【场景挖掘】自动驾驶复杂场景挖掘(一):时序匹配规则实践
- 2026-02-19 07:53:24
时序状态匹配机制:从模糊需求到精准场景挖掘
在李众力大佬的文章中,
【L4自动驾驶数据闭环实战04】云端标签中枢:从 FreeDM 到 FastDM 的秒级特征空间
扛枪,公众号:扛枪特AI玩【L4自动驾驶数据闭环实战04】云端标签中枢:从 FreeDM 到 FastDM 的秒级特征空间
详细描述了整个云端平台的挖掘逻辑,令人叹为观止,也是我们所在企业的推进方向。正如文章所述,FastDM 更多是 "秒级标签 + 简单 Session 聚合",当需要判断复杂时序模式时,就要用 Trigger 框架。但复杂场景主要使用到的时序匹配机制,没有进行详细描述,在这里结合实践谈谈一种匹配方法。
一、为什么需要多阶段状态匹配?
1.1 用户需求的模糊性
在自动驾驶数据挖掘的实际工作中,我们经常遇到这样的场景:
产品经理:"我们需要挖掘前向制动场景的数据"
数据工程师:"具体什么样的制动场景?"
产品经理:"就是车停下来的场景啊"
算法工程师:"是紧急制动还是正常停车?是跟车制动还是红灯制动?需要包含起步吗?"
产品经理:"哦,原来还有这么多细节..."
这反映了一个普遍问题:用户往往不能一开始就明确表达所有需求,但实际上需要非常详细的场景信息。对于前向制动场景,用户实际可能需要捕捉到:
开始减速的瞬间
完全刹停的状态
等待时间
再次起步的动作
这些细节对于算法训练和评测至关重要。
1.2 评测与算法需求
对于评测需求和 VLA(Vehicle Level Assessment)等算法,详细的场景过程信息尤为重要。以 Alpamayo-R1 的因果链数据集标注为例:
从CoC数据集看场景标注需求
公众号:智猩猩Auto英伟达Alpamayo-R1一段式VLA架构技术深度解析
Alpamayo-R1 核心的 "因果链(Chain of Causation, CoC)" 数据构建流水线,解决了自动驾驶大模型只会 "描述画面" 而不懂 "因果逻辑" 的问题。
因果链数据集设计理念
传统的图文数据通常是泛泛而谈,而 CoC 强制要求模型建立 **[关键观察] -> [驾驶决策]** 的强因果连接。
五步流水线技术拆解
阶段一:什么时候标?(时序对齐)
Step 1: 筛选高价值片段:只挑选包含显式驾驶决策的片段,平直空旷道路的数据会被过滤
Step 2: 锁定关键帧:定位决策时刻,让模型学习在 "动作发生前" 进行预判
阶段二:标什么?(结构化因果)
Step 3: 提取致因要素:只标注导致当前决策的物体,忽略无关背景
Step 4: 确定驾驶原子动作:将复杂驾驶行为拆解为结构化的纵向 + 横向原子决策
Step 5: 合成推理链:将结构化信息生成自然语言描述
这种详细的时序信息捕捉,正是我们的状态匹配机制要解决的问题。
二、问题背景:从数据到场景的鸿沟
在自动驾驶的复杂场景数据挖掘需求中,经过上游数据预处理阶段的提取,我们通常面临的是这样的输入数据:2.1 输入数据形式
大宽表形式:包含自车、他车、交通基础设施等多维度数据的时序大表
多表关联形式:自车表、他车表、道路设施表等多张时序小表
数据格式:可能是 ODPS SQL 表、Pandas DataFrame 或其他时序数据结构
时间粒度:可能为1Hz的较稀疏信号或5或10Hz(每 100ms 一条记录)的高频信号数据
2.2 核心挑战
如何从海量的时序数据中,精准匹配出符合特定驾驶场景的片段?例如:
他车变道切入场景
异常右变道至最右车道停车场景
跟车加减速场景
交叉口通行场景
这些场景本质上都是时序状态的转移序列,传统的规则匹配很难高效处理这类问题。
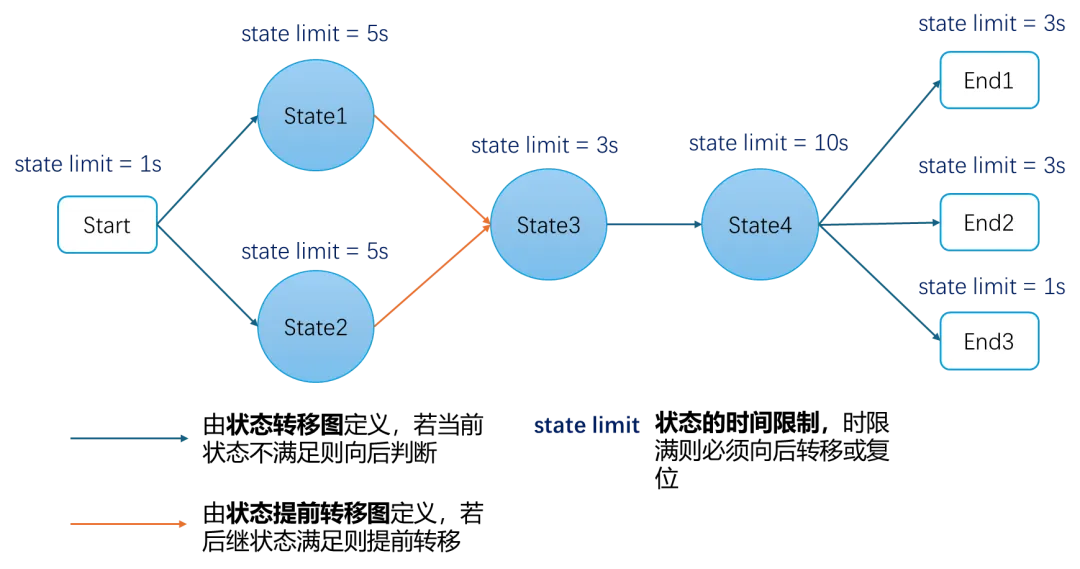
三、核心思路:基于状态机的时序匹配框架
我们设计了一套基于状态机的时序匹配框架,核心思想是:将复杂场景分解为一系列有序的状态转移,通过逻辑表达式描述每个状态的进入条件,通过状态转移图控制整个匹配流程。
3.1 生活中的类比
想象一下你在咖啡店点咖啡的过程:
状态 0:进入咖啡店,等待排队
状态 1:轮到你,开始点单
状态 2:支付完成,等待制作
状态 3:拿到咖啡,离开咖啡店
每个状态都有明确的进入条件,状态之间有明确的转移规则。如果在状态 2 时发现喜欢的咖啡卖完了,你可能会直接转移到 "离开" 状态,这就是提前转移。
3.2 核心概念定义
# 核心数据结构抽象StateMap = Dict[str, Any] # 状态映射表EventInfo = Dict[str, Any] # 事件信息classStateMachine:def__init__(self): self.state_seq = [] # 状态序列:["条件1", "条件2", "条件3"] self.state_edge_map = {} # 状态转移图:{当前状态: [下一状态列表]} self.pre_jump_state_edge_map = {} # 提前转移图 self.state_limit_size_map = {} # 状态最大时长限制 self.match_path = [] # 当前匹配路径3.3 输入数据处理流程
defprocess_input_data(input_data):""" 输入数据处理流程 input_data: 可以是SQL表、DataFrame或其他时序数据结构 """# 1. 数据标准化:统一时间格式、字段命名 standardized_data = standardize_data(input_data)# 2. 特征工程:计算衍生特征 feature_data = compute_features(standardized_data)# 3. 数据关联:关联多表数据(如自车+他车+道路设施) merged_data = join_multiple_tables(feature_data)# 4. 