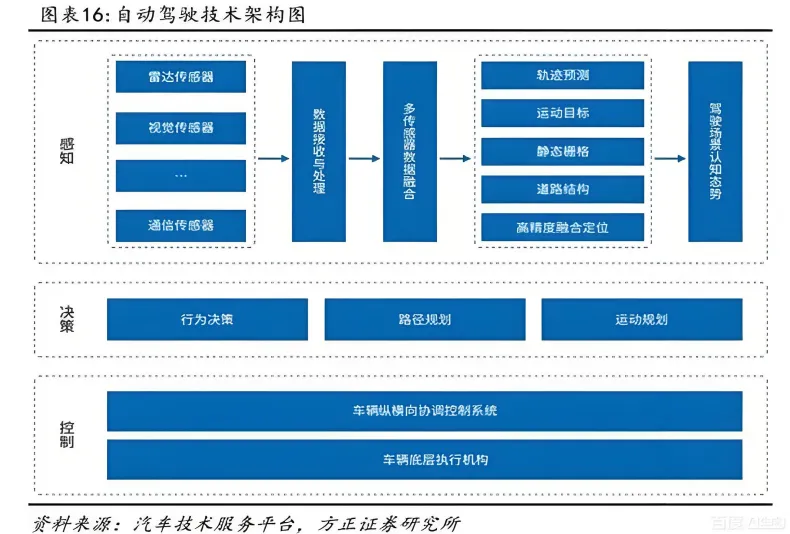
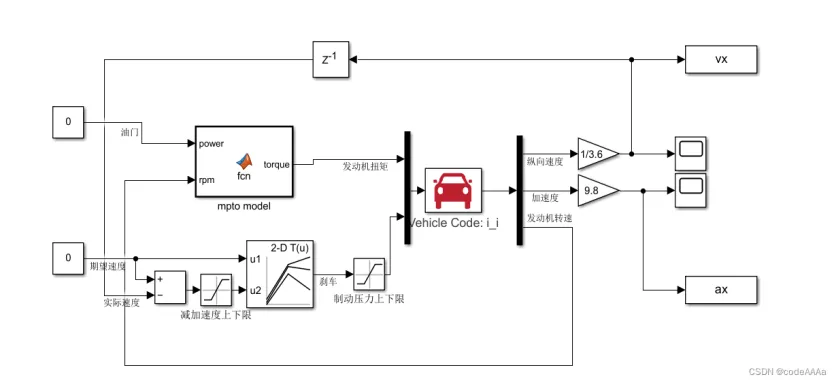
聊横纵向控制之前,得先明确它在整个自动驾驶系统中的位置。当前量产主流的自动驾驶方案,依然是“模块式架构”——把复杂的系统拆解为感知、定位、预测、规划、控制五大核心模块,各个模块各司其职、数据互通,最终形成“环境感知-决策规划-执行控制”的完整闭环。
我们可以用“开车”的逻辑来理解这个架构:
感知模块:相当于“眼睛和耳朵”,通过摄像头、激光雷达、毫米波雷达等传感器,识别周围的车辆、行人、骑行者、交通灯、车道线等环境元素,输出目标的位置、速度、姿态等信息;
定位模块:相当于“导航地图+指南针”,通过高精地图、GNSS、IMU等技术,精准确定车辆自身在世界坐标系中的位置,误差通常要求厘米级;
预测模块:相当于“预判能力”,基于感知和定位结果,预测周围交通参与者的未来行为(比如前车是否会变道、行人是否会横穿马路),为规划模块提供决策依据;
规划模块:相当于“大脑决策”,结合感知、定位、预测结果和导航路线,制定车辆的行驶策略,包括纵向的加速/减速/跟车方案,以及横向的车道保持/变道/转弯路径;
控制模块:相当于“手脚”,把规划模块输出的抽象策略(比如“保持60km/h速度行驶”“沿这条曲线变道”),转化为车辆执行器(油门、刹车、方向盘)的具体控制指令,确保车辆精准、平稳地完成驾驶动作。
从数据流向来看,感知、定位、预测模块为规划模块提供输入,规划模块输出“纵向速度曲线”和“横向参考路径”两大核心指令,这正是横纵向控制模块的直接输入。可以说,控制模块是自动驾驶系统与车辆执行器之间的“桥梁”,再好的感知、再优的规划,若没有可靠的控制算法支撑,也无法实现稳定的驾驶体验。
横纵向控制模块本质上是“双分支并行工作”的结构:横向控制负责“转向”,确保车辆沿着规划的路径行驶;纵向控制负责“加速/减速”,确保车辆的速度符合规划要求。两者既独立工作,又协同配合——比如变道场景中,横向控制调整方向盘实现路径偏移,纵向控制同步微调速度保证变道平稳,避免出现侧翻或追尾风险。
1. 横向控制
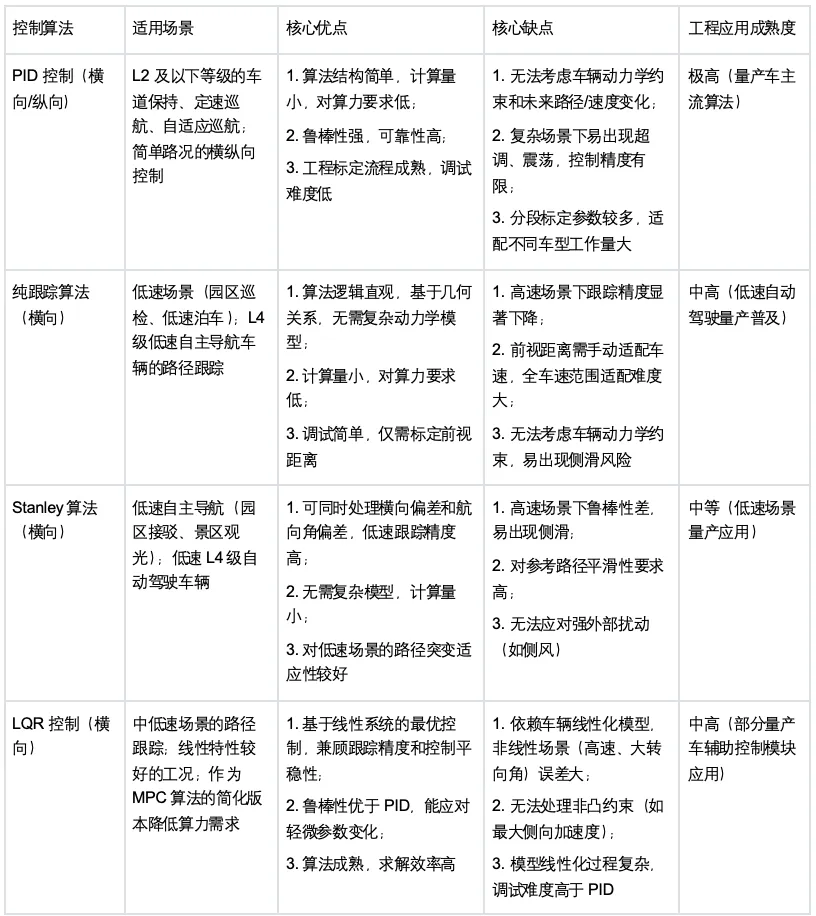
横向控制的核心目标是“路径跟踪”,即控制车辆的转向角,使车辆实际行驶轨迹与规划模块输出的参考路径(通常是车道中心线或变道曲线)保持一致,同时保证转向过程平稳、无过度震荡。常见的应用场景包括:低速园区巡检、城市道路车道保持、高速变道、无保护左转、环岛行驶等。根据车速、场景复杂度的不同,工程上会选择不同的横向控制算法,从简单的几何类算法到复杂的模型预测控制,覆盖不同等级的自动驾驶需求。当前主流的横向控制算法包括:PID控制、纯跟踪算法、Stanley算法、LQR控制、最优预瞄控制、模型预测控制(MPC)、滑模控制。
