自动驾驶“做梦”就能变强?NVIDIA开源Cosmos-Drive-Dreams,雾天车道检测率暴涨9.4%!
- 2026-06-29 08:12:31
01开篇引言:当AI开始“脑补”驾驶世界
🌍 场景引入:想象一下,你正坐在自动驾驶汽车里,突然驶入一场伸手不见五指的浓雾,或者遭遇十年一遇的特大暴雨。这种极端天气,不仅人类司机手心冒汗,AI系统往往也会“两眼一抓瞎”。
⚠️ 现实痛点:为什么AI怕极端天气?因为数据太少了!在真实世界里,采集这种“边缘场景”的数据既危险又昂贵,就像为了学游泳非要等到发洪水,成本高到无法承受。
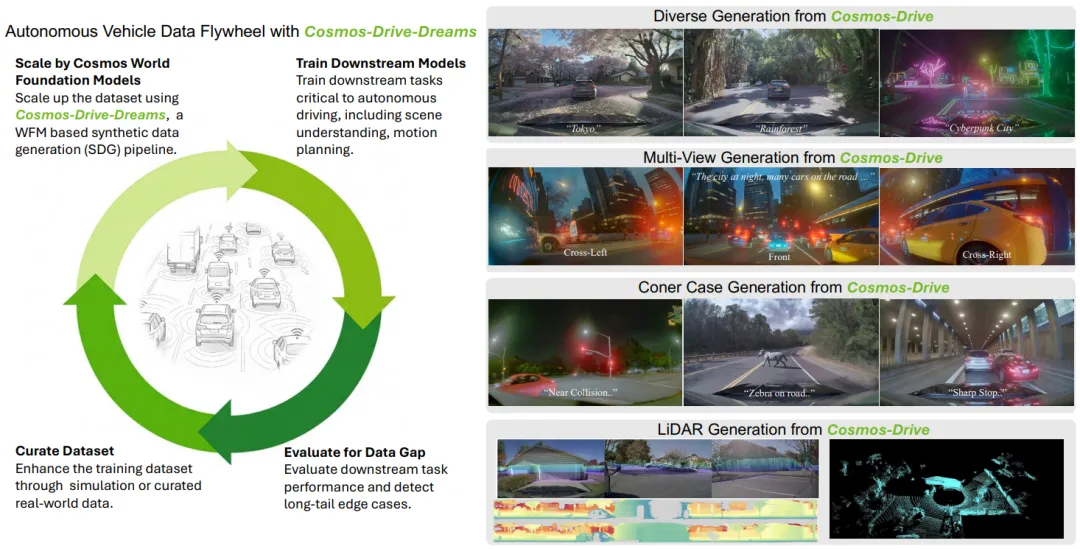
🔧 解决方案:NVIDIA最新开源的Cosmos-Drive-Dreams框架,就像给自动驾驶系统装了一个“造梦机”。它能基于物理世界规律,凭空生成各种极端路况的高清视频,让车在“梦境”里练车技,醒来就能从容应对现实挑战 [1]。
📋 论文速览:
📄 论文标题:Cosmos-Drive-Dreams: Scalable Synthetic Driving Data Generation with World Foundation Models 👤 核心作者:Xuanchi Ren, Yifan Lu 等 (NVIDIA Team) 🏛️ 研发机构:NVIDIA 📅 发布时间:2025年 🔗 论文地址:https://github.com/NVIDIA/Cosmos

02研究背景:为何要用“假”数据训练真车?
