🚗 自动驾驶“副驾驶”能力大考来了!还在用GPT-4o看图说话来评估自动驾驶模型?同济大学团队告诉你,这远远不够!他们推出了一个覆盖63个国家、3847小时驾驶视频的“终极考卷”——ScenePilot-Bench,专门用来“拷问”视觉语言模型在自动驾驶场景下的真实能力。想知道你的模型是“老司机”还是“马路杀手”?这个基准说了算!👇扫码加入「龙哥读论文」知识星球,第一时间获取这类硬核论文解读、数据集和代码资源,让你的研究快人一步!

龙哥推荐理由:
这篇论文提供了一个极其全面和实用的自动驾驶视觉语言模型评估框架。它不仅贡献了一个规模空前、地理多样性丰富的驾驶视频数据集,更重要的是,它设计了一套从语义理解到空间几何、再到运动规划的“四轴”评估体系,直击当前VLM在自动驾驶应用中的核心痛点——“会说”不等于“会开”。对于从事自动驾驶、具身智能或多模态研究的同学来说,这既是评估自己模型的“标尺”,也是未来模型改进的“指南针”。
原论文信息如下:
论文标题:
ScenePilot-Bench: A Large-Scale Dataset and Benchmark for Evaluation of Vision-Language Models in Autonomous Driving
发表日期:
2026年01月
发表单位:
同济大学(College of Automotive and Energy Engineering, Tongji University)等
原文链接:
https://arxiv.org/pdf/2601.19582v1.pdf
开源代码链接:
https://github.com/yjwangtj/ScenePilot-Bench
开源数据集链接:
https://huggingface.co/datasets/larswangtj/ScenePilot-4K
自动驾驶“副驾驶”需要怎样的评估标尺?
想象一下,你让GPT-4o看一段驾驶视频,它能给你编一段栩栩如生的故事:“阳光明媚,前方有一辆蓝色轿车,旁边有行人走过...” 🚗 听起来很棒,对吧?
但如果你接着问它:“那辆蓝色轿车离我们多远?它正在加速还是减速?我们现在应该刹车还是变道?” 🤔 很多所谓的“智能”模型可能就开始胡言乱语,或者给出完全不符合物理规律的答案了。
这就是当前自动驾驶领域应用视觉语言模型(Vision-Language Models, VLMs)面临的核心矛盾:一个模型“会说”不等于“会开”。在实验室里对答如流,上了路可能就是“马路杀手”。💀
究其原因,是缺少一把量身定制的“标尺”。现有的很多评估要么只测语义描述(“看图说话”),要么只测目标检测(“找东西”),没有把语言理解、空间几何、动态规划和安全风险捏合在一起去全面考核。
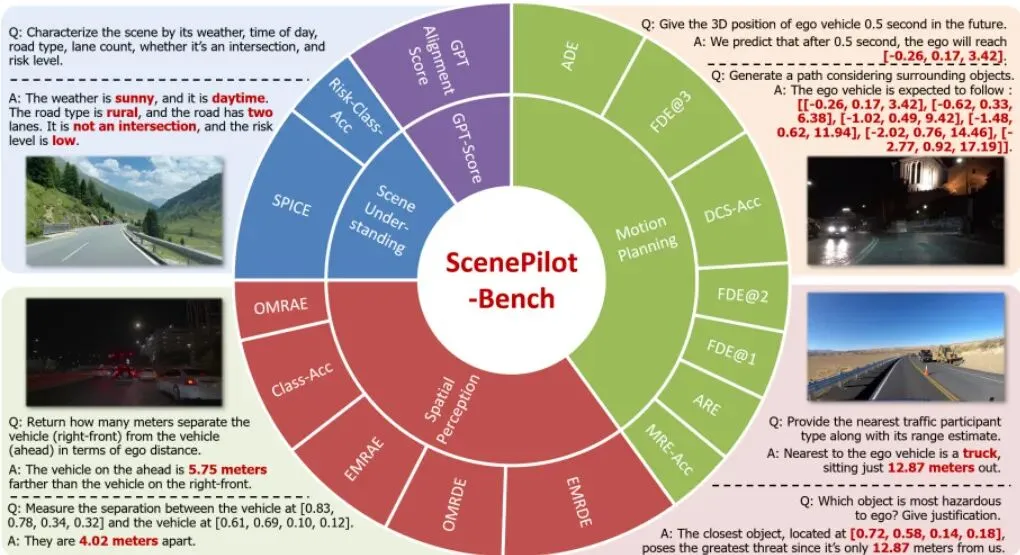
同济大学的团队看到了这个问题,他们心想:是时候给这些自动驾驶的“AI副驾驶”们出一套终极“驾考”试题了!于是,他们打造了ScenePilot-Bench。图1:ScenePilot-Bench基准的整体结构。基于ScenePilot-4K数据集,该基准强调自动驾驶中VLM评估的四个关键指标:场景理解、空间感知、运动规划和GPT分数。如图1所示,这把“标尺”包含两大核心:一个海量且多样的数据集(ScenePilot-4K),和一个精心设计的四轴评估体系。它要回答的问题是:一个VLM,不仅要“眼观六路”(场景理解),还要“心中有图”(空间感知),更要“手脚协调”(运动规划),最后还得“表达清晰”(GPT分数评估语义对齐)。超越KITTI和Waymo:ScenePilot-4K数据集有何过人之处?