(1)PID控制
PID控制是工业控制领域的经典算法,也是自动驾驶横向控制的“基础款”,在L2及以下等级的车道保持功能中应用最广。它通过比例(P)、积分(I)、微分(D)三个环节的组合,根据“偏差”来调节控制量:
比例环节(P):直接根据当前偏差(横向偏差、航向角偏差)大小输出控制量,偏差越大,转向角调整越明显,核心作用是“快速纠偏”;
积分环节(I):累计历史偏差,解决比例环节无法消除的“静态偏差”(比如车辆因负载不均、轮胎磨损导致的轻微跑偏);
微分环节(D):根据偏差的变化率预测未来偏差趋势,提前调整控制量,核心作用是“抑制震荡”,让转向更平稳。
工程上,横向PID控制的输入通常是“横向偏差”(车辆质心到参考路径的垂直距离)和“航向角偏差”(车辆实际航向与参考路径切线方向的夹角),输出是“方向盘转角指令”。由于算法结构简单、计算量小、鲁棒性强,PID控制是量产车横向控制的“标配”,但它无法考虑车辆动力学约束和未来路径变化,在高速、急弯等复杂场景下易出现超调、震荡。
(2)纯跟踪算法
纯跟踪算法是一种基于几何关系的路径跟踪算法,核心逻辑非常直观——模拟人类驾驶员“盯目标点”的驾驶习惯,通过计算使车辆行驶轨迹经过预设的“前视目标点”,从而实现路径跟踪。它的核心原理是:在参考路径上选取一个距离车辆当前位置一定距离的前视目标点,根据车辆当前位置、前轴中心位置与目标点的几何关系,计算出所需的转向角,使车辆前轴中心沿着圆弧轨迹到达目标点。
纯跟踪算法的优势在于“简单易懂、无需复杂模型”,仅需知道参考路径的坐标信息和车辆当前位置,就能计算出转向角,计算量极小,非常适合低速场景(如园区巡检、低速泊车)。但它的缺点也很明显:前视距离的选择直接影响控制效果,低速时需选短前视距离保证精度,高速时需选长前视距离保证稳定性,难以通过固定前视距离适配全车速范围;且无法考虑车辆动力学约束,高速场景下路径跟踪精度会显著下降。
(3)Stanley算法
Stanley算法是斯坦福大学为自主驾驶车辆Stanley设计的横向控制算法,专为低速自主导航场景(如园区、景区观光车)优化,核心优势是能同时处理“横向偏差”和“航向角偏差”,且对低速场景的路径跟踪精度较高。它的控制律由两部分组成:一部分是针对横向偏差的比例控制,另一部分是针对航向角偏差的反馈控制,通过加权组合输出最终的转向角指令。