🔬 技术背景:自动驾驶模型通常是个“数据大胃王”,喂给它的数据越多,它越聪明。但现实中,99%的驾驶时间都是平平无奇的直行,那些真正致命的长尾场景(如暴雪、鬼探头)极其罕见 [1]。
📊 现有方案短板:
- 传统模拟器(如游戏引擎)
:优势是成本低,但画质一眼假,纹理和光影不够真实,AI在这个环境里训练出来的本事,到了真实世界容易“水土不服”(Domain Gap)。 - 早期生成式AI
:虽然画质好了,但不懂物理规律。比如生成的视频里,前一秒车还在左车道,后一秒突然瞬移到右边,缺乏时空一致性 [1]。
🎯 研究目标:打造一个既懂物理规律(车不会乱飞)、又画质逼真(像素级还原)、还能随意控制天气和视角的“世界模型”平台。


03核心技术:拆解“造梦工厂”的流水线
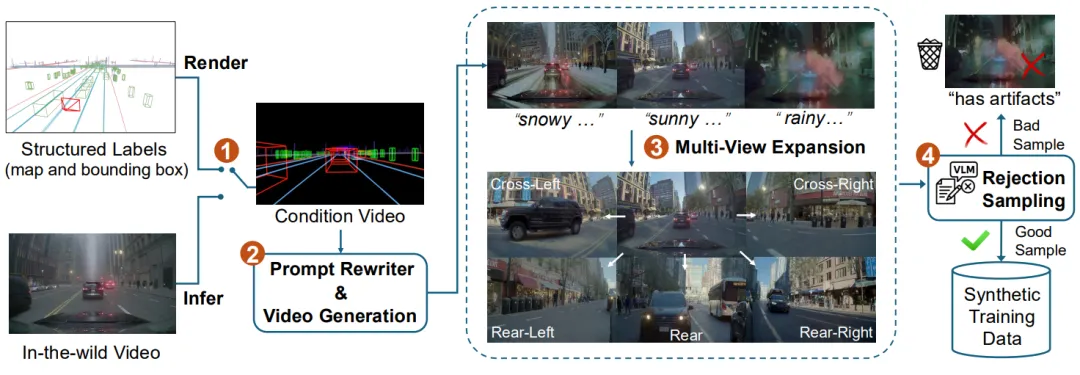
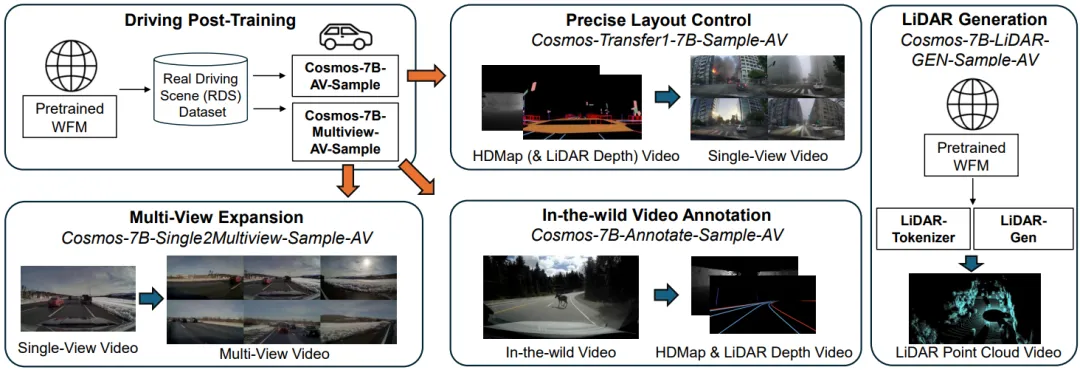
🏗️ 整体架构:Cosmos-Drive-Dreams 本质上是一个超级流水线,它基于 NVIDIA Cosmos 世界基础模型打造。简单来说,它的工作流程就像拍电影:先搭骨架(地图),再填肉体(生成视频),最后加特效(多视角扩展)。整个 Pipeline 分为四大步 [1]:
🔍 核心模块分步拆解:
- Step 1:素材准备 (Condition Data Curation)
就像盖房子先要有蓝图,系统会先提取HDMap(高精地图)、3D包围盒和LiDAR点云作为几何约束。AI得先知道路在哪,保证生成的车是压在路面上跑的。 - Step 2:单视角“造梦” (Single-View Generation)
利用 LLM 重写场景描述(如把“晴天”改成“暴雨午夜”)。调用 Cosmos-Transfer 模型,配合 ControlNet 技术,确保生成的视频严格遵守车道线和红绿灯的位置,指哪打哪 [1]。 - Step 3:全景扩展 (Multi-View Expansion)
利用 Cosmos-7B-Single2Multiview 模型,根据前视视频,推想出左侧、右侧、后侧等其他 5 个视角的画面,并保证所有画面在时间和空间上是同步的。 - Step 4:质量安检 (Rejection Sampling)
