*回顾自动驾驶的发展历程,详解三代技术范式的转移升级。
1920s - 1990s:技术起源与实验室探索
1925 年,电气工程师 Francis Houdina 展示了全球首辆无线电遥控无人车“American Wonder”,开启了人类对无人驾驶的想象。
1939 年,通用汽车在世博会展示“Futurama”愿景,首次提出“自动化高速公路系统”的构想。
1977 年,日本筑波机械工程实验室(Tsukuba Mechanical Engineering Lab)开发出了世界上第一辆基于视觉的自动驾驶汽车。这被认为是现代自动驾驶的真正起点。
2000s - 2017:感知觉醒与商业化前夜
2005 年,斯坦福大学 Stanley 车队赢得 DARPA 无人车越野挑战赛冠军。
2009 年,谷歌正式启动无人驾驶项目(Waymo 前身),标志着自动驾驶从学术研究正式跨入科技巨头引领的产业化阶段。
2012 年,深度学习迎来爆发,AlexNet 在 ImageNet 竞赛夺冠,其背后的卷积神经网络(CNN)随后成为自动驾驶视觉感知的核心。
2014 年,特斯拉发布第一代 Autopilot 硬件(HW1.0),拉开了 L2 级辅助驾驶大规模装车的序幕。
2017 年,百度发布“Apollo”开源平台,打破了技术壁垒,极大加速了中国自动驾驶产业的整体研发进度。
2018 年至今:范式转移与 AGI 时代
2018 年,特斯拉率先推出 NOA(Navigate on Autopilot),标志着自动驾驶进入了“高速领航”时代,真正确立了自动驾驶技术的用户价值。
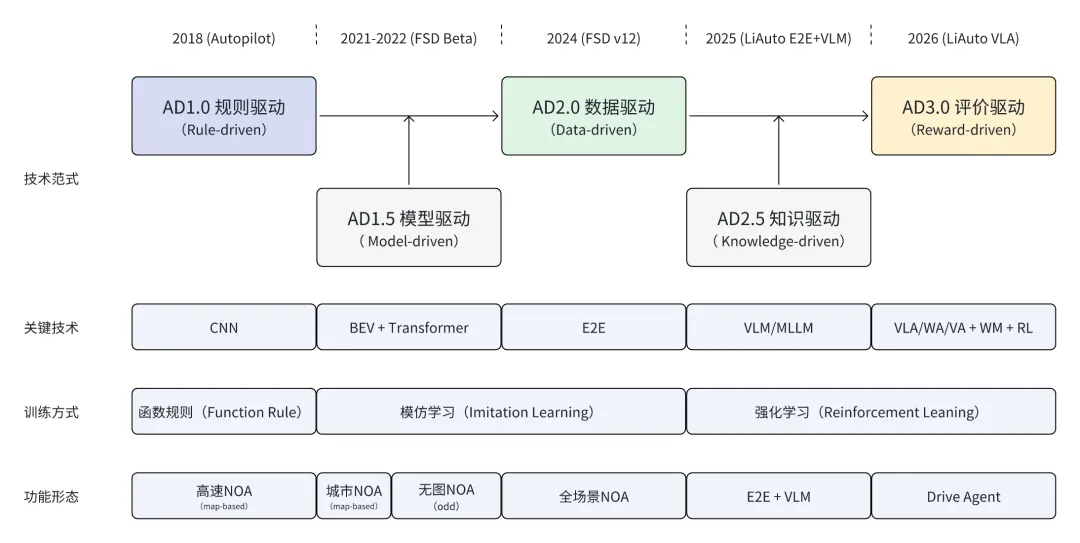
此后,自动驾驶进入稳定发展期,经历了三代技术范式的迭代,和两个中间阶段的跨越式发展,如下图所示。
自动驾驶的进化史,就是 ODD(Operational Design Domain,运行设计域)不断扩张(哪里都能去)和 OOD(Out-of-Distribution,分布外)不断缩小(什么都见过)的过程。