好的评估,离不开好的数据。以前的经典数据集,像KITTI、Waymo、nuScenes,都是业界的里程碑。但它们主要服务于传统的感知和预测任务,对于评估VLMs这种需要语言与视觉深度结合的模型,就显得有些“营养不良”了。
ScenePilot-4K的“过人之处”可以用三个词概括:海量、多样、对齐。
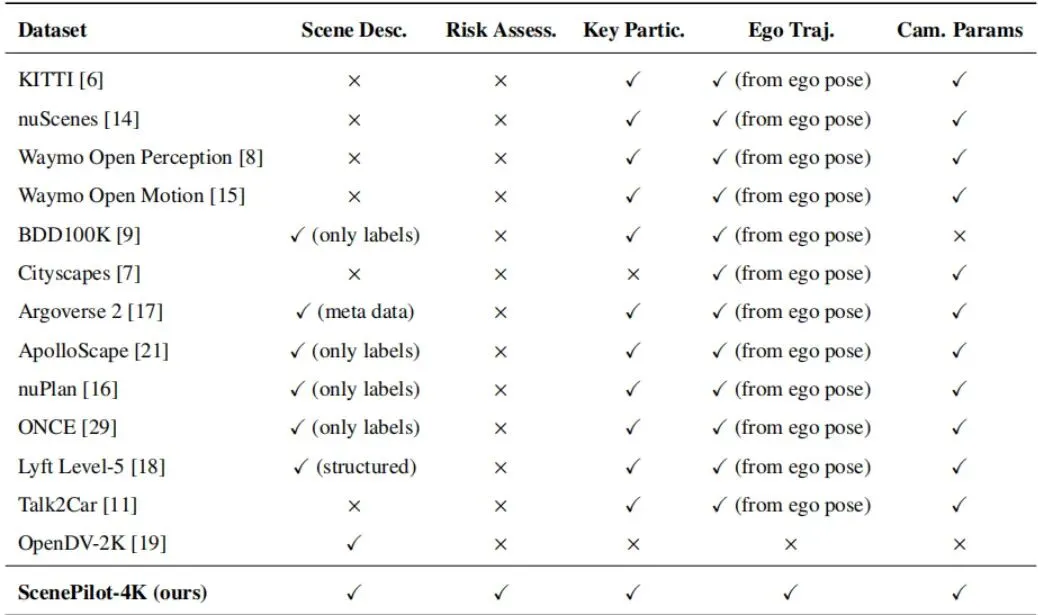 表1:不同基线数据集与我们提出的ScenePilot-4K数据集的比较。(a)与规模相关的统计信息。(b)标注可用性。
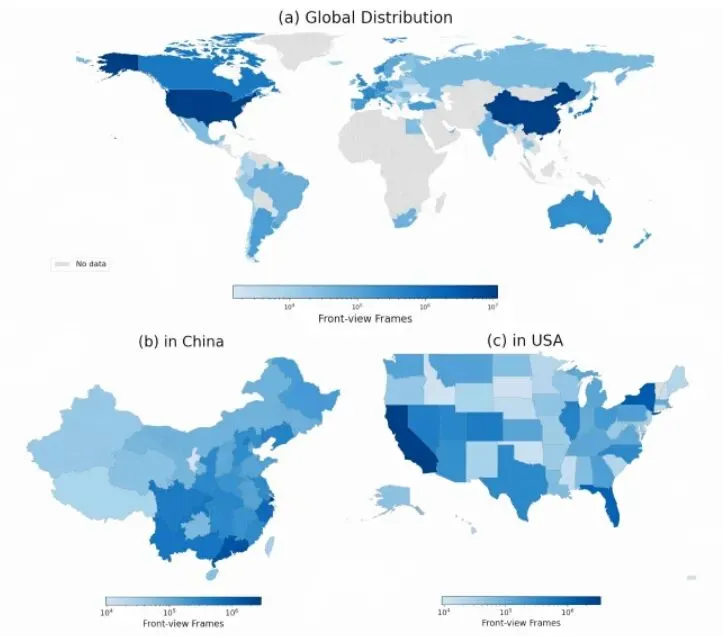
如表1(a)所示,ScenePilot-4K包含了3847小时的第一人称驾驶视频,总计约2770万帧。这个时长什么概念?不吃不喝连续看160天!更夸张的是它的地理多样性,覆盖了全球63个国家和地区,1210个城市。与之相比,KITTI只在德国1个城市采集,Waymo主要在美国,nuScenes也仅覆盖2个国家。图2:ScenePilot-4K数据集的地理分布。该数据集覆盖了大多数发达国家以及基础设施相对完善的的国家和地区。
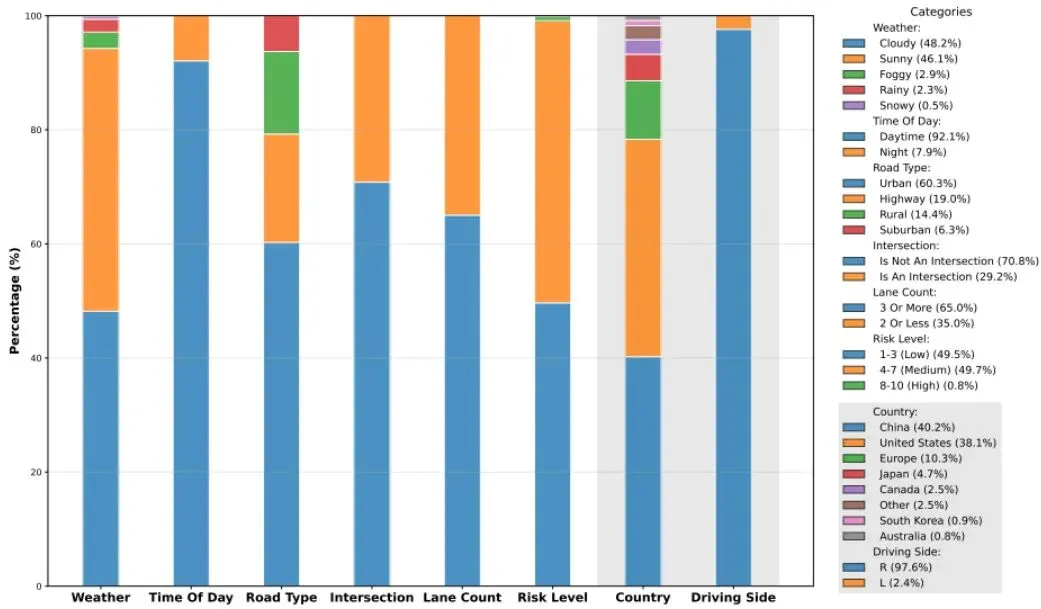
