VLA与世界模型在自动驾驶中的核心区别
- 2026-07-01 17:06:58

「自动驾驶终极方案之争」
在高阶自动驾驶技术路线中,VLA与世界模型是两大热门方向,前者主打“交互与即时决策”,后者聚焦“预演与风险预判”,二者看似同源(均服务于智能驾驶决策),但技术逻辑、核心能力差异显著。
在深入比对前,先把所有关键术语讲明白,避免专业门槛阻碍理解。
(一)基础共性术语
1. 自动驾驶决策:智能驾驶系统根据环境信息,判断“该加速、刹车、变道还是停车”的核心动作,相当于人类司机的“大脑思考”环节。
2. 视觉感知:通过车载摄像头、激光雷达、毫米波雷达等传感器,“看清”道路环境(如车道线、障碍物、红绿灯),转化为机器能识别的数据,类似人类的“眼睛”。
3. 端到端/半端到端:技术实现路径。端到端是“输入原始数据(图像、语音)→直接输出控制指令(方向盘转角、油门力度)”,中间无人工写规则;半端到端则保留部分中间处理环节,兼顾灵活性与可控性。
4. 长尾场景:自动驾驶中罕见但可能发生的场景(如前车突然侧翻、道路临时施工、极端天气积水),这类场景实车测试难采集,却是影响安全性的关键。
(二)VLA专属术语
1. VLA:全称“视觉-语言-行动模型(Visual-Language-Action Model)”,核心是把“看环境、懂语言、做动作”三个能力融合,用自然语言作为中间桥梁,连接环境理解与车辆控制,本质是“带语言交互的类人司机AI”。

图2| 理想的VLA路线,来自网络©️【深蓝AI】编译
2. 多模态融合:VLA的核心技术,把视觉传感器采集的“图像特征”(如行人轮廓、车道线形状)与语言模型解析的“语义向量”(如“避开右侧施工区”的指令含义)对齐融合,形成统一的决策依据,类似人类“边看路、边听导航、边判断”的过程。
3. LLM(大语言模型):VLA的“语言大脑”,能解析模糊自然语言指令(如“前面绕一下”),还能生成决策解释(如“因行人横穿,已减速”),解决传统自动驾驶“黑盒决策”(不知道为什么这么动)的问题。
4. 动作生成器(Policy Head):VLA的“执行指令输出模块”,把融合后的决策依据,转化为车辆能直接执行的控制信号(如方向盘转15°、刹车力度30%),相当于“大脑下达指令给手脚”。
(三)世界模型专属术语
1. 世界模型(World Model):本质是自动驾驶系统的“虚拟预演大脑”,通过学习物理世界规律,在机器内部构建一个“数字沙盘”,能模拟道路、车辆、行人的动态变化,提前预判未来场景走向。
2. 反事实预演:世界模型的核心能力,通俗说就是“假如式推演”——“假如前车急刹,我该怎么避?”“假如暴雨积水,轮胎抓地力下降会怎样?”,在虚拟场景中试错,不用实车冒险。
3. 云端场景生成引擎:世界模型的“数据工厂”,在云端生成海量极端/罕见场景(如前车突然Cut-in、山区弯道强光),场景密度是真实世界的1000倍,用于弥补实车测试数据的不足(如华为World Engine)。
4. 因果推理:世界模型理解“事件间逻辑关系”的能力,不是单纯模仿数据,而是能识别“施工围挡→需绕行”“积水路面→减速”的因果,类似人类“知道为什么要这么做”,而非“以前这么做过”。