1. AD1.0 规则驱动(Rule-driven)
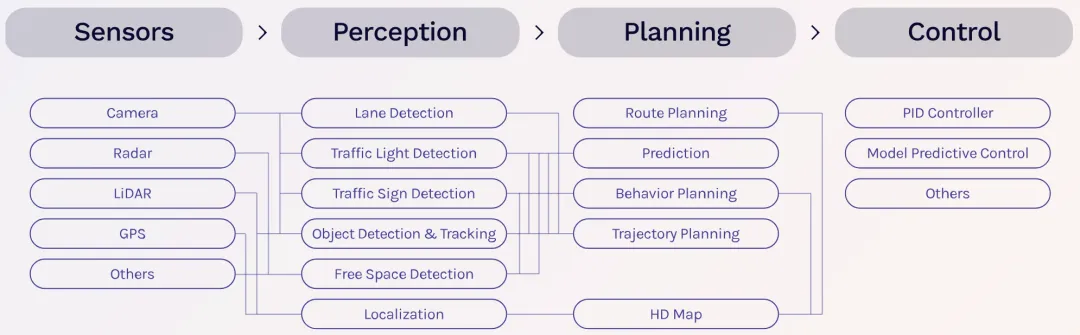
将自动驾驶系统划分为感知、规划、控制等模块,单独进行开发,模块间通过结构化数据传递信息,如下图所示。通过工程师预设的海量“if-then-else”逻辑(即人类驾驶经验规则化),实现驾驶的功能。
AD1.0 阶段实现了自动驾驶从 0 到 1 的可行性验证。此阶段的代表性产品功能是高速NOA。
From: https://wayve.ai/technology/
优点:
高度可解释性(Interpretability),每一行代码都代表一个明确的决策。
强制安全边界(Hard Safety Rules),物理世界的限制都可以被转化为强制代码指令。
调试的高效性,针对特定场景,“哪里不行改哪里”的修复方式在初期非常管用。
缺点:
AD1.0 阶段的最大局限性主要体现在以CNN为基础的感知能力有限,规划模块的局限性还没有被凸显出来。
随着深度学习技术的发展,AD1.5 阶段的标志是BEV(Bird's Eye View)+ Transformer架构的出现,深度学习模型在感知模块获得广泛应用,特斯拉发布的 BEV(2021年)和 OCC(2022年)感知技术让自动驾驶进入了“大感知 + 小规控”的时代,BEV 技术的出现也为后续无图 NOA 真正摆脱高精地图打下了基础。
AD1.5 阶段大幅度的提升了自动驾驶感知方面的能力,此后,驾驶行为的“机械感”和“不拟人”成为了关注的重点,基于规则的范式很快被确认是无法解决此问题的,迫切需要新的架构和范式出现。
2.AD2.0 数据驱动(Data-driven)
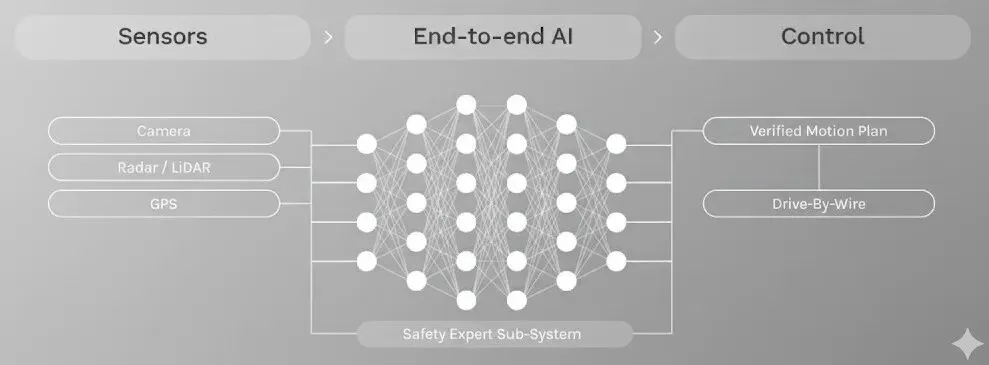
