AD-PT: Autonomous Driving Pre-Training with Large-scale Point Cloud Dataset comment : NeurIPS2023 上海ai实验室&复旦202301:提出了一种点云预训练的方法。利用开源的部分带label训练出的detector在大量无标签的基础上得到大量高精度的伪标签;然后通过点云resampling 和 object size augmentation的方法来增广数据;设计一个随机采集roi特征+一致性loss的方式来召回少见的长尾正样本。训练出来的网络在部分任务上finetune后检测效果更好。可支持不同的检测器来当训练的backbone。文章也没用什么transformer结构。算是第一篇提出3d 点云预训练的文章,但又不是大模型预训练。文章提到的一些resampling和data augemttaion实际工程中也或多或少会采用。这个梗适合来做云端4d gt的标注涨点思路,看起来比较多的trick
recommend level :中
Language-Guided 3D Object Detection in Point Cloud for Autonomous Driving comment : 202305 北京科技大学&赢彻杨瑞刚:提出language 3d point retrial系统,通过直接监督3d point instance proposal和language,类似clip的点云泛化版本。图像这块链路是opitional的。没有预训练的clip模型。其实跟22年11月发的openscene有点像。
recommend level :中
[推荐]Language Prompt for Autonomous Driving comment : 202309 北京科技大学&旷世:提出nuprompt数据集,基于nuscene数据集人工标注子属性标签,然后任意组合子属性标签,然后通过gpt3.5生成描述的sentence。整体提出promottrack的识别框架,text encode成单独链路特征,环视图片数据通过时序生成特征,然后作为query送入到text embedding中输出对应的bbox。另外环视图像做正常检测跟踪,类似trackformer结构。
recommend level:高,细节描述较好
[推荐]HiLM-D: Towards High-Resolution Understanding in Multimodal Large Language Models for Autonomous Driving comment : 202309 香港科技大学&华为:提出一种输入图像,到输出可解释和简单的建议action,并能grounding出导致主车行为变化的risk目标。整体有两个branch,第一个是低分辨率的视频帧席勒输入,另一个是高分辨率的单帧输入。两个branch有交互。低分辨率输出可解释的自然语言描述和建议。高分辨率输出图像的bbox。整体想法还是朝着端到端方向走,只不过为了可解释和无法闭环仿真验证。更多还是在可解释性上做了一些尝试工作。
recommend level:高,nlp出bbox
Unsupervised 3D Perception with 2D Vision-Language Distillation for Autonomous Driving comment : 202309 waymo: 提出一种利用文字图像匹配特征做open cabutory的物体检测,类似mssg等paper思路。
recommend level :中
OpenAnnotate3D: Open-Vocabulary Auto-Labeling System for Multi-modal 3D Data comment : 202310 fudan:利用大语言模型构建交互式的3d标准工具,利用clip,sam和llm 交互式的形式。通过2d反投3d得到点云标注。
recommend level :中
方向4 - 利用多模态大模型能力做决策及规划或者end2end(22篇,强推荐7篇) [推荐]Talk to the Vehicle: Language Conditioned Autonomous Navigation of Self Driving Cars comment : 2019印度学者iros:算是比较早的把自然语言加入到自动驾驶里的工作了。文章自己提出了一个数据集。然后提出一个wgn的网络来融合感知bev结果和自然语言encoding后的结果输出一个前方大概多少米的大概位置(就是减配版的routing);后面接上一个传统的local planner。整体估计idea比较早,没有跟其他论文方法对比,只是自己做了一些消灭实验。另外本身encoding出来的nlp模块降维比较多,本身还是想把文本的建模难度弱化,也是合理。这可是出在clip文章出来之前的多模态的工作之一了。
recommend level:高,比较早提出引入nlp来做bp
ADAPT: Action-aware Driving Caption Transformer comment : 202302中科大&清华:输入vedio,直接输出control信号。为了加强可解释性,加了文字的描述:主车行为和原因。整体比较简单,也没撒对比。只是证明加了解释性的head后control信号的输出精度会变好。
recommend level :中
ConBaT: Control Barrier Transformer for Safe Policy Learning comment : 202305mit学者:提出conbat,一种策略学习方法,基于transfromer backbone输入state/action能输出对应的embedding,然后输入策略pai head输出结果,然后再送入所谓world model网络得出下一刻的action。整体优化函数利用一些控制理论的东西不太懂。整体偏规划类问题。
recommend level :低
Drive Like a Human: Rethinking Autonomous Driving with Large Language Models comment : 202306上海ai实验室:以当前模块化优化设计为例,列举失效场景的问题,然后提出了一个类人的设计模块思路:可推断,可解释,带记忆。利用感知工具对仿真器的场景进行描述,然后送入gpt3.5推断,如果与人类标注或者其他expert不同,则反馈给gpt3.5,设计成一个记忆模块,然后修正,以提升对长尾问题的结局比例。由于只是提出这个方向和想法,未做具体的工程性实验。
recommend level :中
MTD-GPT: A Multi-Task Decision-Making GPT Model for Autonomous Driving at Unsignalized Intersections comment : 202306同济:利用gpt2的结构来做决策,输入自车和其他车的信号,通过encoder-decoder输出决策信号(stop)等。利用rl来做专家数据的生产。