二者均属于高阶自动驾驶决策技术,目标都是突破传统规则式驾驶的局限,让智能驾驶更安全、更适配复杂场景,具体相同点有3点:
1. 均超越“传统规则式决策”,依赖AI大模型能力:传统自动驾驶靠人工写规则(如“检测到行人距离<5米则刹车”),无法覆盖所有复杂场景;VLA靠LLM的常识推理,世界模型靠物理规律建模,都能处理规则无法覆盖的动态场景(如临时施工、人车混行)。
2. 均以视觉感知为基础输入:两者都需先通过车载传感器采集道路图像、点云数据,提取环境特征(障碍物、车道线),再基于这些数据做后续处理——没有视觉感知的“基础信息”,VLA无法“看懂”环境,世界模型也无法构建虚拟场景。
3. 均服务于L2+及以上级自动驾驶,追求“拟人化/超越人类的安全性”:二者都针对城市场景、高速场景的高阶辅助驾驶(L2+)或自动驾驶(L3),核心诉求要么是让驾驶动作贴合人类习惯(VLA),要么是通过预演降低事故率(世界模型),最终目标是超越人类驾驶的安全阈值。
二者的差异贯穿“本质定位、技术逻辑、能力侧重”全链条,用表格能清晰看清,后续再逐一展开解读:
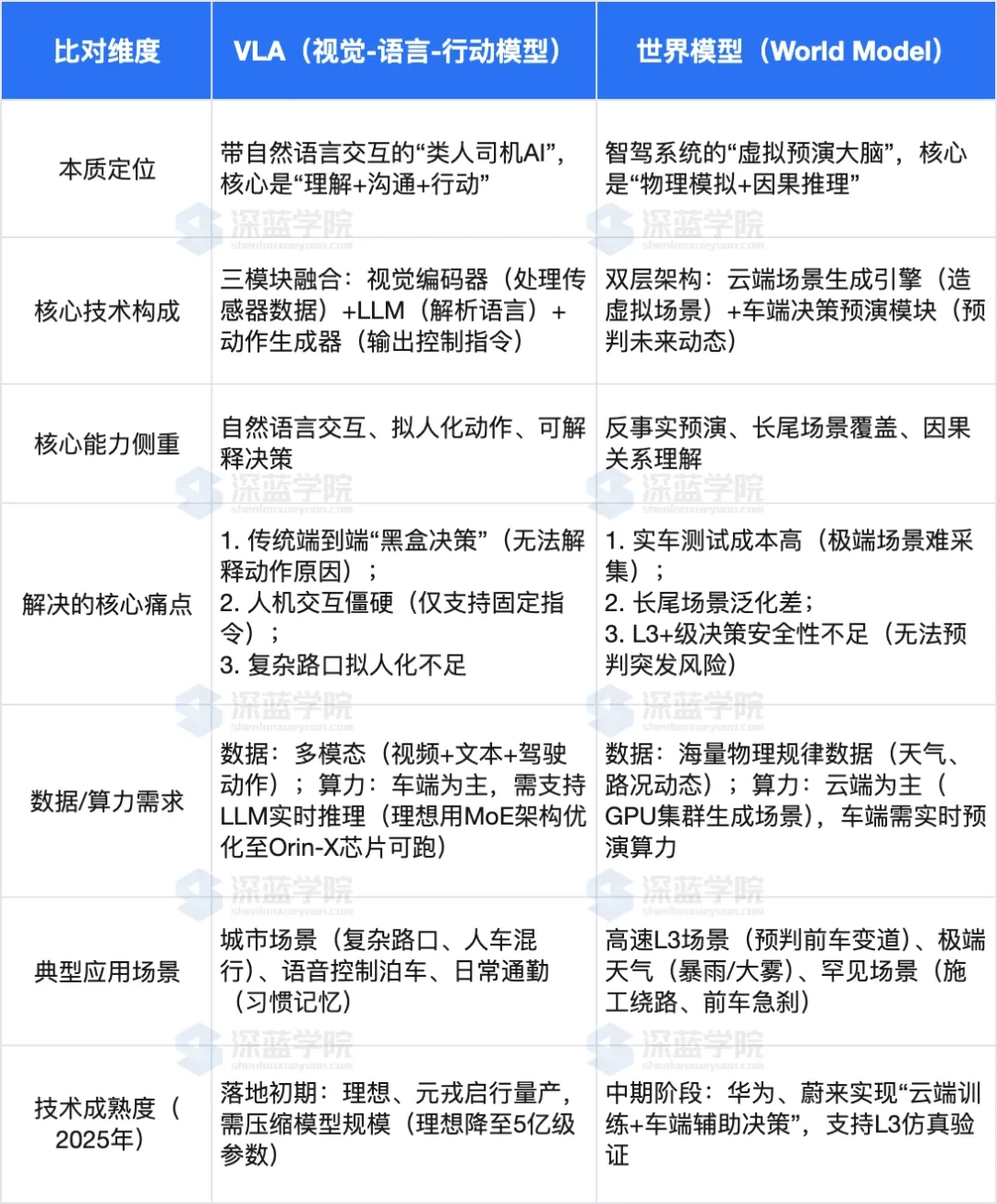
(一)本质定位:“类人交互”vs“虚拟预演”
VLA的核心是“模仿人类司机的交互与决策习惯”——不仅能像人一样看路、做动作,还能听懂模糊语音指令(如“带我回家”“前面绕开障碍”),甚至能解释决策原因(如“因右侧有施工,将向左变道”),本质是“能沟通、可理解的AI司机”。它解决的是“人机信任”问题,让用户敢用、愿意用智驾功能。
世界模型的核心是“给智驾系统造一个‘虚拟训练场’”——它不侧重和人交互,而是聚焦“提前预判风险”。比如在高速上,它能实时预演未来120秒内前车、后车的可能轨迹,提前识别“前车可能急刹”的风险,提前调整车速,本质是“未雨绸缪的预演大脑”。它解决的是“安全冗余”问题,弥补实车测试无法覆盖所有风险的短板。
(二)技术逻辑:“语言为桥”vs“物理为核”
VLA的技术逻辑是“多模态融合+端到端输出”:先通过视觉编码器处理摄像头/雷达数据,提取环境特征;再用LLM解析自然语言指令(导航、用户语音),转化为语义信息;最后通过交叉注意力技术对齐视觉与语言信息,由动作生成器直接输出控制指令。整个过程以“语言”为中间媒介,连接“看”和“动”,不用人工拆分感知、决策、规划环节。
世界模型的技术逻辑是“物理建模+虚实结合”:云端场景生成引擎基于物理规律,生成海量极端场景(如暴雨积水、前车突然Cut-in),用于训练模型;车端模块则实时接收传感器数据,在虚拟沙盘里还原当前场景,预演不同动作的结果(如“减速能避撞,加速会追尾”),再输出最优决策。整个过程以“物理规律”为核心,靠虚拟预演优化决策安全性,而非依赖数据统计匹配。
(三)能力短板:各有局限,互补性强
VLA的短板在于“极端场景泛化弱、依赖视觉精度”,这一点可用禅宗“以手指月”的典故精准概括。《楞严经》中记载“如人以手指月示人,彼人因指,当应看月”,典故的核心是:手指只是指向月亮(真理、事物本质)的工具,若执着于手指本身,反而会忽略月亮的真实模样。放在VLA技术中,自然语言就如同“手指”,道路环境的物理本质、潜在风险如同“月亮”,VLA的核心矛盾恰恰是“执着于手指,而难见月亮”。
