观点争鸣 | 自动驾驶伦理应当远离电车难题
- 2026-07-04 15:29:22
编者按
此前,我们推荐了 Luke Munn 发表在 AI and Ethics 上的文章——《AI伦理的无用性》(The Uselessness of AI Ethics),以及 Björn Lundgren 发表在同一期刊上的针锋相对之作——《为伦理指南辩护》(In defense of ethical guidelines)。两位针对人工智能伦理的有效性与治理转向提出了各自的观点,呈现出精彩的学术争鸣。
本期,我们关注另一个更为具体且极具争议的话题——自动驾驶伦理中的电车难题。
Suzanne Tolmeijer 等人认为,大众媒体与部分学界对电车难题式极端思想实验的过度沉迷,已致使公众建立起一套严重偏离技术现实的错误预期。他们指出,现实中的交通风险是连续、动态且充满不确定性的,脱离工程实际的伦理聚焦不仅无法指导算法设计,反而掩盖了自动驾驶在绝大多数时间里真正面临的挑战。因此,任何关于自动驾驶的讨论都应基于当前的技术现状和真实场景,远离和超越电车难题类的思想实验,并关注更为隐微但常态化的微观风险控制与真实感知问题。
当然,真理越辩越明。将这一经典思想实验视为误导性的智力陷阱是否过于激进?哲学思辨在技术现实面前真的彻底失效了吗?这一期,我们首先展示支持方(实证批判派)的视角,而在后续推文中,我们将引入反对方(哲学辩护派)的立场,呈现相反的辩护观点。
请大家先看 Suzanne Tolmeijer 等人的文章。
AI and Ethics (2024) 4:473–484
Trolleys, crashes, and perception—a survey on how current autonomous vehicles debates invoke problematic expectations(电车、碰撞与认知——关于当前的自动驾驶车辆辩论如何引发有问题的预期的调查研究)
Suzanne Tolmeijer¹, Vicky Arpatzoglou², Luca Rossetto², Abraham Bernstein²(1.University of Hamburg, Information Systems, Socio-Technical Systems Design, WISTS 2.University of Zurich, Department of Informatics)
https://doi.org/10.1007/s43681-023-00284-7