数据驱动阶段的标志就是端到端(End-to-End)自动驾驶技术,在端到端架构下,感知、预测和规划不再是孤立的模块,而是整合进一个巨大的神经网络,数据从一端进入(传感器数据),操作指令从另一端输出(轨迹),代替了繁琐的人工逻辑,通过模仿学习(Imitation Learning),给模型喂数万公里的专家(人类驾驶员)数据,让模型学习在 S 状态下,人类通常会做出什么动作 A,大大改善了 AD1.0 时代的规则穷举难题。
From: https://wayve.ai/technology/
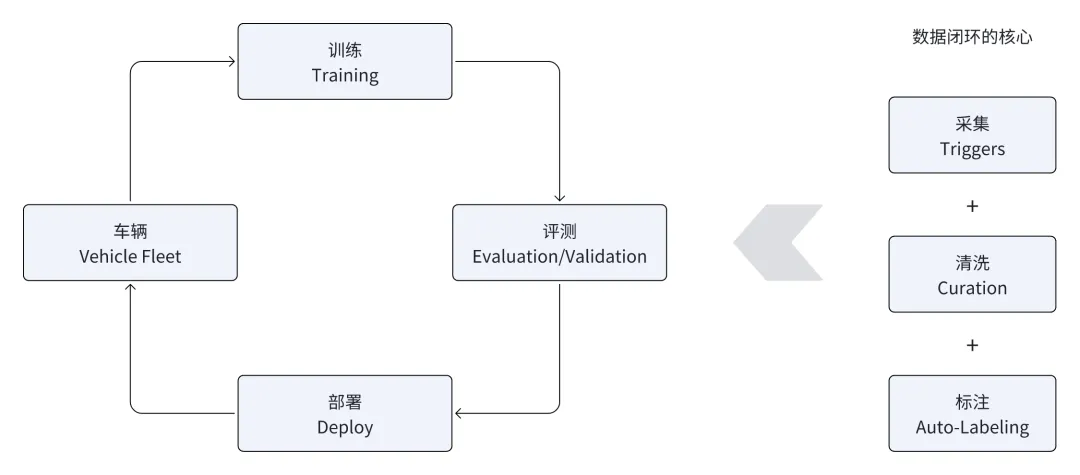
2018年,Andrej Karpathy(前特斯拉 AI 高级总监)在多次技术演讲中首次详细阐述了“Data Engine”(数据引擎) 的概念,这正是现在我们所说的“数据闭环”的原型。
2019年,特斯拉在“Autonomy Day”(自动驾驶日)上向全球展示了这套系统的威力,正式确立了数据闭环在自动驾驶中的统治地位。
数据闭环正是促使从 AD 1.0 走向 AD 2.0 的关键基础设施,还有下文提到的仿真模拟(Simulation)和影子模式(Shadow Mode)也都是端到端时代的关键产物。
优点:
信息零损耗 (Zero Information Loss),AD2.0 直接处理原始特征流,保留了最完整的环境语义。
拟人化的驾驶表现 (Human-like Behavior),从数百万人类老司机数据中学会驾驶能力。
泛化能力更强,模型能处理各种微妙的、难以用文字描述的驾驶技巧。
研发效率大幅提升,模型能力取决于算力的规模和数据的质量。
缺点:
不可解释性 (Black Box),端到端的神经网络不像模块化那样任何问题“有迹可循”。
对数据的高度依赖,如果数据里有司机的坏习惯(如随意加塞),模型也会学坏。
因果误导(Causal Confusion),模型学习的是统计关联关系,缺乏对因果关系的建模和学习。
安全性验证变得困难 (Verification & Validation),验证系统安全只能依靠海量的仿真模拟 (Simulation) 和影子模式 (Shadow Mode)。
AD 2.0 以后,随着“无图”和“端到端”的量产落地,ODD 正在趋向于“全场景”,即理论上只要有路就能开。
