辞旧迎新,知识续航!「龙哥读论文」陪你跨年,知识星球会员优惠券限时限量放送!🐉 「龙哥读论文」知识星球:让你看论文像刷视频一样简单!公众号每日8篇拆解不够看?星球无上限更AI领域论文、资讯、招聘、招博、开源代码,一站式干货,每日2分钟刷完即赚!👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~

龙哥推荐理由:
这篇论文精准地戳中了当前端到端自动驾驶模型的一个“阿喀琉斯之踵”——对视觉外观变化的极度脆弱性。它不仅创造性地构建了一个能“纯视觉攻击”模型的基准,更提出了一个简单、通用且效果拔群的解决方案:用一个冻结的视觉基础模型作为“恒定之眼”。这种思路非常巧妙,把复杂的外观鲁棒性问题,转化为了如何用好一个现成的强大特征提取器的问题,为整个领域提供了一个极具启发性的新范式。
原论文信息如下:
论文标题:
The Constant Eye: Benchmarking and Bridging Appearance Robustness in Autonomous Driving
发表日期:
2026年02月
发表单位:
浙江大学
原文链接:
https://arxiv.org/pdf/2602.12563v1.pdf
开源代码链接:
代码将公开
自动驾驶的“视觉脆弱性”:是路太复杂,还是天在下雨?
想象一下,你训练了一个自动驾驶AI,在风和日丽的旧金山街道上表现堪称老司机。结果有一天,把它放到下雨的北京五环,它直接懵圈了,要么不敢开,要么规划出危险路线。
这时,一个灵魂拷问出现了:这个AI到底是“路痴”(不理解复杂的新路况),还是“近视”(看不清雨雪天气下的路)?
在学术界,这被称为分布外(Out-of-Distribution, OOD) 泛化问题。自动驾驶的驾驶场景可以看作由两部分组成:外观(天气、光照、色调)和几何结构(道路拓扑、建筑物形状、障碍物位置)。
以前的研究有个大问题:把这俩混在一起了。 比如,拿一个“下雨的北京”数据集去测试一个只在“晴朗的旧金山”训练过的模型。模型一败涂地,但你根本分不清它失败的原因是“下雨”(外观变化)还是“北京的道路布局更复杂”(几何变化)。
这就好比一个学生,平时在安静的图书馆考试次次满分,结果一到嘈杂的操场考试就考砸了。你无法判断他是知识点没掌握(几何问题),还是单纯受不了噪音(外观干扰)。
这个问题不解决,自动驾驶的安全性就是个“玄学”。为此,浙大的研究团队提出了两个关键贡献:一个能精准测量“视觉脆弱性”的标尺,和一个简单有效的“解药”。
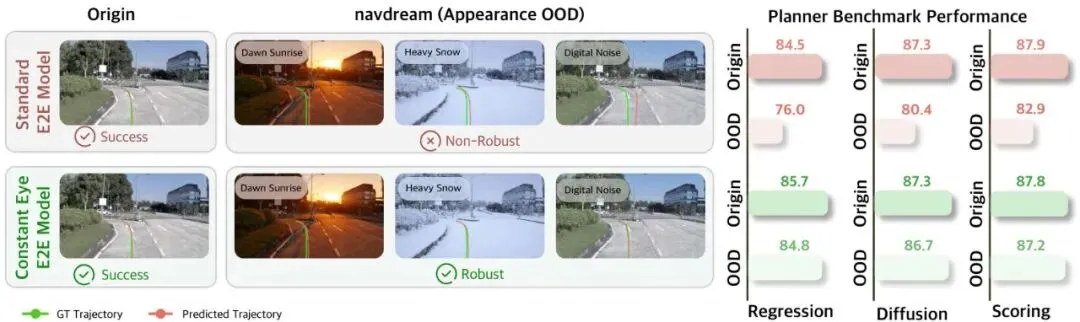
图1:本文概览。本文提出了NAVDREAM基准,它包含导致多种规划算法性能显著下降的分布外观变化。本方法通过一个“恒定之眼”(冻结的视觉基础模型)来看待图像,以弥合外观鲁棒性的差距。
打造“恒定之眼”:用冻结基础模型剥离外观干扰
如何让自动驾驶系统不再被“表象”迷惑,始终能抓住道路和障碍物的“本质”?