数据清洗:过滤异常值、缺失值 cleaned_data = clean_data(merged_data)return cleaned_datadefcompute_features(data):"""特征工程示例""" features = {}# 自车特征 features['speed'] = data['vehicle_speed'] features['acceleration'] = compute_acceleration(data['vehicle_speed']) features['lane_position'] = data['lane_position'] features['is_lane_changing'] = data['lane_change_status']# 他车特征 features['front_car_distance'] = data['front_vehicle_distance'] features['front_car_speed'] = data['front_vehicle_speed'] features['left_car_exist'] = data['left_vehicle_exist']# 道路设施特征 features['distance_to_traffic_light'] = data['traffic_light_distance'] features['distance_to_destination'] = data['destination_distance']# 复合特征 features['is_slow_to_stop'] = (features['speed'] < 0.5) features['is_far_from_destination'] = (features['distance_to_destination'] > 300)return features四、状态匹配机制的核心实现
4.1 状态机核心算法
defmatch_state_sequence(data, state_machine):""" 状态序列匹配核心算法 """ matched_events = []for timestamp, features in data.iterrows():# 1. 检查当前状态是否匹配 current_state = state_machine.current_state is_match = evaluate_condition(state_machine.state_seq[current_state], features)if is_match:# 2. 记录匹配的状态 state_machine.match_path.append((current_state, timestamp))# 3. 检查是否触发提前转移if current_state in state_machine.pre_jump_state_edge_map:for next_state in state_machine.pre_jump_state_edge_map[current_state]:if evaluate_condition(state_machine.state_seq[next_state], features): state_machine.current_state = next_statebreak# 4. 检查状态时长限制if current_state in state_machine.state_limit_size_map: state_duration = calculate_state_duration(state_machine.match_path, current_state)if state_duration > state_machine.state_limit_size_map[current_state]: handle_state_timeout(state_machine)else:# 5. 处理状态不匹配的情况if handle_state_transition(state_machine, features):# 成功转移到下一个状态continueelse:# 状态序列中断,检查是否完成完整匹配if is_complete_match(state_machine): event = extract_event_info(state_machine.match_path, features) matched_events.append(event)# 重置状态机 reset_state_machine(state_machine)return matched_eventsdefevaluate_condition(condition_expression, features):""" 条件表达式评估 支持逻辑运算符:&(与)、|(或)、!(非) 例如:"is_far_from_destination & !is_lane_changing" """# 将表达式中的特征名替换为实际值for feature_name, feature_value in features.items(): condition_expression = condition_expression.replace(feature_name, str(feature_value))# 安全评估表达式try:return eval(condition_expression)except Exception as e: logging.error(f"条件表达式评估错误: {e}")returnFalse4.2 灵活的特征预处理机制