recommend level :中
Can you text what is happening? Integrating pre-trained language encoders into trajectory prediction models for autonomous driving comment : 202309 德国某大学:也是开放性提出了一个验证,对rastied地图的表达,加入文字的描述后,预测结果会更好
recommend level :低
LINGO-1: Exploring Natural Language for Autonomous Driving comment : wabbi blog
recommend level :未知
Drive as You Speak: Enabling Human-Like Interaction with Large Language Models in Autonomous Vehicles comment : 提出了一个我曾经非常兴奋的一个想法。driver提出promot指定,结合特定模块的结果,利用llm进行reasoning(text by text)后再进行action的输出。整体文章应该也只是一个idea,实验数据也没给提供。
recommend level :低
DILU: A KNOWLEDGE-DRIVEN APPROACH TOAUTONOMOUS DRIVING WITH LARGE LANGUAGEMODELS comment : 202310上海ai实验室:提出dilu,跟之前drive like a human那个小论文有点像。整体分为4个部分:reasoning,reflection(纠正),memory,action。相对之前讲的更详细一点。其中通过reflection来发现badcase从而促进知识学习(memory),类似强化学习里的知识。
recommend level :中
DRIVEGPT4: INTERPRETABLE END-TO-ENDAUTONOMOUS DRIVING VIA LARGE LANGUAGEMODEL comment : 202310 香港大学:引入大语言模型通过标准的3段式来做端到端的决策信号:主车目前帧要干什么,为什么干,预测下一帧主车要干撒。输入层面会把图像vedio token化+额外的bbox token化来表达,再加上action和text的token输入。本文利用llama开源模型来微调的。
recommend level :中
[推荐]Driving with LLMs: Fusing Object-Level Vector Modality for Explainable Autonomous Driving comment : 202310 wayve:利用大语言模型来做端到端预测,区别于drive-gpt4,文章有显式把感知的结果通过vector encoder来做信息交互,然后通过一个vector former来将信息转化为gpt llm能处理的形态,类似adpater。文章提到了整个数据采集标注的方法,通过在仿真里做agent闭环采集实验。整个结果还是分几步可解释性的预测。
recommend level:高,细节描述比较清楚
Talk2BEV: Language-enhanced Bird's-eye View Maps for Autonomous Driving comment : 202311 印度学者:利用lvlm来对bev图上的每个object做text的desciption增强,然后再送入到llm中,做一些query-answering的测试。并未完全设计到端到端的控制当中。但是相对其他paper专门对ojbect做增强。但是这样会使整个的计算量变得更大一些。
recommend level :中
LANGUAGEMPC: LARGE LANGUAGE MODELS AS DE-CISION MAKERS FOR AUTONOMOUS DRIVING comment : 202310清华:提出languagempc,通过引入大语言模型的cot推理能力,将整个理解和规划任务拆解成很多子任务,比如某个障碍物该不该响应,静态场景的表达,与mpc控制器的联合训练等等。整体文章好像没写感知sensor的检测是怎么来的。代码也没有开源。
recommend level :中
BEVGPT: Generative Pre-trained Large Model for Autonomous Driving Prediction, Decision-Making, and Planning comment : aaai2024, 202310 香港科技大学:bevgpt, 输入感知输出的bev结果(动态加先验地图),然后通过gpt based的网络直接预测出6s后主车的位置&下一帧的bev结果,最后在线构建最小化jerk的非线性优化,来进一步优化得出具体主车的轨迹。具体感知结果如何token化没有讲的很清楚。另外先验的栅格化地图在无图背景下就不能当先验了。文章只和uniad做对比,在lyft数据集上做的验证。
recommend level :中
GPT-DRIVER: LEARNING TO DRIVE WITH GPT comment : 202311 南加州和清华赵行:将大语言模型纳入到轨迹规划中。这篇会将感知和预测的结果token化,送入gpt3.5,生成固定的3段式格式的推理:看到了哪些感知结果/哪些对主车会造成影响/主车的最终估计预测。然后通过finetuning的方式来做做最终的infer决策。
recommend level :中
Drive Anywhere: Generalizable End-to-end Autonomous Driving with Multi-modal Foundation Models comment : 202311 mit: 提出了一种feature级别仿真(类别图像提取的fpn特征)增强,来提高open-set的识别能力。整体链路图像和文本送入到clip等特征器中提取,然后通过策略网络输出控制信号(策略没讲,简单的pid)。文中还说在直行等场景还上车了,3fps。
recommend level :中
On the Road with GPT-4V(ision): Early Explorations of Visual-Language Model on Autonomous Driving comment : 20231109 上海ai实验室botian shi: 一个gpt4v 在ad场景下各个模块的系统测试报告,usal reasoning,challenges remain, particularly in direction discernment, traffic light recognition, vision grounding, and spatial reasoning tasks.