与纯跟踪算法类似,Stanley算法也无需复杂的车辆动力学模型,计算量小、调试简单,适合低速、低动态的场景。但它的局限性也很突出:高速场景下,由于未考虑车辆的侧向加速度约束,易出现侧滑风险;且对参考路径的平滑性要求较高,若路径存在突变(如急弯、折线),控制效果会明显下降。目前,Stanley算法主要应用于低速L4级自动驾驶车辆(如园区接驳车)。
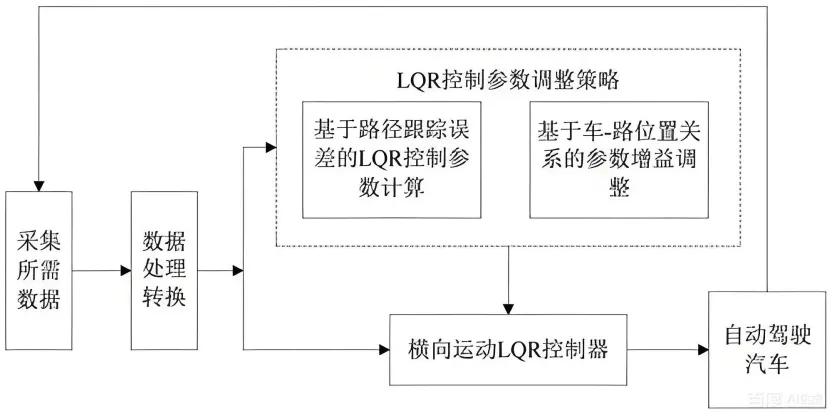
(4)LQR控制
LQR(线性二次型调节器)是一种基于线性系统的最优控制算法,核心目标是在满足系统约束的前提下,最小化由状态偏差和控制量组成的二次型性能指标(比如“路径跟踪偏差最小”+“转向角变化最平滑”)。在横向控制中,LQR需要先建立车辆的线性化动力学模型(通常是简化的“单车模型”或“动力学模型”),将横向偏差、航向角偏差、侧向速度等作为状态变量,将转向角作为控制变量,通过求解黎卡提方程得到最优控制律。
LQR的优势在于:能在 linear 系统框架下实现“最优控制”,兼顾跟踪精度和控制平稳性;鲁棒性优于PID控制,能应对轻微的车辆参数变化。但它的缺点是依赖车辆的线性化模型,而实际车辆是强非线性系统(尤其是高速、大转向角场景),线性化模型的误差会导致控制精度下降;且无法处理非凸约束(如最大转向角限制),在复杂场景下的适应性有限。工程上,LQR常应用于中低速、线性特性较好的场景,或作为MPC算法的简化版本降低算力需求。
(5)最优预瞄控制
最优预瞄控制的核心思路是“模拟人类驾驶员的预瞄特性”——人类驾驶员开车时,不会只盯着车头前方的路面,而是会提前预瞄前方一段距离的道路,根据预瞄点的信息调整转向。最优预瞄控制正是基于这一原理,通过选取前方多个预瞄点,建立预瞄偏差与控制量的关系,求解最优预瞄点和对应的控制指令,使车辆沿参考路径行驶。
该算法的优势在于:能提前感知参考路径的变化(如前方弯道、变道),提升高速场景下的路径跟踪稳定性;通过优化预瞄距离,可适配不同车速(高速时增大预瞄距离,低速时减小)。但它的缺点是预瞄点的选取和权重设计依赖经验,且需要精准的车辆定位信息,在定位误差较大的场景下控制效果会下降。目前,最优预瞄控制常与PID、LQR结合使用,提升高速车道保持的稳定性。
(6)模型预测控制(MPC)
随着自动驾驶等级提升,车辆需要应对变道、环岛、高速急弯等更复杂的横向场景,PID、纯跟踪等简单算法的局限性逐渐显现。此时,模型预测控制(MPC)凭借其“预测未来、滚动优化”的特性,成为L3及以上等级自动驾驶横向控制的核心算法。
MPC的核心逻辑是“预测未来、滚动优化”:
1. 建立车辆动力学模型:精准描述车辆的运动特性(如转向角与侧向加速度、横摆角速度的关系),明确车辆的物理约束(最大转向角、最大侧向加速度等);
2. 预测未来状态:基于当前车辆状态和控制指令,预测未来一段时间内(通常是0.5-2秒)车辆的行驶轨迹;
3. 滚动优化:以“车辆实际轨迹与参考路径的偏差最小”“控制量变化最平滑”“侧向加速度不超过安全阈值”为目标,在物理约束范围内,求解最优的控制指令序列;
4. 实施并更新:只执行最优序列的第一个控制指令,然后根据新的车辆状态和环境信息,重新进行预测和优化,实现“滚动式”调整。
MPC的优势在于能够提前考虑未来路径和车辆约束,在复杂场景下的路径跟踪精度和稳定性远优于其他算法,但它的计算量较大,对车载控制器的算力要求较高,且模型的准确性直接影响控制效果。
(7)滑模控制
滑模控制是一种非线性控制算法,核心特点是“鲁棒性强”——能够有效应对车辆参数变化(如负载变化、轮胎磨损)和外部扰动(如侧风、路面附着系数变化),在极端场景下(如冰雪路面转向、高速急弯)仍能保持稳定的控制效果。
其核心逻辑是:设计一条“滑动模态面”(通常是横向偏差和航向角偏差的线性组合),通过切换控制策略,迫使车辆状态沿着滑动模态面运动,最终收敛到参考路径。由于控制策略是“不连续切换”的,滑模控制会存在一定的“抖振”现象(即转向角小幅高频波动),需要通过边界层设计、饱和函数等方法进行抑制。目前,滑模控制多应用于特殊场景的辅助控制,或与MPC算法融合使用,提升系统的鲁棒性。
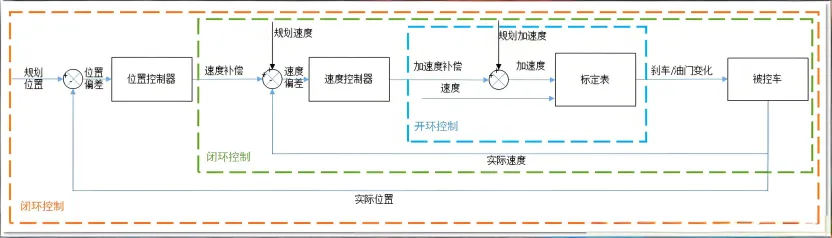
2. 纵向控制
纵向控制的核心目标是“速度跟踪”和“安全跟车”,即控制车辆的油门和刹车,使车辆的实际速度精准跟踪规划模块输出的速度曲线,同时在跟车场景下,与前车保持安全距离,避免追尾。常见的应用场景包括:定速巡航(CC)、自适应巡航(ACC)、跟车行驶、红绿灯启停、紧急制动等。纵向控制的核心挑战在于:车辆的动力响应存在延迟(比如踩油门后,动力传递需要时间),且不同工况下(加速、减速、匀速)的动力学特性差异较大。当前主流的纵向控制算法主要包括:PID控制、模型预测控制(MPC)、模糊控制,其中PID控制是量产车的主流选择,MPC则用于高阶纵向控制场景。
(1)PID控制
与横向控制类似,纵向PID控制的输入是“速度偏差”(规划速度与实际速度的差值),输出是“油门开度”或“刹车压力”指令。为了适应不同工况,工程上通常会采用“分段PID”策略——在加速工况、匀速工况、减速工况下,分别标定不同的P、I、D参数,确保各场景下的速度跟踪精度和平稳性。