这篇论文的思路非常巧妙:给它一双“恒定之眼”(The Constant Eye)。
这双“眼睛”就是一个冻结的(训练中参数不更新)视觉基础模型 DINOv3。DINOv3是一个通过自监督学习在海量图像上训练出来的视觉模型,它有一个神奇的特性:擅长提取物体的“语义”和“结构”特征,而对颜色、纹理、光照等“外观”信息相对不敏感。 换句话说,无论你给它看一张晴天、雨天还是复古滤镜的道路图片,它“看”到的核心几何结构和物体语义信息都差不多。
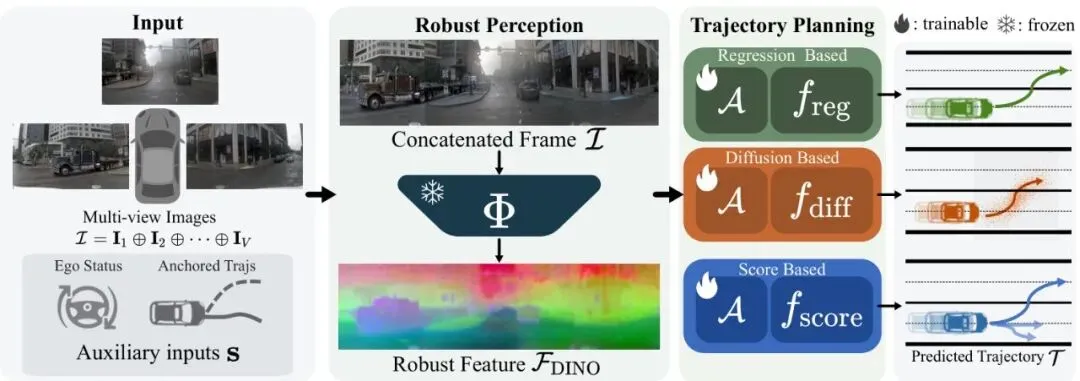
1. “恒定视觉编码”:原始相机图像输入冻结的DINOv3模型,得到一组特征图。这些特征图携带了外观不变的场景结构和语义信息。
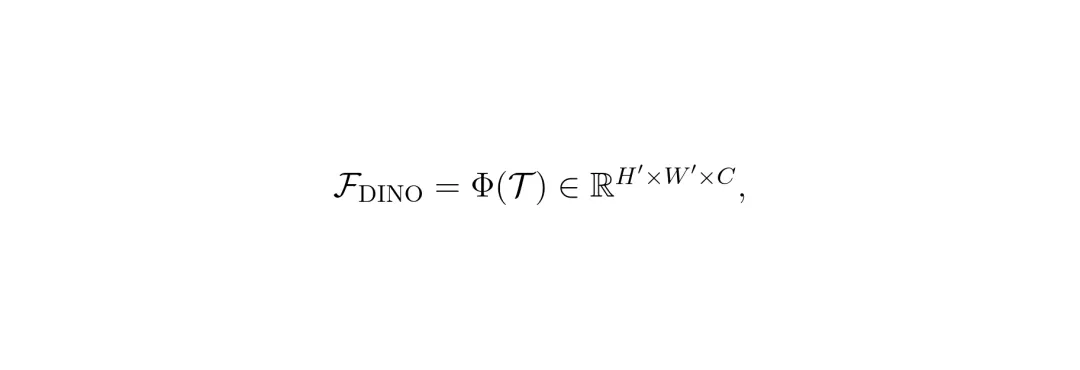 2. “轻量适配器”:DINOv3提取的特征维度很高,且不完全符合自动驾驶规划任务的“口味”。因此,需要一个轻量的适配器网络,对特征进行降维和空间聚合,把它变成下游规划器“爱吃”的格式。
2. “轻量适配器”:DINOv3提取的特征维度很高,且不完全符合自动驾驶规划任务的“口味”。因此,需要一个轻量的适配器网络,对特征进行降维和空间聚合,把它变成下游规划器“爱吃”的格式。
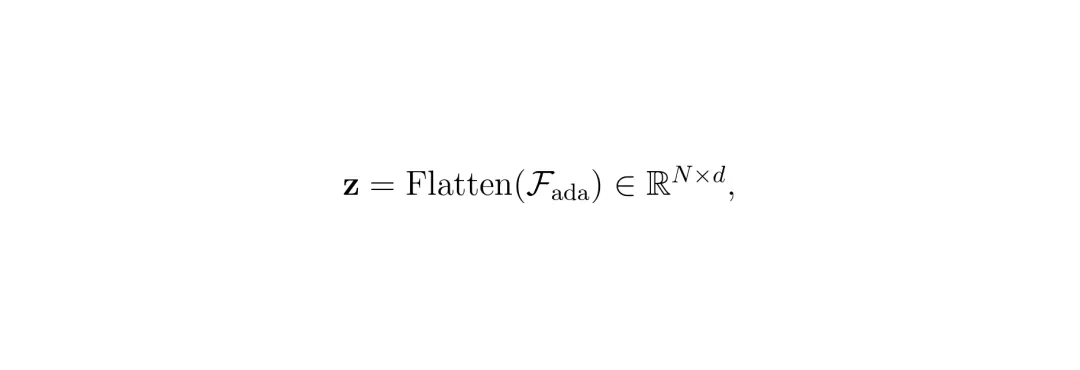 3. “通用接口输出”:经过适配的特征,作为一个稳定的、外观鲁棒的场景表示,输送给后面的规划模块。
图3:方法。使用冻结的DINOv3主干网络Φ从原始相机输入中提取特征,这些特征在不同视觉领域中保持一致的语义信息。这些结构表示随后由轻量级特征适配器A处理以降维。这个即插即用的解决方案可以集成到回归、扩散和基于评分的规划范式中,以确保在不同外观条件下的鲁棒轨迹生成。