这意味着什么?意味着模型能见到各种奇奇怪怪的路况、交通标志、驾驶习惯。日本的窄巷、美国的宽马路、欧洲的环岛、东南亚的摩托车海……只有见过足够多的“世面”,模型才不容易在陌生环境里“懵圈”。图3:ScenePilot-4K数据集统计:场景属性和驾驶国家的分布。该图总结了ScenePilot-4K数据集中场景属性和地理覆盖的整体分布。
从图3可以看到,数据涵盖了晴天、雨天、夜晚等多种天气和时间,以及城市道路、高速公路等不同场景,风险等级也呈长尾分布(高风险场景虽少但关键)。这保证了评估的全面性和对极端情况的覆盖。
光有数据量还不够,关键在于标注的质量和丰富度。如表1(b)所示,ScenePilot-4K是首个在同一视频片段上同时提供五种对齐标注的数据集:1. 场景描述:用自然语言描述天气、路况、关键事件等。2. 风险评估:标注当前片段的危险等级(低、中、高)。3. 关键参与者:用检测框标出车辆、行人、自行车等。以往的很多数据集,可能只有检测框,或者只有轨迹。而ScenePilot-4K把语义、安全、物体、几何、运动全打通了。这使得我们能够问出非常综合的问题,比如:“描述当前场景(语义),并判断风险(安全)。前方那辆卡车(物体)距离我们大概多少米(几何)?我们接下来3秒是加速还是转向(运动)?”