例如,在加速工况下,适当增大P参数以提升加速响应速度;在匀速工况下,减小P参数、增大D参数以避免速度震荡;在减速工况下,根据减速需求的紧急程度,切换不同的PID参数组(常规减速、紧急减速)。由于算法简单、可靠性高,PID控制仍是当前量产车纵向控制的主流算法,尤其是在L2级自适应巡航功能中。
(2)模型预测控制(MPC)
在复杂的纵向场景中(比如城市道路跟车、红绿灯启停、高速加减速变道),PID控制的局限性同样存在——无法考虑车辆的动力约束(比如最大加速度、最大减速度)和未来的速度变化趋势,容易出现“跟车过近”“启停顿挫”等问题。此时,MPC算法凭借其“预测优化”的特性,成为高阶纵向控制的核心选择。
纵向MPC的核心逻辑与横向MPC一致,区别在于建立的是“车辆纵向动力学模型”(描述油门/刹车指令与车辆加速度、速度的关系),优化目标包括“速度偏差最小”“加速度变化率最小”“与前车距离安全”等。例如,在红绿灯启停场景中,MPC可以提前预测红灯时长和前车启停状态,规划平滑的加减速曲线,避免急加速、急刹车导致的顿挫感;在高速跟车场景中,MPC可以根据前车速度变化趋势,提前调整本车速度,保持安全跟车距离的同时,提升乘坐舒适性。
(3)模糊控制
模糊控制是一种基于规则的非线性控制算法,核心特点是“无需精准模型”——通过模拟人类驾驶员的驾驶经验,将“速度偏差大”“跟车距离近”等模糊信息,转化为具体的控制指令。例如,人类驾驶员会根据“前车速度慢、距离近”的经验,果断踩刹车;根据“前车速度快、距离远”的经验,缓慢踩油门。
模糊控制的优势在于对模型误差和外部扰动的适应性强,适合应用于城市道路等复杂纵向场景(比如行人横穿导致的紧急减速、前车频繁加减速的跟车场景)。但它的缺点是控制规则需要依赖大量的人工经验,且在高精度速度跟踪场景下的表现不如MPC算法。因此,模糊控制通常作为PID或MPC算法的辅助补充,用于复杂工况的应急控制。
3. 主流横纵向控制算法优缺点对比
在实验室里调好的控制算法,到了实车上面往往会出现各种问题——比如参数漂移、场景适配性差、稳定性不足。这也是很多算法工程师从“理论”走向“工程”的必经之路。结合10年的开发经验,我总结了横纵向控制工程应用的4个核心注意事项,都是实打实的实操技巧,覆盖参数标定、车辆适配、鲁棒性设计、延迟补偿,希望能帮大家少踩坑。
1. 参数标定
控制算法的性能,很大程度上取决于参数的标定质量——尤其是PID、LQR、纯跟踪这些依赖参数的算法,参数选择不当,再好的算法框架也无法发挥作用。工程上的核心技巧是“分场景、分车型、分工况”精细化标定,而不是追求“一套参数通吃所有场景”。