最关键的是,这个“恒定之眼”接口是冻结的。这意味着在训练下游规划器时,视觉部分的参数纹丝不动。这样做强制规划器必须学会基于那些稳定的、本质的几何和语义特征来做决策,而不能“偷懒”去依赖那些容易变化的像素级外观线索(比如积水反光的特定模式)。相当于给规划器戴上了一副“透过现象看本质”的眼镜。
3. “通用接口输出”:经过适配的特征,作为一个稳定的、外观鲁棒的场景表示,输送给后面的规划模块。
图3:方法。使用冻结的DINOv3主干网络Φ从原始相机输入中提取特征,这些特征在不同视觉领域中保持一致的语义信息。这些结构表示随后由轻量级特征适配器A处理以降维。这个即插即用的解决方案可以集成到回归、扩散和基于评分的规划范式中,以确保在不同外观条件下的鲁棒轨迹生成。
最关键的是,这个“恒定之眼”接口是冻结的。这意味着在训练下游规划器时,视觉部分的参数纹丝不动。这样做强制规划器必须学会基于那些稳定的、本质的几何和语义特征来做决策,而不能“偷懒”去依赖那些容易变化的像素级外观线索(比如积水反光的特定模式)。相当于给规划器戴上了一副“透过现象看本质”的眼镜。
NAVDREAM基准:一场纯粹针对视觉的“压力测试”
光有“解药”还不够,你得先有把精准的“尺子”来诊断病情。这就是本文的第一个重磅贡献——NAVDREAM基准。
它的核心目标,就是把“外观变化”和“几何结构变化”彻底分开,单独给自动驾驶模型的视觉系统做个“压力测试”。
团队基于真实的NAVSIM驾驶数据集,利用强大的生成模型Flux,对每一帧道路图像进行“像素级对齐的风格迁移”。
用人话讲就是:路还是那条路,车还是那些车,但给它们加上暴雨、大雪、晨雾、夕照、复古滤镜、动态模糊等十种完全不同的“皮肤”或特效。
图2:NAVDREAM中基于外观的OOD变化的视觉分类。展示了原始帧以及由Flux模型生成的10种合成风格变体。所有变换都保留了底层的3D几何和语义结构,同时将视觉域转移到各种OOD条件。