AD 2.0 的局限也随之出现,无论你给 AI 喂多少人类驾驶数据,现实世界总有它没见过的奇怪东西(OOD),也就是自动驾驶模型缺少通识知识和常识理解的能力,而VLM(大视觉语言模型)在一定程度上弥补了这个不足,从此自动驾驶进入了知识驱动的时代。
AD 2.5阶段,将视觉语言模型引入自动驾驶场景以辅助决策,此阶段的主流技术架构是理想汽车提出的“E2E+VLM”快慢双系统架构,E2E(即快系统,或者叫系统一)负责开车,VLM(即慢系统,或者叫系统二)负责思考。但是系统一和系统二的协作方式需要规则实现,系统二只有在复杂驾驶场景下才会被使能。
3. AD3.0 评价驱动(Reward-driven)
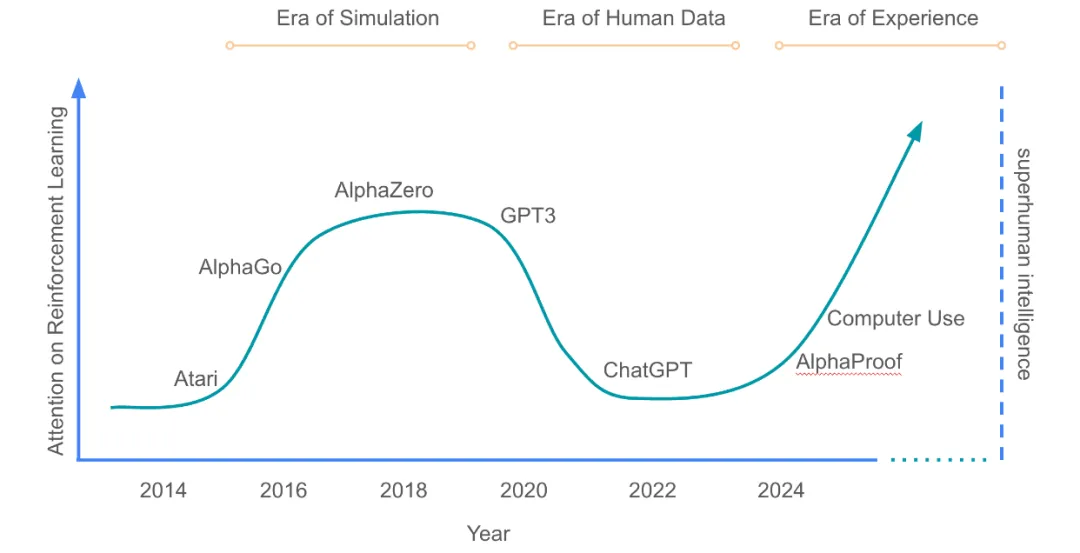
2025年4月,David Silver 和 Richard S. Sutton 撰写了一篇文章 “Welcome to the Era of Experience”:人工智能(AI)正从依赖人类数据的时代,迈入一个以自主经验为核心的新时代,即“体验时代”(Era of Experience),这一转变对于实现超越人类能力的通用人工智能(AGI)至关重要。总结了 AI 发展的三个阶段:
1. 模拟时代,在受控环境中通过强化学习掌握任务。
2. 人类数据时代,依赖大规模人类生成数据进行训练。
3. 体验时代,通过与环境的互动,自主生成数据并持续学习,超越人类知识的限制。
AI 的未来在于通过与环境的互动,自主生成数据并持续学习,从而突破人类数据的限制,才能实现验证的智能,也就是在开放世界下进行长奖励机制下的闭环强化学习。
From: https://theaiinnovator.com/welcome-to-the-era-of-experience