表1:不同基线数据集与我们提出的ScenePilot-4K数据集的比较。(a)与规模相关的统计信息。(b)标注可用性。
如表1(a)所示,ScenePilot-4K包含了3847小时的第一人称驾驶视频,总计约2770万帧。这个时长什么概念?不吃不喝连续看160天!更夸张的是它的地理多样性,覆盖了全球63个国家和地区,1210个城市。与之相比,KITTI只在德国1个城市采集,Waymo主要在美国,nuScenes也仅覆盖2个国家。图2:ScenePilot-4K数据集的地理分布。该数据集覆盖了大多数发达国家以及基础设施相对完善的的国家和地区。
这意味着什么?意味着模型能见到各种奇奇怪怪的路况、交通标志、驾驶习惯。日本的窄巷、美国的宽马路、欧洲的环岛、东南亚的摩托车海……只有见过足够多的“世面”,模型才不容易在陌生环境里“懵圈”。图3:ScenePilot-4K数据集统计:场景属性和驾驶国家的分布。该图总结了ScenePilot-4K数据集中场景属性和地理覆盖的整体分布。
从图3可以看到,数据涵盖了晴天、雨天、夜晚等多种天气和时间,以及城市道路、高速公路等不同场景,风险等级也呈长尾分布(高风险场景虽少但关键)。这保证了评估的全面性和对极端情况的覆盖。
光有数据量还不够,关键在于标注的质量和丰富度。如表1(b)所示,ScenePilot-4K是首个在同一视频片段上同时提供五种对齐标注的数据集:1. 场景描述:用自然语言描述天气、路况、关键事件等。2. 风险评估:标注当前片段的危险等级(低、中、高)。3. 关键参与者:用检测框标出车辆、行人、自行车等。以往的很多数据集,可能只有检测框,或者只有轨迹。而ScenePilot-4K把语义、安全、物体、几何、运动全打通了。这使得我们能够问出非常综合的问题,比如:“描述当前场景(语义),并判断风险(安全)。前方那辆卡车(物体)距离我们大概多少米(几何)?我们接下来3秒是加速还是转向(运动)?”
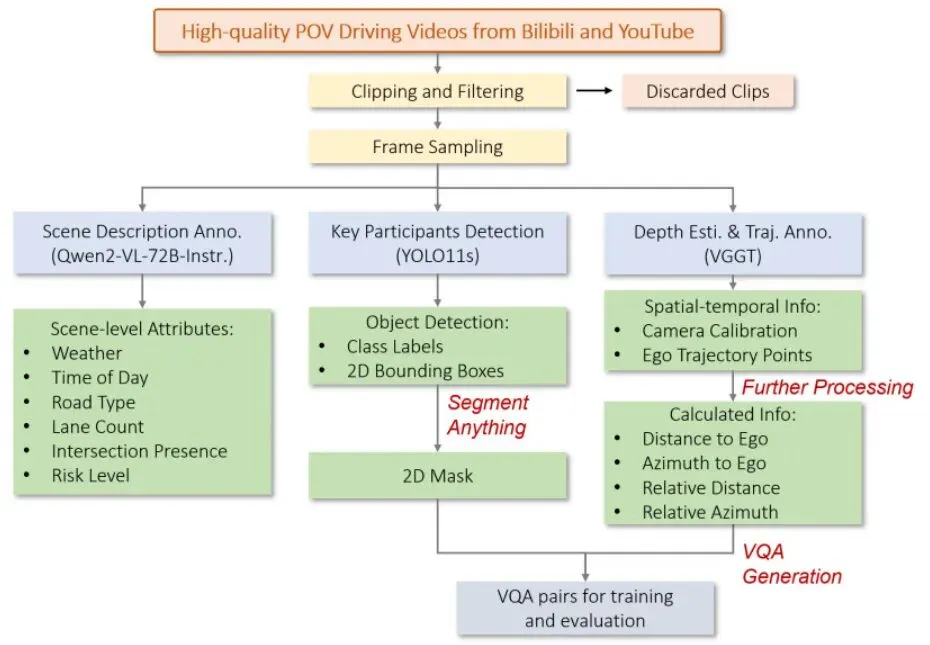 图4:ScenePilot-4K数据集的高质量标注流程。
手动标注这么大规模的数据是天方夜谭。论文采用了自动化流水线(图4):· 场景与风险:用强大的VLM(Qwen2-VL-72B)自动生成文字描述和风险等级。· 物体检测:用YOLO11s检测出各类交通参与者。· 几何与轨迹:这是核心黑科技!使用一个叫VGGT(Visual Geometry Grounded Transformer)的模型,仅从单目视频就能估计出相机参数和每一帧车子的精确位置。有了相机位置,就能计算出自车轨迹。公式很简单:用后面每一帧相机的位置减去第一帧的位置。