这样,对于同一个驾驶场景,你就有了11个版本(1个原始+10个变体)。它们的地图、真值轨迹、所有物体的位置完全一样,变的只有像素颜色和纹理。
用数学公式来形式化这个思想,就是把一个驾驶场景S的概率分布,分解为给定几何G条件下的外观分布A,和几何本身的分布G:
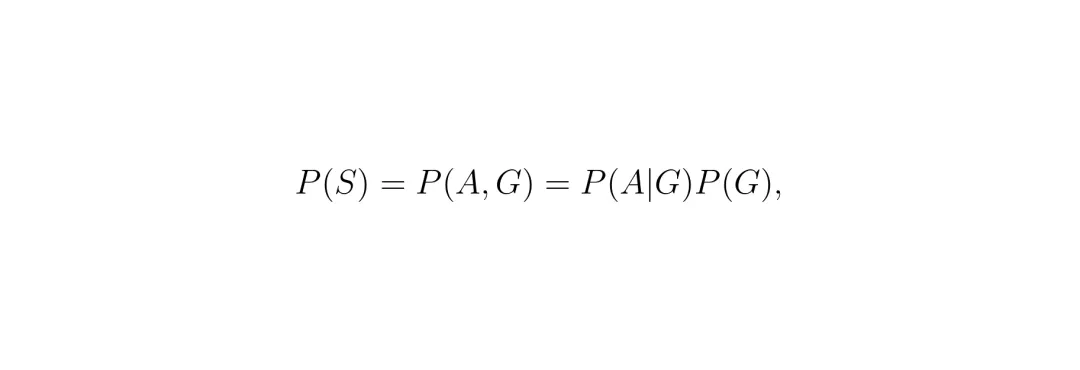 NAVDREAM做的就是固定G(几何不变),然后疯狂改变P(A|G)(生成各种外观)。
这样一来,任何模型在这个基准上表现下滑,原因有且仅有一个:它的视觉感知模块扛不住纯粹的外观变化。这是一把剔骨见髓的锋利手术刀。
评估指标采用了综合性的EPDMS(扩展预测性驾驶员模型分数),它由多个子指标组合而成,涵盖了无过错碰撞、可行驶区域合规、交通灯合规、车道保持、舒适度等多个维度。
NAVDREAM做的就是固定G(几何不变),然后疯狂改变P(A|G)(生成各种外观)。
这样一来,任何模型在这个基准上表现下滑,原因有且仅有一个:它的视觉感知模块扛不住纯粹的外观变化。这是一把剔骨见髓的锋利手术刀。
评估指标采用了综合性的EPDMS(扩展预测性驾驶员模型分数),它由多个子指标组合而成,涵盖了无过错碰撞、可行驶区域合规、交通灯合规、车道保持、舒适度等多个维度。
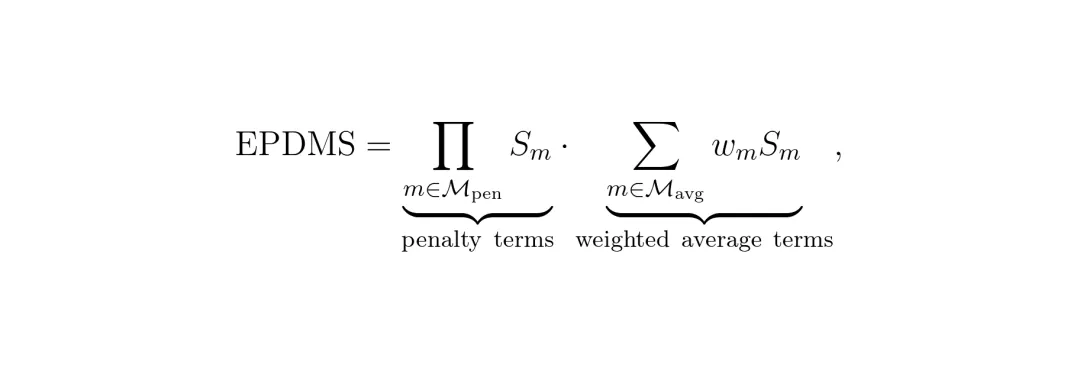
即插即用,全面兼容:三大规划范式性能飞跃
“恒定之眼”接口的通用性有多强?论文把它接入了当前主流的三大端到端规划范式进行验证:
· 回归式 (Regression-based):以LTF为代表,直接预测未来轨迹点。给它换上“恒定之眼”后,称为LTF-DINO。
· 扩散式 (Diffusion-based):以DiffusionDrive为代表,从噪声中逐步去噪生成轨迹分布。对应变体为DiffusionDrive-DINO。