AD3.0 阶段的特点是模型不再单纯模仿人,而是给模型设定一套“价值观”(Reward Function/Model)通过强化学习(Reinforcement Leaning)学会开车,解决了“数据覆盖与模仿上限”难题。数据驱动时代依然依赖海量高质量人类专家驾驶数据,而 Reward-driven 允许模型在没有专家示范的情况下,通过理解物理规律和目标函数来自主进化。
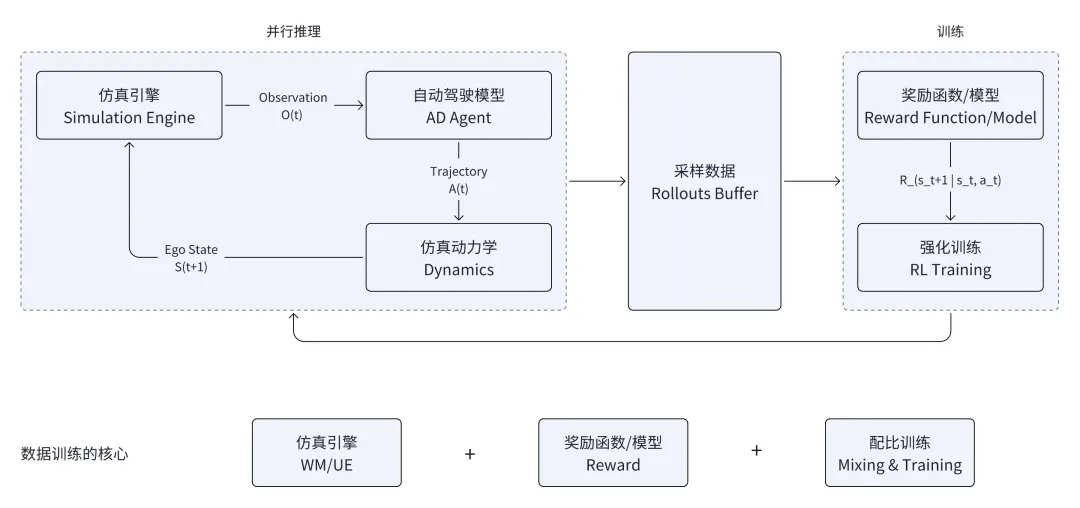
训练闭环正是促使从 AD 2.0 走向 AD 3.0 的关键基础设施,其核心是构造一个高度逼真和高精度的仿真环境(基于世界模型或游戏引擎),通过设定准确的奖励信号,模型通过在仿真环境里不断试错和自由探索来寻找最优解。
训练闭环让模型不仅能学会「能做什么」,还能学会「不能做什么」,训练闭环不需要海量的原始模仿学习的数据,在仿真环境不断试错的过程就类似生产训练样本的过程,正所谓算力即数据,什么是好或不好的行为完全由评价Reward定义,Reward是这个AD 3.0的关键。
优点:
更强的泛化能力,通过在仿真环境中自由探索找到最优驾驶行为,而不只是AD1.0的“背题库”或者AD2.0的“纯模仿”。
长时序的决策优化 (Long-horizon Planning),Reward 让驾驶模型具备“大局观”,提前多看几秒。
从错误中学习并自我进化(Self-Evolving),模仿学习只能学习正样本。
缺点:
奖励函数难定义,奖励函数设计不当会导致“奖励黑客(Reward Hacking)”行为,因为驾驶行为的评价维度(安全、舒适、效率、合规)是互斥的,设计好的驾驶 Reward 变得非常困难。
训练成本高,需要极其强大的仿真环境或世界模型来支撑,特别是推理算力的需求。
模拟与现实的鸿沟 (Sim-to-Real Gap),在虚拟世界里练出的“神技”,在现实中可能因为一个传感器的微小延迟而失效。
简单总结:AD 1.0 的特征是“背题库”(规则),AD 2.0 就是“跟教练学开车”(模仿),AD 3.0 则是通过 Reward(奖励机制) 驱动的“自我进化”。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