语言具有高度的概括能力也就是抽象能力,但是同样因为这种抽象能力,失去了或者弱化了对具体场景的细化。这也是为什么人跟人用语言交流时,容易听不懂。因为听话的人可能因为自己根本就没有经历过那种场景,在头脑中在记忆中找不到对应物,所以根本听不懂对方在说什么。
具体而言,VLA以自然语言为中间桥梁连接环境与控制,语言本是辅助理解的工具,但模型却高度依赖这一“手指”:
一方面,它靠LLM解析语言语义、生成决策,却难以穿透语言表象触及物理本质。比如用户说“前面绕一下”,VLA能解析指令并执行变道,但无法像人类一样理解“绕开”背后的核心逻辑——是避开障碍物、规避风险,还是贴合驾驶习惯,一旦语言指令模糊或场景超出数据范畴(如车辆侧翻这类无语言标注的极端情况),就会因找不到“手指”对应的参照,陷入决策困境。这就像有人只盯着手指的纹路,却不知手指指向的月亮才是核心,当手指晃动或消失,便失去了判断方向的能力。
另一方面,VLA的多模态融合以视觉特征与语言语义对齐为核心,若视觉感知精度下降(如雨雾、强光天气),语言这根“手指”就失去了精准指向“月亮”的基础。此时VLA要么执着于残缺的视觉信息强行匹配语言语义,导致决策偏差(如误将积水认作路面,执行正常车速指令);要么因信息不匹配陷入卡顿,无法应对动态风险。此外,模型压缩适配车端算力后,方言、复杂指令的解析能力损耗,相当于“手指”本身出现残缺,更难精准指向“月亮”,进一步放大了对工具的依赖缺陷。这种“重工具、轻本质”的特性,让VLA在无数据支撑的极端场景中,难以突破“见指不见月”的局限,决策可靠性大幅下降。
世界模型的短板在于“交互弱、仿真与现实有鸿沟”:它几乎不支持自然语言交互,用户无法用语音指令控制,人机协同体验差;且虚拟场景再逼真,也无法100%还原真实世界的物理细节(如轮胎与地面的摩擦力差异),可能导致预演结果与实际情况偏差;同时研发门槛极高,需自建云端引擎与车端芯片协同架构,中小车企难以复制(华为2024年投入超100亿元研发)。

图3| 华为的世界模型路线,来自网络©️【深蓝AI】编译
几乎毫无疑问的,世界模型研究路线远比VLA路线要昂贵得多,因为世界模型回避了和无法借用语言的高度概括能力,只能笨办法真实采集所有的场景(几乎所有的场景,即使有数据生成)。这也是为什么华为的评价VLA是在“取巧”。
目前行业无绝对“最优路线”,车企多根据自身技术积累选择策略,也体现了二者的互补性:
1. VLA为主,世界模型辅助:理想汽车是代表,以MindVLA为核心,实现语音控制泊车、复杂路口拟人化驾驶,同时用世界模型生成虚拟场景,优化极端天气下的决策精度,兼顾用户体验与安全性。
2. 世界模型为主,拒绝纯VLA:华为坚持该路线,推出WEWA架构(世界引擎+世界行为模型),靠云端生成海量难例场景,车端实时预演120秒动态,主打高速L3级安全决策,认为这是实现真正自动驾驶的终极方案。
3. 融合路线:蔚来将VLM(视觉语言模型)与世界模型(NWM)结合,用VLM识别路牌、施工标识的文本信息,用世界模型预演216种可能轨迹,兼顾交互能力与预判能力,适配城市NOA场景。