· 评分式 (Scoring-based):以GTRS-Dense为代表,从一组候选轨迹中挑选评分最高的。对应变体为GTRS-Dense-DINO。
Base:原版模型,用其原始视觉主干(如VoVNet)在正常数据上训练。
DR (Domain Randomization, 域随机化):一种传统增强鲁棒性的方法,让Base模型在训练时也见过NAVDREAM中的一部分(5种)“见过”的风格。
DINO (Ours):我们的方法,使用冻结DINOv3,只用在正常数据上训练,从未见过NAVDREAM中的任何合成风格。
最终的测试在NAVDREAM中完全没见过的另外5种风格上进行,零样本评估其泛化能力。
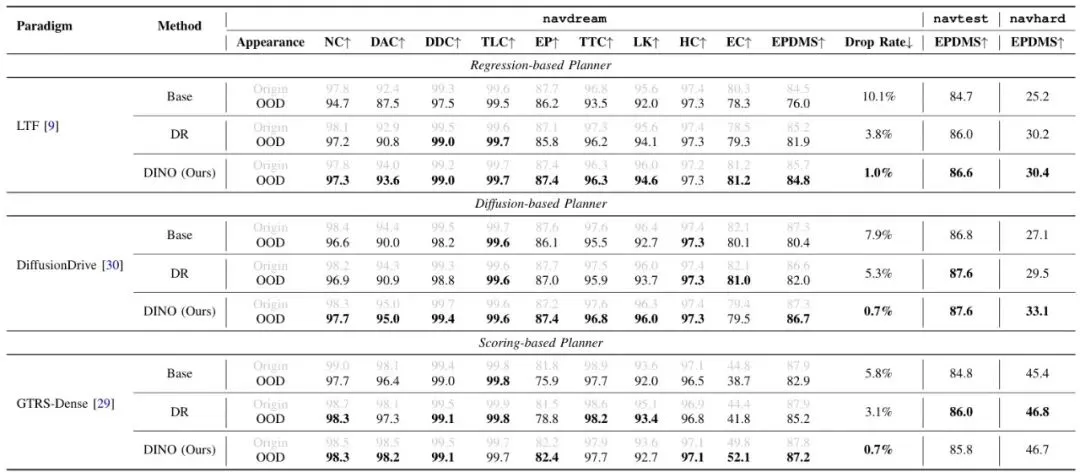
表I:在NAVDREAM,navtest和navhard上的定量结果。展示了三种规划范式的比较。Method列表示每个范式的三种模型变体方法。
1. 在NAVDREAM基准上(OOD列):Base模型遭遇滑铁卢,性能暴跌(EPDMS下降高达10.1%)。DR方法有所缓解,但仍有明显下降(3.1%-5.3%)。而DINO方法展现出了惊人的稳定性,性能下降幅度微乎其微(仅0.7%-1.0%),几乎不受外观剧变的影响。
2. 在原始真实基准上(navtest/navhard):DINO方法不仅没有因为追求外观鲁棒性而牺牲正常情况下的性能,反而普遍优于或持平原版Base模型。这说明DINOv3提供的特征质量本身就更优。
定性结果更是直观: 在暴风雪中,原版LTF规划出的轨迹直接冲出道路撞上了路缘石,而LTF-DINO则稳稳地行驶在车道内。
 一个冻结的基础模型,零样本横扫十种恶劣天气和特效,同时还能提升常规表现,这个“即插即用”的方案性价比太高了。
一个冻结的基础模型,零样本横扫十种恶劣天气和特效,同时还能提升常规表现,这个“即插即用”的方案性价比太高了。
特征可视化揭秘:DINOv3为何能“看透”风雨?