以横向算法标定为例,我的经验是:
纯跟踪算法:重点标定“前视距离”,采用“车速-前视距离”映射表,低速时前视距离取0.5-1m,高速时取3-5m,避免固定前视距离导致的高速震荡、低速精度不足;
PID算法:先在平坦路面、匀速工况下确定基础参数,再针对高速、急弯、侧风等场景细化参数——比如高速场景增大D参数提升稳定性,急弯场景增大P参数提升纠偏速度;
LQR算法:重点调整状态权重和控制权重,平衡跟踪精度和控制平稳性——比如路径跟踪精度要求高时,增大横向偏差的权重;乘坐舒适性要求高时,增大转向角变化率的权重;
动态自适应标定:通过实车路测收集大量数据,建立“场景-参数”映射模型,实现参数的动态自适应调整——比如根据车速、路面附着系数,自动切换参数组。
纵向PID标定则要重点关注“工况切换平滑性”,比如加速转匀速、匀速转减速时,参数要渐变过渡,避免出现速度突变导致的顿挫感。
2. 车辆适配
对于LQR、MPC这类基于模型的控制算法,车辆动力学模型的准确性直接决定控制效果。而实车的动力学参数(比如轮胎附着系数、转向迟滞、动力响应延迟、车辆质量)会随着车速、负载、路面条件的变化而变化,这就要求我们在工程上做好“模型适配”和“参数实时更新”。
我的实操技巧包括:
建立“简化+精准”的动力学模型:不追求过度复杂的模型(否则计算量过大),而是保留核心参数——横向模型重点保留“转向迟滞、侧向刚度”,纵向模型重点保留“动力响应延迟、制动效能”;
实时估计关键参数:通过传感器数据(轮速、加速度、转向角、横摆角速度),实时估计轮胎附着系数、车辆负载等变化参数——比如在冰雪路面,实时检测轮胎附着系数下降,调整MPC的侧向加速度约束,避免侧滑;
提前做“车型适配测试”:针对每款车型,在不同负载(空载、满载)、不同温度(高温、低温)、不同路面(沥青、水泥、冰雪)条件下,进行大量动力学测试,建立参数数据库,为模型提供基础数据支撑。
3. 鲁棒性设计
自动驾驶车辆行驶在复杂的真实道路上,难免会遇到各种扰动(比如侧风、路面颠簸、前车突发变道)和故障(比如传感器噪声、执行器延迟、定位漂移)。控制模块的鲁棒性设计,直接决定了自动驾驶的安全性。工程上的核心思路是“多层级防护”,包括扰动抑制、故障诊断、降级策略。
具体实操技巧:
扰动抑制:在控制算法中加入“扰动观测器”,实时估计外部扰动(比如侧风导致的横向偏移、路面颠簸导致的速度波动),并通过控制指令补偿——比如检测到侧风时,轻微调整转向角抵消侧风影响;
故障诊断:实时监测传感器数据和执行器状态,若发现异常(比如转向角传感器故障、刹车延迟过大、定位误差超标),立即触发故障报警;