关于自动驾驶车辆伦理准则的持续辩论主要集中在电车难题的各种变体上。通过在偏好调查中使用这一伦理困境的变体,研究者们讨论了其对自动驾驶车辆政策可能产生的影响。在本研究中,我们认为此类场景缺乏现实性,导致其实践洞察力有限。我们开展了一项针对自动驾驶车辆的伦理偏好调查,其中包含更具现实性的特征,例如时间压力和非二元决策选项。我们的研究结果表明,这些改变导致了不同的结果,这对当前研究结论的普适性提出了质疑。此外,我们调查了自动驾驶车辆能力的框架效应,并指出当前的辩论需要对自动驾驶车辆面临的挑战设定现实的预期。基于我们的结果,我们呼吁该领域将当前的辩论重新框架化,转向超越电车难题的更现实的讨论,并聚焦于哪些自动驾驶车辆的行为被认为是不可接受的,因为关于什么是正确的解决方案可能无法达成共识。
自动驾驶车辆;主观伦理;伦理困境;伦理调查
第一部分 引言
除了此类场景在技术现实性层面的缺失外,将伦理困境的调查结果作为自动驾驶车辆法规的起点还存在其他问题。首先是关于非专业人士偏好的应用价值问题。一方面,为了契合科技创新治理中的参与式转向(participatory turn)[10],非专业人士应当参与塑造自动驾驶车辆的准则,以增加其被社会接受的可能性,因为社会规范会影响对自动驾驶车辆的接受度[11]。另一方面,与自动驾驶车辆的互动体验会正向影响人们对它们的感知[12],这意味着人们目前的态度可能并不反映其未来的偏好,因此不应将其视为制定自动驾驶车辆政策的基准事实(ground truth,原意指机器学习中的真实标签数据,在此引申为制定政策时不可动摇的事实基础)。与此同时,媒体在很大程度上关注自动驾驶车辆的负面方面,如车辆碰撞事故和自动驾驶仪的意外使用,这导致了对自动驾驶车辆更为消极的态度[13]。正如[14]所论证的,非专业人士的自动驾驶车辆偏好应仅在结合专家见解、经过偏差筛选并进行整体一致性调查后,方可用于得出任何政策含义的结论。虽然这些调查可以提供一些关于当前公众情绪的见解,但在其之外的直接应用应受到质疑。
此外,这些高度简化的场景并不能很好地转化为实践。在现实实践中,决策是在一个时间框架内(而非单一静态时间点)结合更多变量进行的,且处于不同程度的不确定性和模糊性之中,面临时间压力,并拥有不止二元的决策选项。特别是使用歧视性变量,如交通参与者的性别和社会地位[8]以及生命价值层级(life value hierarchy,指在伦理决策中对不同生命赋予不同权重的排序,如人>动物),这不仅被法律禁止,而且考虑到当前自动驾驶车辆的技术能力,这也是不现实的[15]。
为了强调人们的反应会如何根据伦理困境的设计或自动驾驶车辆能力的框架而迅速改变,我们(i)扩展了“道德机器”实验,纳入了第三种决策选项、时间压力以及更现实的场景视觉视角,并且(ii)向参与者展示关于自动驾驶车辆性能的不同细节和框架,以观察这如何影响他们的感知。
基于我们的发现,我们认为研究中对这种简化道德困境的关注,以及媒体对自动驾驶车辆碰撞事故不成比例的框架,导致了非技术背景的研究人员和普通公众对自动驾驶车辆在道路上遇到的情况及其能够/应该做什么产生了不准确的预期,因为他们误用了思想实验并试图将其转化为通用政策。我们敦促人工智能伦理学家和工程师加强合作,探讨如何将这些高层级的伦理洞见应用于自动驾驶车辆的实际代码编写中,并纳入特定的框架内;同时,我们也主张在直接应用非专业人士当前的自动驾驶车辆偏好时应持谨慎态度。