效果这么好,背后的原理是什么?论文通过一系列精妙的特征可视化给出了答案。
将同一场景在不同外观下的图像,分别输入DINOv3和传统主干网络VoVNet,提取特征并做PCA降维可视化。
图5:特征可视化。对于每种外观,展示输入图像、VoVNet的PCA特征图和DINOv3的PCA特征图。DINOv3在风格变化中提取出外观不变的语义结构,而VoVNet主干则表现出很大的变化。
结果一目了然:VoVNet的特征图随着外观变化而剧烈波动,支离破碎。而DINOv3的特征图宛如复制粘贴,清晰稳定地勾勒出了道路边界、车辆等核心结构。这说明DINOv3确实学会了剥离外观“画皮”,直击几何“骨骼”。
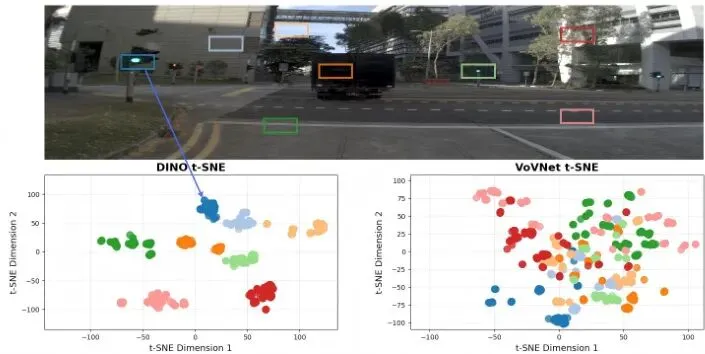
更进一步,论文用t-SNE技术将特征向量投影到二维空间。每个点代表图像中的一个空间位置的特征,颜色代表其原始坐标。
图6:空间标记一致性的t-SNE可视化。比较了DINOv3和VoVNet对于同一场景在所有视觉领域中的特征标记。点按其原始空间坐标着色。
理想情况是:相同位置的点(无论外观如何)应该聚集在一起。结果显示,VoVNet的特征点在不同外观下散落各处,杂乱无章。而DINOv3的特征点则形成了清晰的、按空间坐标聚集的色块,证明其空间表示具有极强的外观不变性。
这些可视化证据有力地解释了“恒定之眼”为何有效:它提供了一种高维、稳定、语义丰富的场景表示,让下游规划器无需再与变幻莫测的像素外观作斗争,可以直接基于不变的本质特征进行推理。
未来展望:从开环评估走向闭环交互与多模态融合
当然,这项工作也留下了未来可探索的空间。论文主要进行的是开环评估,即给定历史帧,预测未来轨迹,不与环境进行实时交互。未来的工作可以延伸到闭环仿真中,测试在动态交互的交通流里,“恒定之眼”是否依然能保持鲁棒。
此外,当前方法聚焦于纯视觉输入。在真实自动驾驶系统中,激光雷达(LiDAR)等多模态传感器可以提供不受天气影响的精确3D几何信息。如何将“恒定之眼”的外观不变视觉特征,与激光雷达的精确点云进行深度融合,构建更强大、更全面的环境感知系统,是一个极具前景的方向。
无论如何,这篇论文为提升自动驾驶的视觉鲁棒性提供了一个清晰、有效且通用的范式。它告诉我们,有时候解决一个复杂问题,未必需要设计更复杂的模型,巧妙地“借用”一个现成的、强大的基础能力,可能是一条更优雅的捷径。
龙迷三问
这篇论文解决的核心问题是什么?它解决了端到端自动驾驶模型对视觉外观变化(如天气、光照)极度脆弱的问题。传统评估方法无法区分模型失败是因为“路变复杂了”还是“天变难看了”,本文通过创建NAVDREAM基准来精准量化这一“视觉脆弱性”,并提出了用冻结的视觉基础模型DINOv3作为“恒定之眼”来根本性提升外观鲁棒性。
文中的OOD和DINOv3具体指什么?OOD是Out-of-Distribution的缩写,中文常译作“分布外”或“域外”,指模型在训练时未见过的数据分布。在本文特指自动驾驶模型未曾见过的视觉外观(如暴雪、复古滤镜)。DINOv3是Meta(原Facebook)AI发布的一种先进的视觉基础模型,通过自监督学习在海量图像上训练,擅长提取对外观变化不敏感的语义和结构特征。