系统雇佣了一个“AI质检员”(VLM视觉语言模型),自动筛查掉那些不符合物理常识的视频,只保留高质量的“精华” 。
04实验效果:雾天车道检测提升9.4%
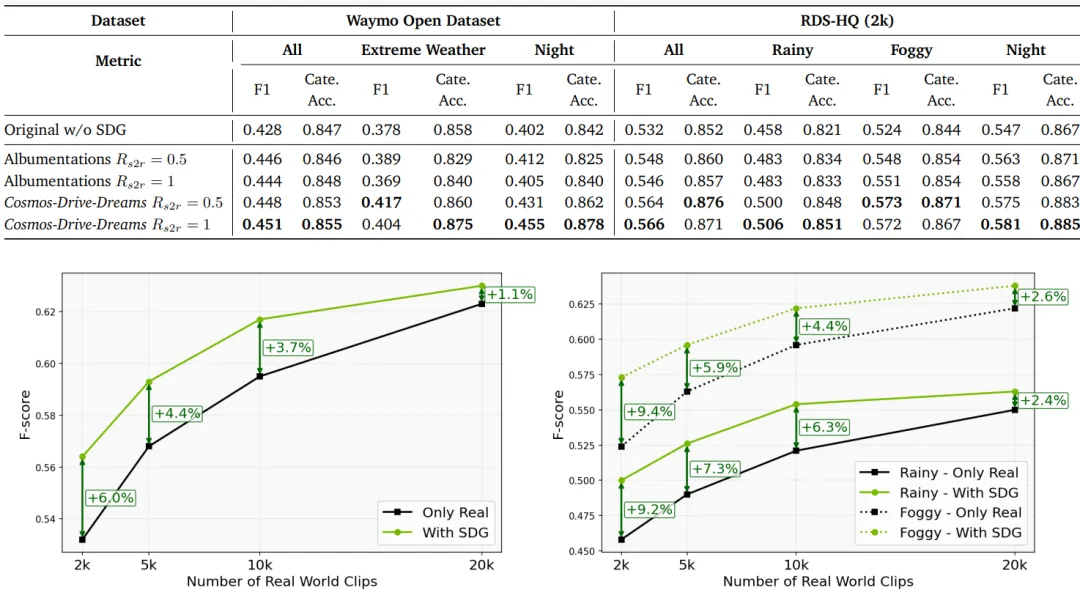
📋 实验基础信息:研究团队生成了一个包含 81,000 个视频片段(约200小时)的合成数据集,并将其混合到真实数据中训练下游任务 [1]。
📊 核心结论提炼:
在 3D车道检测 任务中,使用合成数据增强后:
🌧️ 雨天场景:F-Score 提升 10.4% 🌫️ 雾天场景:F-Score 提升 9.4% 📈 总体提升:即便在数据量很少的情况下(仅用2000个真实片段),混合合成数据也能带来 6.0% 的性能飞跃 [1]。
👀 定性效果展示:对比视频显示,仅用真实数据训练的模型,在面对从未见过的积水路面时,车道线识别会抖动;而经过 Cosmos 数据“特训”的模型,在暴雨中也能稳稳锁住车道线。
05总结展望:从“被动采集”到“主动创造”
🎯 核心贡献:
- 技术突破
:证明了世界模型不仅能生成好看的视频,还能真正理解物理规律,用于训练严肃的自动驾驶系统 [1]。 - 落地优势
:降低了自动驾驶研发的门槛,中小团队也能用高质量合成数据训练模型。
💬 互动引导:“如果是你,你最希望自动驾驶汽车在虚拟世界里通过哪种‘地狱级’考试才上路?是暴雪山路,还是早高峰的十字路口?欢迎在评论区聊聊~”

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 395匹干不过335匹?80万级豪华SUV实测对决,结果让人意外
- 实测百万SUV四驱性能:揽胜运动把雷克萨斯GX按在地上摩擦,差距太明显了
- 30万级豪华SUV抉择:沃尔沃全新XC70对比奥迪Q5L谁更值
- BMW X5|豪华SUV公路之王
- 四台百万级SUV硬刚泥坡,陆巡居然翻车了?这结果我也没想到
- 宝马X3|年轻人的第一台SUV,你心动了吗
- 2025年卖爆的SUV盘点,纯油前两名卖了47万+辆,来自同一品牌
- 当“AI私人助理”上车,这4款20万级SUV重新定义家庭出行
- 20万内六座SUV怎么选?这三款闭眼入不后悔!
- 实测8款热门SUV爬坡:荣放趴窝、途观干烧,最后赢家我也没想到