在本文的其余部分,我们概述了关于自动驾驶车辆和伦理的相关工作(第2部分)。我们提出了研究问题和假设(第3部分),描述了实验方法(第4部分)和结果(第5部分)。我们讨论了研究发现的意义(第6部分),并总结了我们的工作(第7部分)。
第二部分 相关工作
1.自动驾驶车辆与伦理
国际自动机工程师学会(Society of Automotive Engineers,SAE)定义了六个驾驶自动化等级,范围从“无驾驶自动化”(0级)到“完全驾驶自动化”(5级)[20]。截至撰写本文时,市场上可购买的最高级别为“有条件驾驶自动化”(3级)。例如,本田提供的交通拥堵领航系统赋予汽车控制刹车、转向和油门的能力[21]。开发更高自主性的自动驾驶车辆面临诸多挑战,包括计算资源等技术障碍、消费者信任和政策制定等非技术问题,以及自动驾驶车辆伦理等社会问题[22]。为了迎接自动驾驶车辆成为日常交通一部分并按时塑造预期和政策的未来,关于自动驾驶车辆伦理方面的讨论已经相当充分(例如[23–26])。
大多数关于自动驾驶车辆伦理的讨论都依赖于“电车难题”(Trolley Problem)[27]的变体——这是一系列思想实验,在此类实验中,人类必须决定是通过不作为允许一辆失控的电车在轨道上撞死五个人,还是通过主动将电车转向另一条轨道来挽救这些人,但作为代价杀死另一个人。在自动驾驶车辆的背景下,这被置于不同的情境框架中,例如决定自动驾驶车辆是否应该避免撞击路上的年轻女孩,而是转向冲向人行道上的老妇人[4]。对此类伦理考量的相关性的主要论点是,自动驾驶车辆将能够更快地处理信息,因此必须在人类驾驶员只能依靠瞬间本能行动的情况下,做出理性的预定决策[4]。然而,与有限的计算资源、高效的目标检测以及不稳定的环境相关的技术挑战[22]表明,自动驾驶车辆可能无法及时识别交通参与者的特征以进行预定决策——至少并非在所有可能的情况下都能做到。尽管如此,甚至有更激进的讨论不仅假设自动驾驶车辆将拥有伦理决策设置(接受了我们可以预设自动驾驶车辆伦理困境准则的前提),而且还争论汽车应该处于何种设置中[5]。
为了提高公众对自动驾驶车辆伦理的认识并通过参与增加公众接受度[8],通过伦理偏好调查寻找适合自动驾驶车辆的伦理设置已成为一种方法。
2.自动驾驶车辆伦理偏好调查
相关研究的结果部分强调了此类伦理困境调查的相关性,该研究表明,自动驾驶车辆的潜在消费者采用者认为伦理困境是需要解决的最重要和最突出的问题[29]。人们接受并偏好其他人购买功利主义的自动驾驶车辆,但在个人使用方面,他们更愿意使用那些能挽救自己生命的车辆[30]。这种对自动驾驶车辆预期行为的区别甚至可能导致对此类车辆整体接受度的下降[31]。
3.思考,快与慢
通常,人们倾向于根据意图来评判人类,而根据结果来评判机器[36]。此外,当场景涉及身体伤害时,人们往往认为机器的行为更加不道德和有害[36]。这在自动驾驶车辆碰撞场景中尤为相关。法官将更多的责任归咎于自动驾驶车辆,并比对待人类驾驶员造成的伤害更严肃地对待自动驾驶车辆造成的伤害[37]。当参与者被要求评判自动驾驶车辆与人类驾驶员的碰撞决策时,他们更偏好自动驾驶车辆比人类驾驶员更能最小化伤害[38]。