图4:ScenePilot-4K数据集的高质量标注流程。
手动标注这么大规模的数据是天方夜谭。论文采用了自动化流水线(图4):· 场景与风险:用强大的VLM(Qwen2-VL-72B)自动生成文字描述和风险等级。· 物体检测:用YOLO11s检测出各类交通参与者。· 几何与轨迹:这是核心黑科技!使用一个叫VGGT(Visual Geometry Grounded Transformer)的模型,仅从单目视频就能估计出相机参数和每一帧车子的精确位置。有了相机位置,就能计算出自车轨迹。公式很简单:用后面每一帧相机的位置减去第一帧的位置。
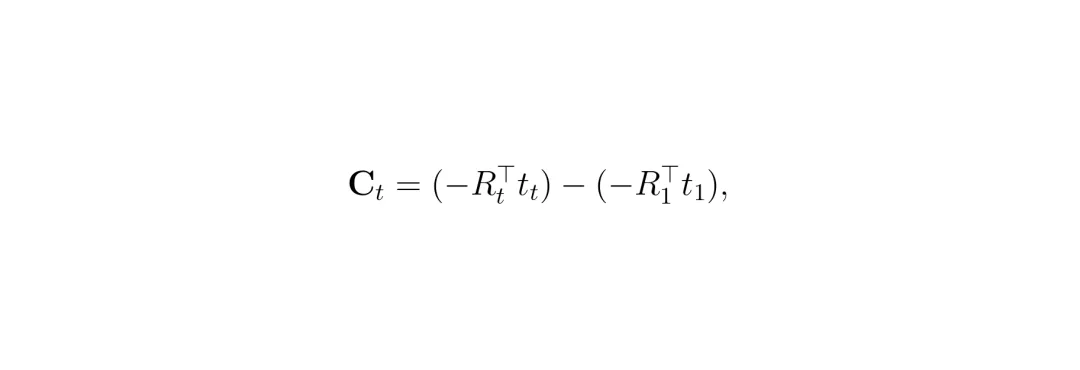 公式:相机中心位置计算。Ct = (-RtT * tt) - (-R1T * t1)
其中,R和t是相机的外参(旋转和平移),下标t代表第t帧,下标1代表第一帧。这样得到的就是在第一帧坐标系下的位移。
更进一步,结合深度估计,可以将2D的检测框“提升”到3D空间,估算出物体与自车的距离和方位角,甚至物体之间的距离。所有计算都是自动化的,保证了标注规模与一致性。
公式:相机中心位置计算。Ct = (-RtT * tt) - (-R1T * t1)
其中,R和t是相机的外参(旋转和平移),下标t代表第t帧,下标1代表第一帧。这样得到的就是在第一帧坐标系下的位移。
更进一步,结合深度估计,可以将2D的检测框“提升”到3D空间,估算出物体与自车的距离和方位角,甚至物体之间的距离。所有计算都是自动化的,保证了标注规模与一致性。从语义到轨迹:四轴评估体系如何全面“拷问”视觉语言模型?
有了高质量的数据集,接下来就是设计“考题”和“评分标准”了。ScenePilot-Bench将评估分解为四个维度,相当于四个科目,对VLM进行全方位“拷问”。
· 精炼版SPICE:评估模型生成的场景描述与真实描述在关键语义要素上的一致性。比如都提到了“晴天”、“十字路口”、“公交车”,那就得分高。· 风险分类准确率:直接看模型判断的“低、中、高”风险等级对不对。这是安全相关的核心能力。这科考的是微观几何关系的理解,是传统VLM的薄弱环节。· 物体分类准确率:基本能力,认出那是车、是人还是自行车。· 空间推理误差:重点来了!这里有一系列“烧脑”的几何题:—— EMRDE/EMRAE(与自车的相对距离/角度误差):模型估计的“那辆车离我50米,在我左前方30度”,和真实值差多少?—— OMRDE/OMRAE(物体间的相对距离/角度误差):“行人A和自行车B之间相距3米”,模型估计得准不准?这考验对复杂交互场景的理解。这科最接近“实际开车”,考的是动态决策和轨迹生成。· 元动作预测:让模型判断未来几秒,自车是加速、刹车、左转还是右转?