降级策略:预设多套降级方案,根据故障严重程度切换——比如轻微传感器噪声时,启用滤波算法优化输入;MPC算法故障时,切换到PID算法;严重执行器故障时,立即退出高阶控制模式,提示驾驶员接管。
4. 延迟补偿
车辆的执行器(油门、刹车、方向盘)存在天然的响应延迟——比如控制模块输出转向角指令后,方向盘需要0.1-0.3秒才能达到目标角度;输出油门指令后,车辆动力需要0.2-0.5秒才能响应。这种延迟会导致控制精度下降,甚至出现震荡,尤其是高速场景下,延迟的影响会被放大。工程上必须做好“延迟补偿”。
我的常用补偿技巧:
预测补偿:通过历史数据建立“延迟模型”,预测未来0.3-0.5秒的车辆状态,提前输出控制指令——比如根据当前横向偏差,预测延迟后的偏差大小,提前调整转向角;
相位超前补偿:在PID的微分环节加入相位超前校正,抵消延迟导致的相位滞后,提升系统的稳定性;
执行器动态建模:在MPC、LQR等模型类算法中,加入执行器的动态模型,将延迟特性融入控制优化过程——比如MPC算法中,将执行器延迟作为约束条件,求解最优控制指令。
近年来,“端到端自动驾驶”成为行业热点——通过深度学习模型,直接将传感器数据转化为控制指令,省去了感知、规划等中间模块,看似简化了系统架构。但很多人因此产生疑问:未来端到端时代,横纵向控制模块还需要吗?
作为一名资深控制算法工程师,我的答案是:无论技术如何迭代,控制模块的核心作用都无可替代。原因很简单:自动驾驶的终极目标是“安全、平稳地控制车辆”,而控制模块是直接对接车辆执行器的“最后一环”——端到端模型的输出,本质上依然是控制指令;即使中间模块被简化,最终仍需要控制算法将抽象的指令转化为符合车辆动力学特性的具体动作,避免执行器饱和、车辆失控。
更重要的是,控制模块是自动驾驶的“最后一道安全关”。当感知、规划模块出现异常时,控制模块的鲁棒性设计和降级策略,能够确保车辆不会失控;当遇到极端场景时,控制模块的精准控制能力,能够最大限度地保障驾乘人员和道路参与者的安全。比如端到端模型输出的转向角指令超出车辆最大转向角约束时,仍需要控制模块进行限幅处理;模型输出的加速度过大时,需要控制模块结合路面附着系数进行调整,避免侧滑、抱死。
从模块式到端到端,自动驾驶技术在不断进化,但控制模块的核心价值始终未变——它是连接“算法意图”与“车辆动作”的桥梁,是实现自动驾驶安全落地的关键支撑。对于算法工程师而言,深耕控制算法,做好工程落地,不仅是技术积累,更是对自动驾驶安全的责任担当。毕竟,再先进的技术,最终都要回归到“平稳、安全”的驾驶本质上。