这就让人质疑,人类在事先的伦理调查中的偏好是否真的反映了他们在碰撞后对实际自动驾驶车辆决策的接受度。部分原因在于,人类驾驶员必须基于“系统1”行动,而自动驾驶车辆则不然。为了验证人们的伦理偏好是否真的在时间压力下有所不同,需要验证“思考,快与慢”对碰撞决策的影响。
4.当前自动驾驶车辆伦理辩论的问题
在早期的工作中,“道德机器”实验的一些作者承认,电车难题与现实相比是简化的场景,现实生活提供了应该被解决的统计问题[6]。人工智能和伦理学领域的专家都同意,虽然“道德机器”实验可以作为讨论自动驾驶车辆伦理的起点,但它存在许多问题,包括未研究参与者自身的决策偏好,以及电车困境有助于提出问题,但无助于找到有关待实施的自动驾驶车辆政策的答案[39,40]。[41]进一步认为,目前讨论形式下的自动驾驶车辆伦理并不相关,原因之一是假设了现实生活中不太可能存在的确定性和知识。他认为,与其关注“什么被认为是正确的”(一个我们无法找到普遍答案的问题),焦点应该放在“什么不被认为是错误的”。同样,[42]认为,由“道德机器”实验等倡议收集的数据不适合作为人工智能体的基准,因为此类基准错误地将平均参与者偏好等同于道德正确性。
此外,场景的框架极大地影响了人们的反应。[38]发现,从行人视角与驾驶员视角构建场景会改变人们关于最佳自动驾驶车辆行动的答案。人们通常是风险规避的,并且赋予风险的权重高于收益[29]。新闻中对车祸的过度关注有助于强调自动驾驶车辆可能的风险,并影响对自动驾驶车辆的感知[13,43]。人们期望自动驾驶车辆能极大地减少车祸数量,但在自动驾驶车辆完全部署之前,这种技术进步不可能完全没有致命事故,这一点根据某些观点是不应被低估的[44]。迄今为止发生的许多此类事故都是由于对驾驶员自主性水平的误解造成的[45]。这导致驾驶员更知情并清晰理解自动驾驶车辆系统能力变得高度重要。此外,媒体夸大了少数自动驾驶车辆碰撞事故,超过了所有其他碰撞事故,也远超自动驾驶车辆性能的积极进展[46]。[47]认为,关注碰撞情况下的行为也可能对自动驾驶车辆的整体安全性有害,因为它可能会分散对日常交通情况中正确行为的关注。日常驾驶体现了诸如流动性、效率和考量行人责任等价值之间的权衡,所有这些都应得到适当考虑。
当前的科学辩论和媒体报道导致潜在用户错误地假设(简化的)伦理困境是自动驾驶车辆需要解决的最突出问题[29]。进一步的困惑可能源于对自动驾驶车辆行为如何产生的误解。[48]将自动驾驶车辆的训练描述为类比于操作性条件作用(operant conditioning,注:原文为“operand”,此处依据心理学术语修正),而不是经典算法意义上的一组指令,并认为因此尚不清楚应在多大程度上试图在罕见的“类电车难题”场景中强制执行特定行为,因为这甚至可能导致其他潜在的负面后果。如果潜在用户拥有关于自动驾驶车辆功能、操作和行为的偏见信息,他们最终会对系统的能力和挑战持有不正确的心理模型[49],这反过来会影响人们使用自动驾驶车辆的意愿。