VLA与世界模型不是“非此即彼”的竞争关系,而是各有侧重、可互补的技术:VLA解决“人机交互友好、决策可解释”的问题,让智驾更贴近用户习惯;世界模型解决“安全冗余、长尾场景覆盖”的问题,让智驾更可靠。
最好的配合是世界模型作为地基,VLA作为第二层楼结合在一起。
任何读过Claude Shanon的《通信的数学原理》一文的理工科读者,在理解香农的信道、信息熵和信息传送极限时,都会发现,所谓的通信根本不是把需要通信的东西整个打包,从一端通过信道发送到另外一端,好让对方从无到有。
通信是假设双方都有一模一样的物品仓库。通信仅仅是告诉另外一方他已经拥有的某一件东西的编号是什么,让对方去按照编号寻找自己已经有的东西。如果对方本身就不拥有这件东西,通信就会失效。不理解这一点,就根本读不懂通信原理。
在很多特工电影当中,传递的信息是某本书的第几几几号字,然后又第几几几号字,把这些字拼在一起就是秘密信息。通信不是把书给别人,而是仅仅告诉他是特定的书上面的哪几个字。如果别人没有这本书,就无法解密。这是通信的典型场景。当然,还有韦小宝的四十二章经也是一样的。
而VLA中的L语言作为大模型内的通信工具就有这个毛病---如果接收方,比如决策模块根本就没有见过语言所描述的这个场景,那么它就不能很好地处理这个场景,只能依靠泛化。而世界模型的视觉场景就不存在“不知所指”的问题,除非是训练没见过这种场景,否则一定能理论上精准地处理好场景。
未来高阶自动驾驶的终极形态,大概率是“世界模型生成虚拟场景训练VLA,VLA处理实时交互与决策,世界模型同步预演风险兜底”的融合模式——既让用户能自然控制车辆,又能通过预演规避所有潜在风险,真正实现“安全、智能、易用”的自动驾驶。
审编|阿蓝
商务推广/稿件投递请添加:xinran199706(备注商务合作)


· 计划周期:深蓝学院将以3个月为一个周期,建立工程师&学术研究者的「同好社群」
· 覆盖方向:自动驾驶、具身智能(人形、四足、轮式、机械臂)、视觉、无人机、大模型、医学人工智能……16个热门领域
扫码添加阿蓝
选择想要加入的交流群即可
(按照提交顺序邀请,请尽早选择)
👇

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 插混和增程打起来了,18万级SUV不再拼配置而是看谁更懂你家日常
- 老福特终于“挺不住了”,5米大7座SUV跌到13.7万,2.0T+8AT最大378牛米,老司机:还得是老伙计靠谱.
- 实测10万级电混SUV:一周不用充电,油耗3L,家用真的“闭眼入”?
- 小鹏2026新车大爆料 全新增程SUV领衔 MONA双车出击 野心不止于此
- 大结局!2025年方盒子SUV销量榜!大狗夺冠,豹5第7,普拉多第20
- 2026入手的SUV,6款非常不错,油车和新能源都有
- 这款中型SUV不足22万起!配激光雷达,轴距近3米,增程/纯电可选
- 10万出头买国产硬派SUV,空间领先同级,要啥有啥!
- 好看、好开、好智能的新一代三好SUV
- 极氪全新SUV官方预告图来了!或定名“极氪9S”,最快1月份亮相