recommend level :中
[推荐]A Language Agent for Autonomous Driving comment : 202312usc&&nvidia: agent-driver提出了一个全部以text来通信的整个ad框架。包含llm和对应的nn模块(特别是感知的动态目标检测,静态感知模块),整体包含 7个大模块:enviromental information/common sense / chain-of-thoughts reasoning / task planning / motion planning/self-reflection。其中环境感知模块是包含uniad里的感知和预测模块处理传感器数据,通过一个叫tool libary的模块(llm-based instruct),类似一个perception-engine模块以dynamic function call的方式提供文字based的结果,比如leading-car/front-car等等信号。common-sense是包含一个可以人为先验设定的text token库和一个包含历史drving-scene的场景库(这些都是提前训练好的,类似rule-base决策的根据交互类型和背景信息来走不同的决策分支)。chain-of-thoughts reasoning接受上游2个模块,做一些推理分析。task planning是一个顶层的high-level的规划结果,比如大概怎么走,以一定的加速度往前走。motion-planning也是接受上游所有输入,综合得出text-based waypoint。最后还加了一个基于优化的兜底轨迹模块,缓解大模型出来的幻觉现象导致的高危事故。整体看来算是比较靠谱和详细的实现思路。但是里面的用到的llm不止一处,每处都要做instrcuct learning(in-context或者finetune),计算量和训练难度都有点大。文章也提到的limitation-时延。整个还是用language的方式去处理规划决策问题,上游感知和预测还是利用uniad或者cnn的方式来做。文章效果是与gpt-driver来对比的。另外规划的测试指标还是开环的(l2轨迹误差和碰撞率)
recommend level:高,把模块化和可解释性拆解的比较细
[推荐]DriveMLM: Aligning Multi-Modal Large Language Models with Behavioral Planning States for Autonomous Driving comment : 202312 上海ai实验室&清华daijifeng:提出了一个直接接原始raw-data,然后输出bp信号,最后接apollo后续模块的闭环验证工作。相比drivelm,直接处理时序sensor data和可输入一些promot,直接输出做出目前bp的原因。整体训练如何阶段性训练没有说的太详细(比如如何处理encoder和decoder的训练节奏),代码还没有放出来。基于llmma开源模型。整个相对于apollo的sfm的bp模块做对比。
recommend level:高,首次闭环验证的工作
[推荐]DOLPHINS: MULTIMODAL LANGUAGE MODEL FOR DRIVING comment : 20231201 nvidia:基于一个vlm模型基于视觉数据+ad 场景数据,做了in-context instruction learning, 使得出来的多模态模型对于ad领域的感知/预测/规划都有一定的reasoning能力,没有实际ad领域的测试
recommend level:高,利用ad数据做了instruct learning工作
[推荐]LMDrive: Closed-Loop End-to-End Driving with Large Language Models comment : 202312港中文&商汤:lmdrive ,一个用llm做planning的工作,区分之前的gptdrvier4等llm来做决策规划端到端的paper,这篇工作能闭环验证,且开放出代码,基于calra软件。原始信号处理还是单独的模块(利用障碍物检测/红绿灯检测/主车waypint预测head来监督),然后接入一些人类的instruction和notice(注意/小心等等)nlp的信号,送入一个llm,然后输出可翻译成控制信号的text,最后利用pid来做控制。整体比较make sense,而且一个小细节,instuction会引入一些带噪声的信息(人类有时候也会说错话)。算是一遍我看了这么多中,比较有深度的paper了。
recommend level:高,多模态输入且闭环验证
[推荐]DriveLM: Driving with Graph Visual Question Answering comment : 202312上海ai实验室:发布了drivelm数据集,并做了一版本baseline。即将自动驾驶分成5个模块,在加上多个障碍物,形成了graph约束。每个模块都通过llm做一些qa的工作,而且各个模块都可以单独训练评测。并把这个数据集搞成了cvpr新的比赛
recommend level:高,baseline工作
方向5 - 端到端联合训练自动驾驶(不一定是大模型)(5篇,强推荐3篇) ALVINN:AN AUTONOMOUS LAND VEHICLE IN A NEURAL NETWORK comment : 1988cmu:利用3层mlp接入图像和毫米波雷达,输出lane fllowing的方向,算是最早的一篇端到端的文章了