第三部分 研究问题
1.困境视角
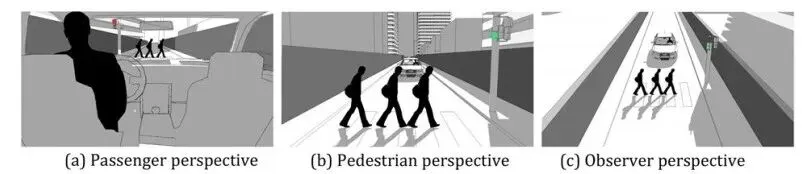
2.时间压力
3.非二元决策选项
4.更现实的描绘
RQ3.与其他伦理偏好调查(如[8,9,28])相比,稍微更现实的困境呈现是否会导致不同的结果?我们预期(H4)当有选项时,会有相当数量的人放弃决策,但(H5)仍然偏好挽救守法的交通参与者和挽救更多生命。
5.能力框架
第四部分 研究方法
为了设定现实的时间压力,使参与者仍能处理问题的所有细节,我们预先测试了参与者在各种场景下所需的时间。在此预测试(N=15)中,所有受访者在所有视角下的平均作答时间为15.5秒。因此,我们将受限时间组的反应时间强制设定为最多15秒,以制造轻微的时间压力,同时也确保大多数人能在这个时间内完成作答。
数据是通过Qualtrics平台进行的调查收集的。在调查的第一部分,询问了参与者的人口统计学问题,以及他们对技术的亲和力,使用的是经过验证的“技术交互亲和力”(Affinity for Technology Interaction,ATI)量表[51]。在下一部分,受访者需根据分配给他们的视角和时间压力,给出他们对八个伦理困境的偏好。
为了研究RQ1,参与者被分配到三种不同的困境视角之一,即:乘客、行人或观察者。不同的视角如图1所示。与[38]相比,我们采用了一种沉浸感较低但更为写实的风格,以验证困境视角是否确实在决策偏好中造成差异。对于每个视角,图像根据a)人数(一人对多人;描绘为一人对三人)和b)交通信号灯的颜色(红灯对绿灯)而有所不同。场景以随机顺序呈现。
在调查的第三部分,参与者被要求在5点李克特量表上指出他们在六种不同场景中使用所描述的自动驾驶车辆的可能性。每个问题的信息框架被设计为:信息首先关注中性成分(即两个关于技术能力的场景),然后是负面成分(即两个关于碰撞信息的场景),最后是正面成分(即两个关于自动驾驶车辆益处及与人类驾驶员相比的碰撞统计数据的场景)。这六个场景的顺序是固定的,以便能够调查H6和H7中提到的顺序效应。最后,为了获得更多关于参与者经验和偏好的信息,我们提出了关于牛津功利主义量表(Oxford Utilitarian Scale)[52]、驾驶执照、驾驶频率、汽车拥有情况、参与者汽车的自动化水平以及车辆碰撞历史的后续问题。
为了促进透明和开放的科学实践,我们将完整的调查内容以及匿名收集的数据通过开放科学基金会对外公开[2]。
参与者通过众包平台Prolific[3]招募。招募共进行了三次:针对上述的时间压力预测试(N=15),测试我们设计的一般预测试(N=30),以及最终实验。在所有情况下,参与者都按照Prolific建议的小时费率7.52英镑获得报酬。为了确保工作质量,应用了以下筛选标准:参与者必须流利使用英语,并且在至少10个已完成的任务中拥有至少85%的任务通过率。基于预测试结果的功效分析(预期效应量0.25,α误差0.05,功效/1-β误差0.95,分子自由度10,组数6)得出实验需要400名参与者[53]。