论文根据真实轨迹的加速度和航向角变化,定义了6种元动作(表2)。· 轨迹规划:让模型直接生成未来1秒、2秒、3秒的自车位置。然后用ADE(平均位移误差)和FDE(最终位移误差)来衡量精度。这是规划任务的经典指标。前面三科都是客观题。这一科是“主观论述题”,用另一个强大的AI(GPT-4o)来评判模型回答的语义连贯性、合理性和与问题的对齐程度。有些回答可能数字上不精确,但描述的逻辑是通顺合理的,这个分数能捕捉到这一点。
不同指标单位不同,有越高越好(如准确率),也有越低越好(如误差)。为了得到一个总分,论文设计了一套归一化和加权方案。
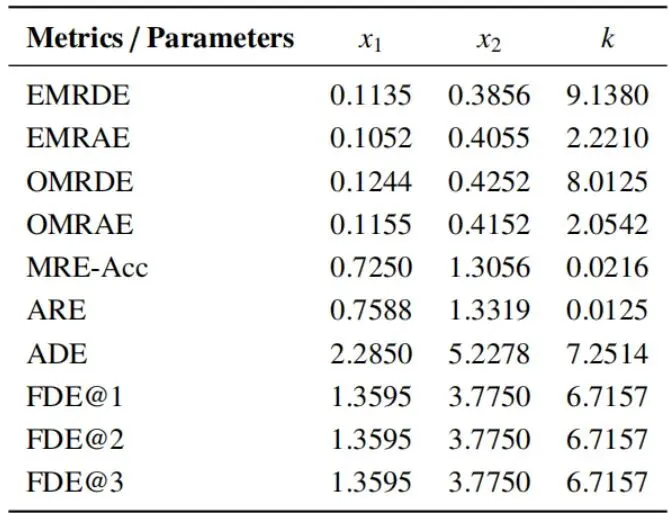
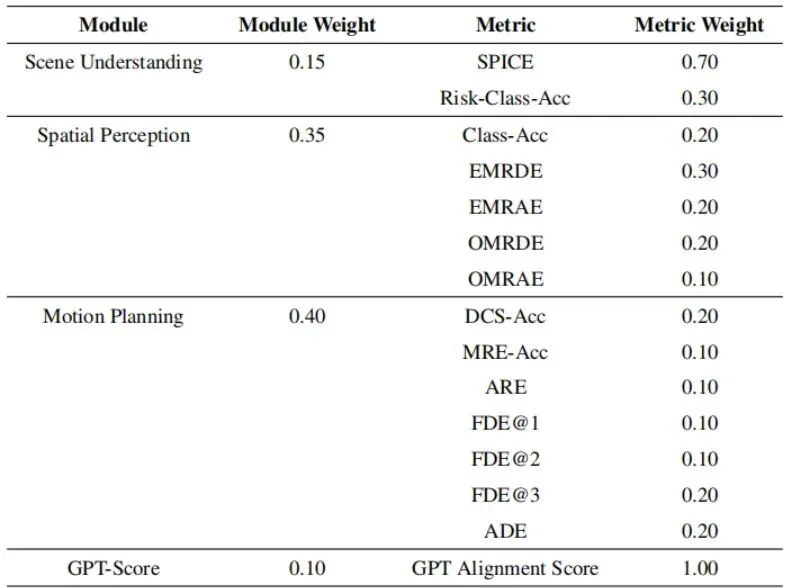
简单说,就是把所有分数都映射到0-100分。对于误差类指标,采用分段函数:误差小的给满分,误差中等的线性扣分,误差巨大的则指数级严厉扣分(因为自动驾驶中大误差不可接受)。表3列出了各个误差指标的具体映射参数。最后,根据每个能力模块对自动驾驶安全的重要性进行加权(表4)。可以看出,空间感知(权重0.35)和运动规划(权重0.4)占了最大头,这体现了基准的导向:光会“说”不行,必须“感知得准”、“规划得稳”。表4:ScenePilot-Bench基准评估框架的加权结构。实验结果揭示:通用大模型与专用模型谁更胜一筹?
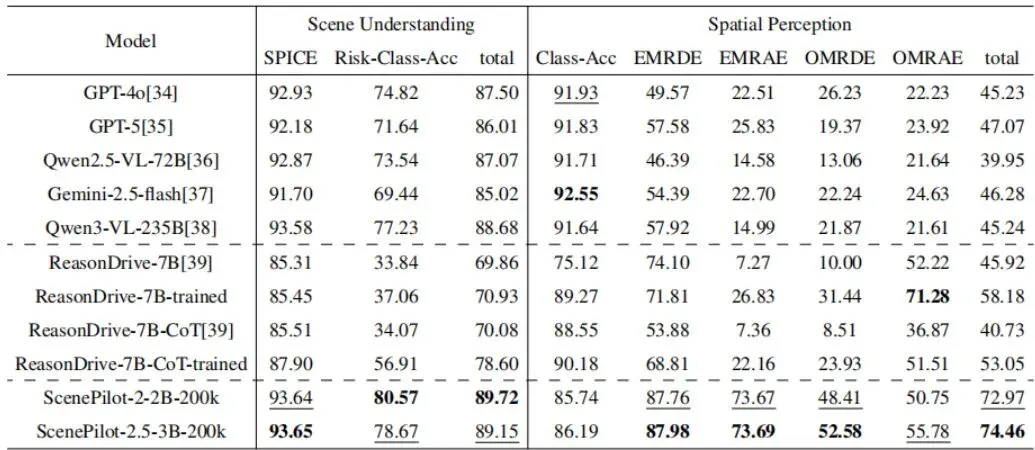
考卷出好了,是时候找一批“考生”来测测了。论文测试了三类模型:1. 通用巨无霸:GPT-4o, GPT-5, Qwen2.5-VL-72B, Gemini-2.5-flash等。它们知识渊博,但未经驾驶特训。2. 驾驶专科生:ReasonDrive-7B及其微调变体。这是专门为驾驶推理设计的小模型。3. 本数据集培养的“优等生”:直接用Qwen系列骨干模型在ScenePilot-4K上微调得到的ScenePilot模型。表5:各种VLM在ScenePilot-Bench基准上的比较。
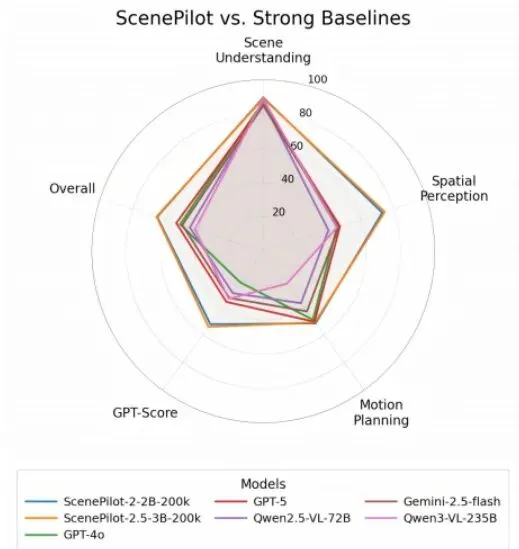
表5(及对应的图5)展示了详细的评测结果,信息量巨大,我们挑重点看:图5:在ScenePilot-4K数据集上微调的Qwen系列模型与基线模型(商业和大规模开源VLM)的直观性能比较。· 通用大模型:“场景理解”科目得分很高(SPICE > 92),说明它们语义描述能力确实强悍。但一到“空间感知”和“运动规划”就露馅了,分数大幅下滑。尤其是运动规划,很多模型的元动作预测准确率(DCS-Acc)只有15%左右,跟瞎猜差不多😂。