为什么冻结DINOv3比微调它更好?这是本文设计的关键。“冻结”意味着在训练规划器时,DINOv3的参数保持不变。这样做是为了强制下游规划器去学习和依赖DINOv3提供的外观不变的稳定特征。如果进行微调,规划器可能会“教坏”DINOv3,让它又去关注那些容易变化的像素纹理,从而失去其固有的鲁棒性。冻结相当于设定了一个不可动摇的“感知标准”。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★☆
创造性地构建了能精准分离外观与几何影响的NAVDREAM基准,并提出了“冻结基础模型作恒定接口”这一简洁有力的范式,思路新颖且极具启发性。实验合理度:★★★★★
实验设计严谨,对比基线设置合理(Base, DR, DINO),在NAVDREAM(零样本)、navtest、navhard三个基准上进行了全面验证,结果具有高度说服力。学术研究价值:★★★★★
不仅提出了一个新基准和有效方法,更重要的是为提升模型鲁棒性提供了一个新的思路范式——即利用并“冻结”大模型已有的强大泛化能力作为稳定模块。这对自动驾驶乃至其他依赖视觉的AI系统都有很高的参考价值。稳定性:★★★★☆
在论文设定的开环规划任务中,面对十种剧烈的外观变化,方法表现出了卓越的稳定性。但尚未在更复杂的闭环交互动态环境中验证。适应性以及泛化能力:★★★★★
核心优势就在于其强大的零样本泛化能力。无需针对新天气重新训练,即插即用,适应性强。且兼容三大主流规划范式,展现了极好的通用性。硬件需求及成本:★★★☆☆
DINOv3模型本身较大,推理时需要一定的计算资源,可能比一些小型的任务专用主干网络更耗时耗力。这是换取鲁棒性需要付出的代价。复现难度:★★★★☆
方法框架清晰,代码将开源,但NAVDREAM基准的构建涉及大量生成式模型的运用和计算(约960 GPU小时),完全复现基准数据有一定门槛。复现方法本身相对容易。产品化成熟度:★★★☆☆
在开环轨迹预测任务上已展现出极高潜力,但距离直接用于控制车辆的实时闭环系统还有距离。需要进一步在动态仿真和真实路测中验证其交互安全性,并与多传感器(如激光雷达)方案集成。可能的问题:
主要局限在于目前仍是开环评估,且仅测试了视觉外观变化。真实的OOD挑战还包括几何结构变化、极端交互行为等。将“恒定之眼”的思路推广到更广泛的OOD场景以及闭环系统,是未来的关键考验。[1] The Constant Eye: Benchmarking and Bridging Appearance Robustness in Autonomous Driving. https://arxiv.org/pdf/2602.12563v1.pdf*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

🤖 欢迎加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 自动驾驶+杭州+浙大+龙哥),根据格式备注,可更快被通过且邀请进群。