第五部分 研究结果
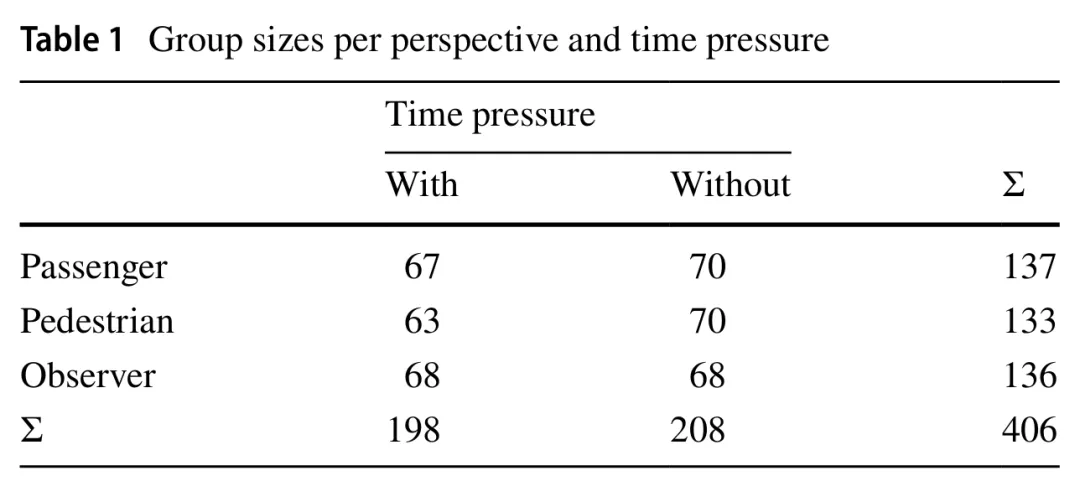
1.偏好行动
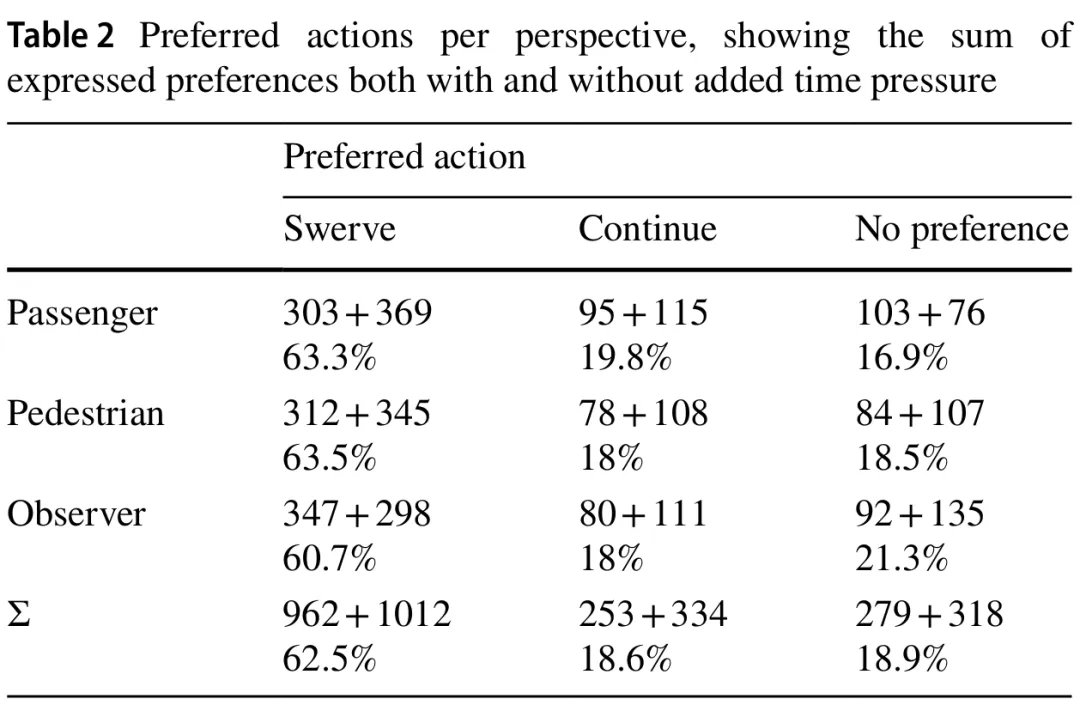
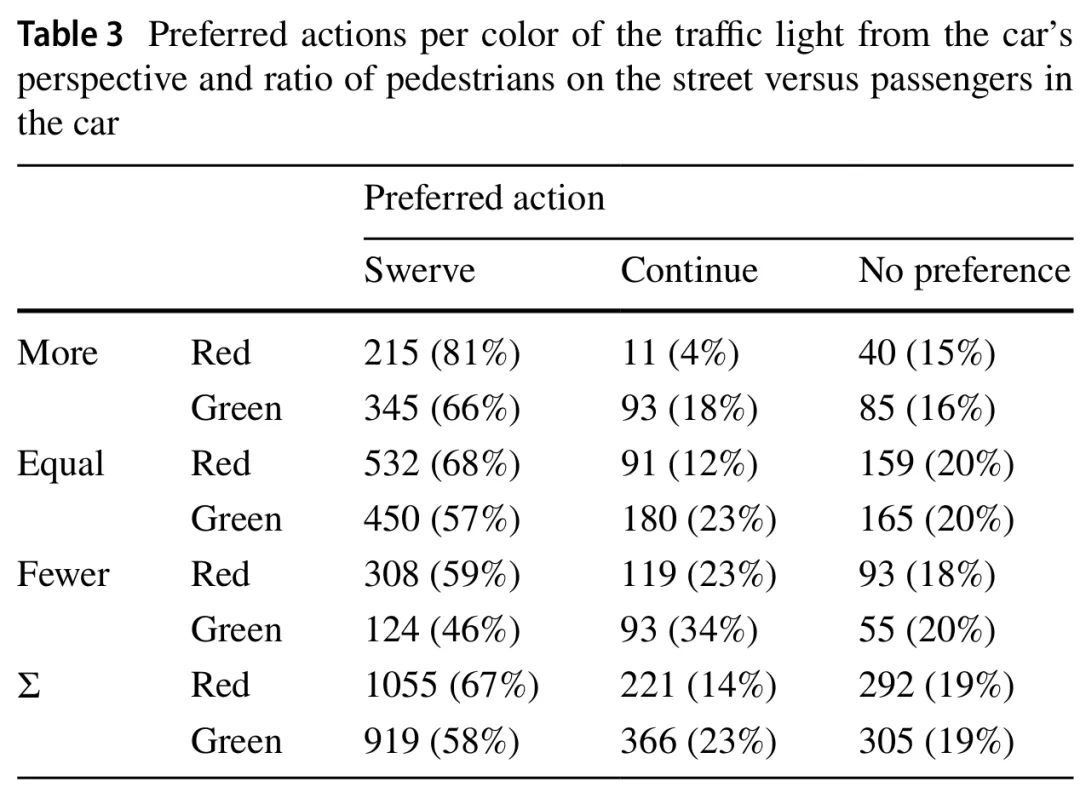
2.综合因素
Age:参与者的年龄(岁),范围18至81。
Male:如果参与者自认为男性则为1,否则为0。
Female:如果参与者自认为女性则为1,否则为0。
ATI:技术交互亲和力[51],范围1.33至6。
Utilitarian:牛津功利主义量表得分[52],范围10至63。
Fewer:如果路上的行人少于车内的乘客则为1,否则为0。
More:如果路上的行人多于车内的乘客则为1,否则为0。
Green:如果汽车的交通灯是绿色且汽车有路权则为1,否则为0。
Passenger:如果场景是从乘客视角呈现则为1,否则为0。
Pedestrian:如果场景是从行人视角呈现则为1,否则为0。
Time:如果参与者在回答时受到时间压力则为1,否则为0。
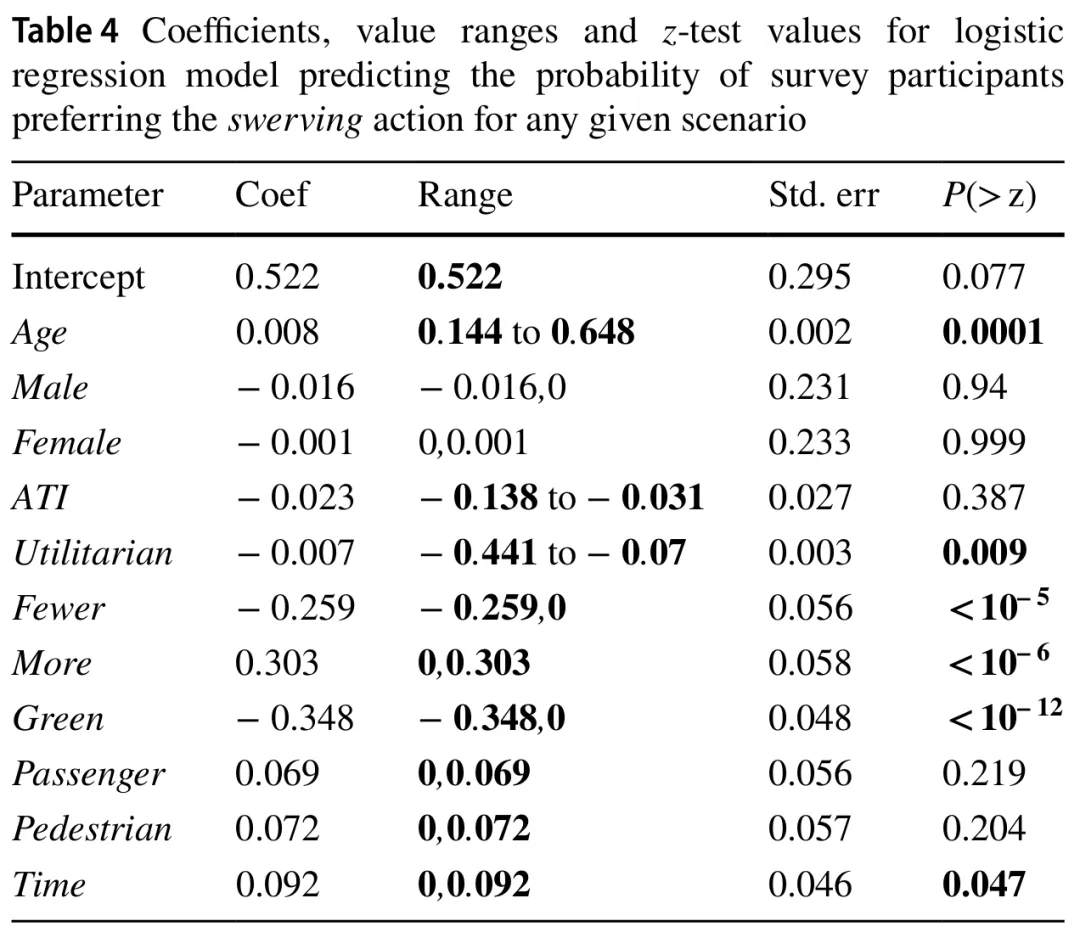
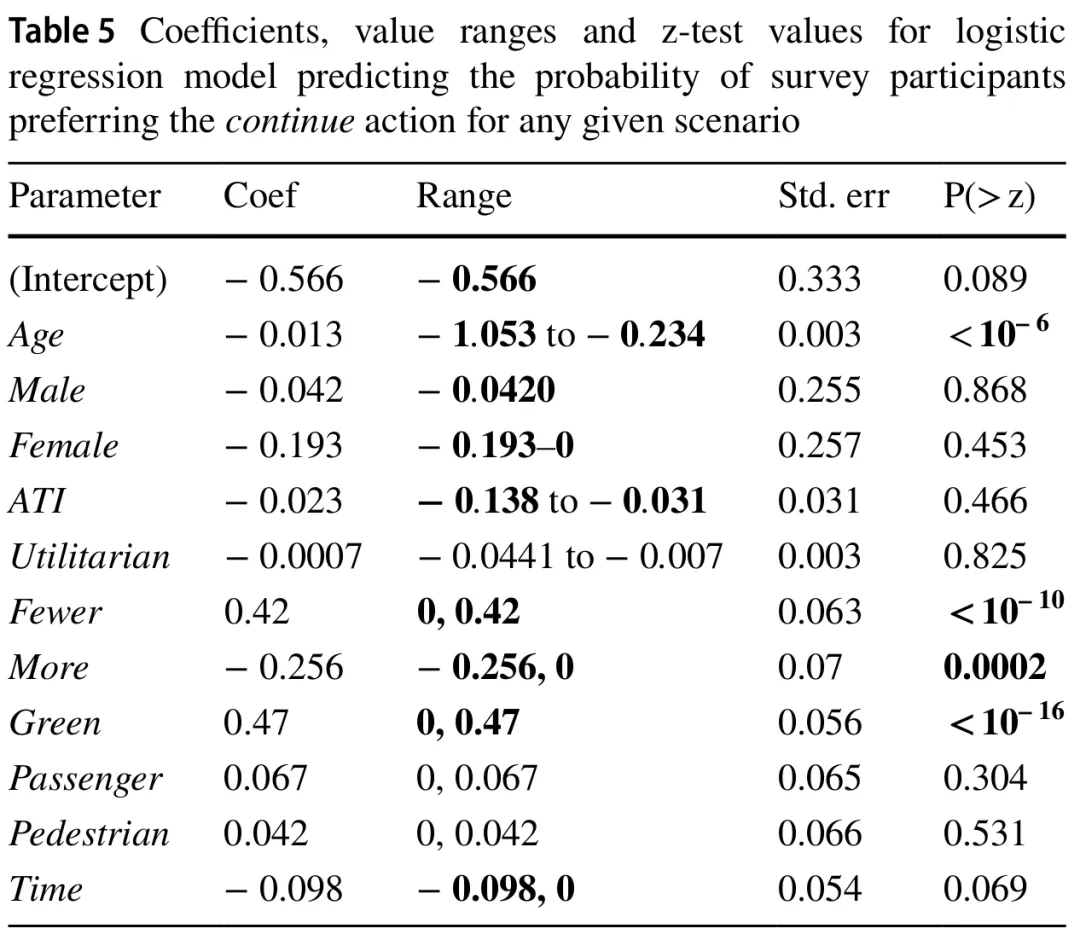
表4和表5分别显示了偏好转向或继续行驶的参数及其伴随的值域、标准误和z检验值。低于0.05的z检验值和幅度超过0.05的值域以粗体显示(注:请参考原文表格)。我们认为同时满足这两个标准的参数是相关的。对于代表多个不同可能选项的分类参数(如红灯/绿灯,或场景视角的乘客/行人/观察者),使用了独热编码。这种类型的建模仅使用N-1个选项作为输入以避免冗余信息。这意味着守法性由“Green”代表,可能的视角由“Passenger”和“Pedestrian”代表。
在观察预测转向的模型时,同时满足两个标准的参数是参与者的年龄和功利主义得分、行人和乘客的比例、交通信号灯的颜色以及施加的时间压力。比较这两个模型之间的这些参数,我们可以看到,除功利主义得分外,它们各自系数的符号都发生了翻转,而功利主义得分在预测“继续行驶”行动的模型中未能满足任一选择标准。年龄、交通信号灯颜色以及乘客与行人之间的比例仍然相关,而时间成分略微超过阈值。由于视角似乎对参与者的偏好没有相关影响,我们可以拒绝H1(见表4和表5中的“Passenger”和“Pedestrian”)。然而,H3得到了观察结果的支持,因为时间压力的存在增加了参与者选择转向的概率(见表4中的“Time”)。
当进行等效分析试图预测参与者未表达偏好的实例时,我们没有发现任何具有正向且显著系数的场景特定参数。为简洁起见,我们省略了这些非显著结果的表格。基于这种缺乏发现的情况,我们可以拒绝H2。尽管如表2所示,观察者视角的无偏好回答比例最高,但在考虑其他参数时,视角似乎不是一个显著的影响因素。