结论:它们是好“解说员”,但不是好“司机”。· 驾驶专科模型:ReasonDrive-7B经过本数据集微调后,在“运动规划”上表现突出,轨迹误差(FDE, ADE)非常小。这说明专业设计和针对性训练有效。但它其他科目的成绩并不均衡。· ScenePilot微调模型:这才是“全能型选手”!以参数量仅3B的ScenePilot-2.5-3B为例,它在保持高水平场景理解(SPICE 93.65)的同时,空间感知能力碾压通用大模型,运动规划也表现稳健。最终,它以65.37的总分位列第一,超过了所有参数量大它几十倍的通用模型。这个结果传递了一个清晰的信息:高质量的领域专用数据,能让一个中等规模的模型激发出超越通用巨模型的领域特定能力。对于自动驾驶这种垂直领域,盲目追求模型规模不如精心构建训练数据。跨域泛化挑战:模型如何应对“左舵”与“右舵”的切换?
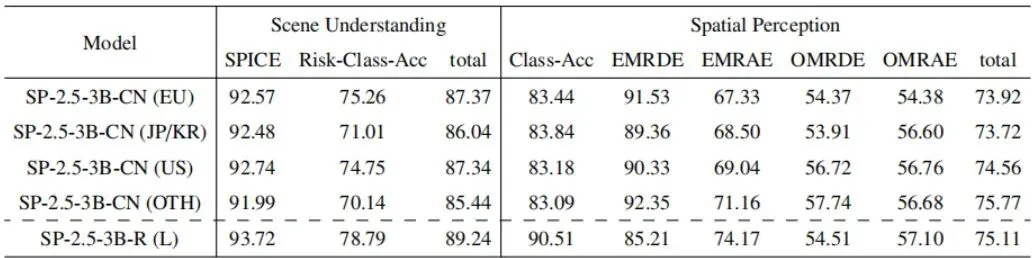
一个只在上海训练出来的“老司机”,到了伦敦或者东京,还能安全驾驶吗?这就是跨域泛化问题。ScenePilot-Bench专门设计了两个“变态”测试来检验这一点:1. 留一国出局(LOCO):只用中国数据训练,然后分别去考欧洲、日韩、美国等完全没见过的地区。2. 右舵转左舵(R→L):只用靠右行驶的国家(如中、美)数据训练,去考靠左行驶的国家(如英、日)。· 场景理解很“稳”:无论到哪里,描述天气、路况这种全局语义能力基本不受影响。说明模型学到了通用的视觉概念。· 风险评估有点“飘”:风险判断的准确性有所下降。这很合理,因为不同地方的交通规则、司机行为不同,对“风险”的定义也不同。· 运动规划最“慌”:当面对完全相反的驾驶规则(右舵转左舵)时,模型在“元动作预测”上表现最差。它可能下意识地认为车应该靠右走,遇到左舵场景的决策就容易出错。但有趣的是,“轨迹预测”的误差相对没那么大,因为物理运动规律(如加速度、转弯曲率)是全球通用的。这个实验深刻地揭示:要想打造一个真正全球可用的自动驾驶AI,必须在训练数据中纳入足够多样的地理和规则信息。同时也说明了ScenePilot-4K数据集在地理多样性上的价值——它本身就是一个应对泛化挑战的“解药”原料库。
龙迷三问
VLM在自动驾驶中到底扮演什么角色?是直接控制车辆吗?目前主流观点中,VLM更多是作为“副驾驶”或“协作者”,而非端到端的直接控制器。它的作用是提供场景叙事、风险解读、关键目标识别和决策先验,尤其是在传统规则或学习模型难以处理的长尾、复杂场景中,为下游规划模块提供可解释的输入和辅助决策。本论文的基准也是基于这种“开环”评估范式。
SPICE、ADE、FDE这些指标具体是什么意思?