recommend level :中
[推荐]ST-P3: End-to-end Vision-based Autonomous Driving via Spatial-Temporal Feature Learning comment : eccv2022 taodacheng&junchiyan等:算是比较早的模块化端到端planning的方案,整体利用纯视觉环视输入。首先多帧多时序的特征融合,然后建模运动的不确定度,通过双对偶网络去做预测,最后通过预测出的特征+预测出的bev地图做planning的轨迹预测,最后通过commond 命令做筛选,通过与前向视觉feature(包含红绿灯)进行refine。整体感知,预测,planning每个模块都有单独的loss监督,感知可以出lane和driving-space(2维上)的,预测也是预测的segmantion结果。各个模块输出结果都有评测对比,另外也做了planner的闭环(carla)实验。整体算是整个联合训练,避免传统间结构化信息的漏缺。
recommend level:高,首次提出端到端联合训练
[推荐]Planning-oriented Autonomous Driving comment : cvpr2023 best paper上海ai实验室(review by 20231231): 整体通过query的方式将自动驾驶里的主要任务都联系起来。检测/跟踪,静态检测,motion prediction/ occ prediction,planning。附录中比较详细的介绍了各个模块的参数细节。整个参数量达到一亿。每个模块的评测都做的比较详细。最后planner的attention 可视化的确是一个亮点。整体算是掀起了模块化训练的开幕。忘记写了是基于什么数据集做的训练了。代码已经开源。
recommend level:高,附件细节描述比较好,代码开源
VAD: Vectorized Scene Representation for Efficient Autonomous Driving comment : iccv2023 地平线:类似uniad,但比uniad更简单的一个端到端的感知预测planing的模块,通过query的方式来共享,但全局都是用vector(query)的方式表达。效果相对uniad差不大,但是会快不少。利用主车的eg0_query与感知motion-query先做交互得query1,后和statcic-map-query做交互得query2,然后结合ego-state, 直接做planning。中间每个模块也会有自己的约束loss,而且planning部分还加了一些先验的loss。但还是一样的,基于开环的测试指标不太具有可比性。
recommend level :中
[推荐]Rethinking the Open-Loop Evaluation of End-to-End Autonomous Driving in nuScenes comment : 202305 百度王井东:很有意思的一篇文章来验证现在基于nuscne的planner开环评价指标的不合理性。文中提出一个只接入主车历史4帧的轨迹状态,和一个high-level的commond信号,过几层mlp,直接预测接下来3秒的waypoints,测试的基本基本跟现在基于感知结果的端到端planning方案差不多。一个闭眼开的控制系统和睁眼开的差不多,想想多荒谬。所以闭环测试planner才是正途。
recommend level:高,专门验证开环评测planning不靠谱
FusionAD: Multi-modality Fusion for Prediction and Planning Tasks of Autonomous Driving comment : 202308 有鹿智能:基于uniad改进做一个融合lidar和vision的端到端系统,改进点:1. 感知加入lidar和时序特融合 2. 层级融合,即预测和planning都接入原始的感知feature 3.预测去掉了先验经验轨迹anchor,而是加入了一个refine 的网络结构来进一步预测displacement(个人感觉用处不大) 4. planning的约束还加入了主车与他车碰撞的loss 5. 最后还利用occ预测的结果利用非线性优化来优化模型出来的轨迹保证合理性和平滑。整体评价下来,感知和预测任务比uniad的效果要好不少,不确定是加了lidar的信息源还是什么。
recommend level :中
1、如您转载本公众号原创内容必须注明出处。
2、本公众号转载的内容是出于传递更多信息之目的,若有来源标注错误或侵犯了您的合法权益,请作者或发布单位与我们联系,我们将及时进行修改或删除处理。
3、本公众号文中部分图片来源于网络,版权归原作者所有,如果侵犯到您的权益,请联系我们删除。
4、本公众号发布的所有内容,并不意味着本公众号赞同其观点或证实其描述。其原创性以及文中陈述文字和内容未经本公众号证实,对本文全部或者部分内容的真实性、完整性、及时性我们不作任何保证或承诺,请浏览者仅作参考,并请自行核实。









 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