3.框架效应
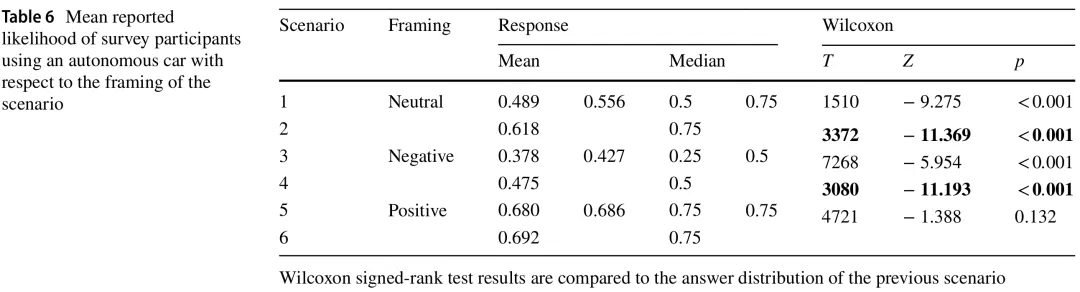
鉴于数据的非正态分布,我们使用威尔科克森符号秩检验来查看哪些回答可被视为具有差异。由于我们设计的顺序效应,我们将当前场景得分与前一个场景的得分进行比较,以调查增加的信息和框架对感知产生了什么影响。在表6中,我们显示了每个场景和框架的归一化平均回答以及统计比较的结果。特别是框架组块之间的威尔科克森结果是相关的,即场景2和3之间,以及场景4和5之间(以粗体显示)。我们发现,尽管所有场景都提到车辆表现出相当性能的现实世界情况,但正面或负面框架对受访参与者的平均回答有显著影响。这从而支持了H6和H7。
第六部分 讨论
1.困境视角的影响
这一比较发现对大多数自动驾驶车辆伦理调查的价值产生了相当严重的后果。毕竟,如果人们在此类大多采用图片描述场景的调查中报告的偏好,不能反映人们在更现实的设置(如VR)中的偏好,我们只能赋予它们有限的价值。目前伦理偏好调查的使用可能仍有价值,即它可以提高公众的认识,但其结果不能被仅凭表面采信。
2.自动驾驶车辆能力的框架
这似乎是“行为-意图差距”(behavior-intention gap)[54]的直接后果,即人们经常报告与他们在同一情况下实际表现出的行为不同的预测行为。此外,目前的技术发展,如自动驾驶车辆,是在“没有一个能赋予技术超越纯粹功利主义考量意义的健全文化框架”[55,p 1]的情况下发生的。对未知的恐惧反应是对呈现的不完整信息进行意义构建的一种方式——公众将从关于自动驾驶车辆能力的更现实和完整的信息提供中受益。
3.时间压力造成差异
这种“思考,快与慢”之间的区别可能会对自动驾驶车辆行动的评判产生后果。前述的相关工作表明,自动驾驶车辆受到更功利主义方式的评判,人们期望自动驾驶车辆经历一个完整的、“理性的”和预定的决策过程。然而,人类驾驶员因瞬间决策而得到谅解。他们的启发式反应是转向,而他们偏好自动驾驶车辆的启发式是紧急制动,无论情况如何[9]。与RQ4的结果相关,以现实的方式框架自动驾驶车辆的能力,包括它在时间压力下能做什么和不能做什么,可能会改变人们对自动驾驶车辆决策的评判。因此,重要的是:只要偏好调查被用作自动驾驶车辆行为的输入,调查参与者需要被教育了解人类和自动驾驶车辆事故场景之间的共性,更重要的是,了解它们之间的差异。
4.非二元决策选项的影响
尽管如此,仅仅增加一个决策选项就已经极大地改变了回应,并提供了与现有结果相比更多的见解和细节。这再次让人质疑我们能给予只有两个可能选项的决策场景多大的价值,因为i)在大多数现实世界场景中可能有超过两个选项,以及ii)仅提供两个答案,从而强迫人们做出选择,会导致部分偏差的结果。由于“道德机器”实验和类似结构的调查显式强迫人们做出二元价值判断,即使在不需要或不应做出此类判断的情况下也是如此[57],因此它不是确定可操作行为偏好的合适工具。