SPICE(Semantic Propositional Image Caption Evaluation):语义命题图像描述评估。它通过比较生成描述和真实描述解析出的关键要素(物体、属性)集合的重合度来打分,越高说明语义一致性越好。
ADE(Average Displacement Error):平均位移误差。预测的整个轨迹上所有点,与真实轨迹对应点的平均距离。衡量整体轨迹的吻合度。
FDE(Final Displacement Error):最终位移误差。预测轨迹终点与真实轨迹终点的距离。特别关注最终位置的准确性,在规划中很重要。
这个基准和数据集对我有什么实际用处?如果你是研究者,它可以作为:1)评估工具:客观衡量自己模型在驾驶多模态任务上的真实水平。2)训练资源:利用其大规模、多标注的数据来微调或预训练自己的VLM,提升领域能力。3)问题发现器:通过分析模型在四个轴上的表现短板,明确后续改进方向。数据集和代码都已开源,可直接使用。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★☆
构建大规模数据集和系统性评估基准的工作,其创新性更多体现在工程整合与问题定义的深度上,而非提出全新的算法。但其将自动驾驶VLM评估体系化、精细化到四轴联动的思路,具有很好的引领性。实验合理度:★★★★★
实验设计非常扎实。对比了通用大模型、领域专用模型和自行微调模型,层次清晰。引入了地理泛化和左右舵切换等现实挑战进行评估,说服力强。归一化和加权方案有详细说明,透明且合理。学术研究价值:★★★★★
价值极高。为自动驾驶多模态研究社区提供了一个亟需的、权威的“标尺”和“练兵场”。其四轴评估框架明确了驾驶VLM应具备的核心能力,对未来模型研发有直接的指导意义。开源的数据集和代码将进一步推动领域发展。稳定性:★★★☆☆
基准本身作为评估工具是稳定的。但基于该基准评估出的模型(包括论文中表现最好的ScenePilot模型),其能力离直接产品化落地还有距离,尤其是在运动规划和高风险场景的决策上,仍需与更可靠的规控系统结合,并经过大量仿真和实车测试。适应性以及泛化能力:★★★★☆
数据集本身具有极强的地理多样性,为训练泛化能力强的模型提供了基础。论文中的泛化实验也证实了模型具备一定的跨域能力,但也在规则敏感的任务(如风险判断、元动作预测)上暴露了局限性,这是未来需要重点攻克的方向。硬件需求及成本:★★☆☆☆
训练和评估大规模VLM(尤其是类似Qwen2.5-VL-72B的模型)计算成本非常高昂,需要多张高端GPU(如A800)。即使是微调后的较小模型,在实时推理时也可能面临延迟挑战。这限制了其在边缘设备上的部署。复现难度:★★★★★
完美!论文承诺将数据集和代码完全开源(GitHub和Hugging Face),并提供了详细的标注流程和实验设置。只要具备相应的计算资源,复现其基准测试和训练过程应该没有障碍。产品化成熟度:★★☆☆☆
目前主要处于研究和原型验证阶段。作为评估工具已成熟可用,但基于该基准开发的VLM模块,要集成到真正的自动驾驶产品栈中,还需经过严格的安全认证、冗余设计、极端情况测试等一系列工程化难关。可能的问题:
标注依赖VLM和几何模型(如VGGT),可能存在错误累积和系统性偏差。“GPT分数”作为评估标准之一,其主观性和对GPT-4o本身的依赖有待商榷。评估是开环的,与闭环驾驶性能的关联仍需通过仿真等手段进一步验证。[1] Y. Wang et al., “ScenePilot-Bench: A Large-Scale Dataset and Benchmark for Evaluation of Vision-Language Models in Autonomous Driving,” arXiv preprint arXiv:2601.19582v1, 2026. (本论文)[2] 论文原文链接: https://arxiv.org/pdf/2601.19582v1.pdf[3] 开源代码仓库: https://github.com/yjwangtj/ScenePilot-Bench[4] 开源数据集: https://huggingface.co/datasets/larswangtj/ScenePilot-4K*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

🚗 想和更多自动驾驶、机器人领域的小伙伴一起探讨前沿技术吗?
欢迎加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 自动驾驶+上海+同济+龙哥),根据格式备注,可更快被通过且邀请进群。