5.远离电车
基于我们的结果,我们特别主张未来的自动驾驶车辆伦理和能力讨论应考虑以下几点:
具有二元选项的简化“电车难题”给出了关于自动驾驶车辆挑战的不切实际的预期。
在讨论可能的自动驾驶车辆政策时,应谨慎对待自动驾驶车辆伦理偏好调查的结果。
人们对自动驾驶车辆能力和伦理困境选项的框架高度敏感。因此,任何关于自动驾驶车辆的讨论都应基于当前的技术现状及其伴随的挑战。
在不同设置的不同调查中发现的少数可推广的结果是,人们偏好挽救更多的人和挽救守法行为的人。这绝对可以作为关于自动驾驶车辆政策讨论的起点。然而,为了对自动驾驶车辆政策进行进一步的讨论和洞察,讨论需要转向对当前挑战更现实的框架。我们认为这可以通过不同的方式实现:
当征求非专业人士的意见时,场景应更接近现实设置。这可以通过增加更多决策选项、时间压力和交互式3D环境(如TrolleyMod[58])来实现。
在解释结果时,应结合专家见解和参与者特质。鉴于观察到的简单变量(如中性选项或时间压力)的增加对人们决策的影响,直接从这些偏好中得出结论是不负责任的。
任何关于自动驾驶车辆挑战和问题的框架,无论是在研究还是媒体语境中,都应该是现实的,并且对其能力保持透明,并且要比简单的类电车难题场景更宽泛。正如[59]所论证的,此类困境场景与现实世界的交通情况之间也存在实质性差异,这使它们在伦理上并不相似。从相关调查中得出任何结论时,需要仔细考虑这种不相似性。
遵循[41]的观点,社会不太可能就一套符合每个人偏好的通用伦理准则达成一致。相反,辩论应集中在我们认为不可接受(以及未来可能非法)的内容上。
第七部分 结论
为此,我们开展了一项伦理偏好调查,其中我们纳入了更现实的特征,如场景的不同视角、时间压力和非二元决策选项。此外,我们提供了自动驾驶车辆能力的不同框架,以调查它们如何影响用户接受度。我们发现我们没有复制早期的发现(即困境视角有影响),但报告了时间压力和非二元决策选项与当前的伦理调查相比影响了结果。此外,自动驾驶车辆能力的框架对用户偏好有直接影响。我们的结果强调了我们在解释伦理调查结果时需要采取的谨慎态度,以及此类调查并不是直接确定自动驾驶车辆政策的合适工具。
我们呼吁该领域将当前的讨论重新框架化,聚焦于现实的设置和挑战,以便对自动驾驶车辆决策有更实际的见解,并对自动驾驶车辆能力设定现实的预期;而不是在没有首先开发适当的框架来思考如何将此类偏好纳入与具体政策相关的结论之前,就依赖于在抽象和理论场景中表达的偏好。

参考文献(滑动阅览)
[1] Behere, S., Torngren, M.: A functional architecture for autonomous driving. In: 2015 First International Workshop on Automotive Software Architecture (WASA), IEEE, Montreal, Canada (2015)