classFeatureProcessor:def__init__(self, config): self.config = config self.feature_functions = {}# 注册特征计算函数 self.register_feature_function('speed_smooth', self.calculate_smooth_speed) self.register_feature_function('lane_change_detector', self.detect_lane_change) self.register_feature_function('obstacle_distance', self.calculate_obstacle_distance)defprocess(self, raw_data):""" 灵活的特征预处理流程 """ processed_data = raw_data.copy()# 根据配置计算需要的特征for feature_name, feature_config in self.config['features'].items():if feature_name in self.feature_functions: processed_data[feature_name] = self.feature_functions[feature_name]( processed_data, **feature_config['params'] )return processed_datadefregister_feature_function(self, name, func):"""注册自定义特征计算函数""" self.feature_functions[name] = func五、具体样例:异常右变道至最右车道停车场景
让我们通过一个具体的例子来看看这套机制是如何工作的。
5.1 场景定义
假设我们要挖掘 "异常右变道至最右车道停车" 场景,这个场景的特点是:
车辆在没有合理理由的情况下(离终点还很远,没有红绿灯)
向右变道到最右车道
然后减速停车
这种行为可能表明驾驶员有异常操作,需要重点关注。
5.2 状态机设计
# 异常右变道至最右车道停车场景的状态机定义abnormal_lane_change_machine = StateMachine()# 状态序列定义abnormal_lane_change_machine.state_seq = [# 状态0:基础约束(无合理变道动机)"is_far_from_destination & no_traffic_light_ahead & no_left_low_speed_car",# 状态1:开始右变道并进入最右车道"is_lane_changing_to_right & at_rightmost_lane",# 状态2:完成变道后保持车道"!is_lane_changing",# 状态3:减速至停车"is_slow_to_stop"]# 状态转移规则abnormal_lane_change_machine.state_edge_map = {0: [1], # 基础约束满足 → 开始右变道1: [2], # 完成变道 → 保持车道2: [3] # 保持车道 → 减速停车}# 状态时长限制(单位:秒)abnormal_lane_change_machine.state_limit_size_map = {0: 10, # 基础约束阶段最多10秒2: 100# 保持车道阶段最多100秒}5.3 实际匹配过程
让我们看看在实际数据中这个状态机是如何工作的:
初始状态:状态机处于状态 0,等待匹配基础约束条件
匹配状态 0:当车辆离终点超过 300 米,前方没有红绿灯,左侧没有低速车时,进入状态 0
转移到状态 1:当车辆开始向右变道并进入最右车道时,从状态 0 转移到状态 1
转移到状态 2:当车辆完成变道并保持在最右车道时,从状态 1 转移到状态 2
转移到状态 3:当车辆减速至停车时,从状态 2 转移到状态 3
完成匹配:当状态 3 匹配完成后,整个场景匹配成功,记录事件信息
5.4 匹配后处理与事件加工
defprocess_matched_events(matched_events, raw_data):""" 匹配后处理与事件加工 """ processed_events = []for event in matched_events:# 1. 事件时长过滤 event_duration = calculate_event_duration(event)if event_duration < 5: # 过滤短于5秒的事件continue# 2. 提取关键时间点信息 key_points = extract_key_timestamps(event.match_path)# 3. 加工事件信息 processed_event = {'event_id': generate_unique_id(),'event_name': 'abnormal_right_lane_change_to_stop','start_time': event.start_time,'end_time': event.end_time,'duration': event_duration,'key_timestamps': {'start_change': key_points[1], # 开始变道时间点'end_change': key_points[2], # 完成变道时间点'stop_time': key_points[3] # 停车时间点 },'context_info': {'distance_to_destination': get_context_value(event.start_time, 'distance_to_destination'),'traffic_light_status': get_context_value(event.start_time, 'traffic_light_status') } } processed_events.append(processed_event)return processed_events六、技术创新点与优势
6.1 声明式的场景定义
用户只需关注核心的时序逻辑,将场景表示为基本特征量的时序关系,无需关心底层实现细节。这种声明式的方式使得场景逻辑的表达更加清晰直观。
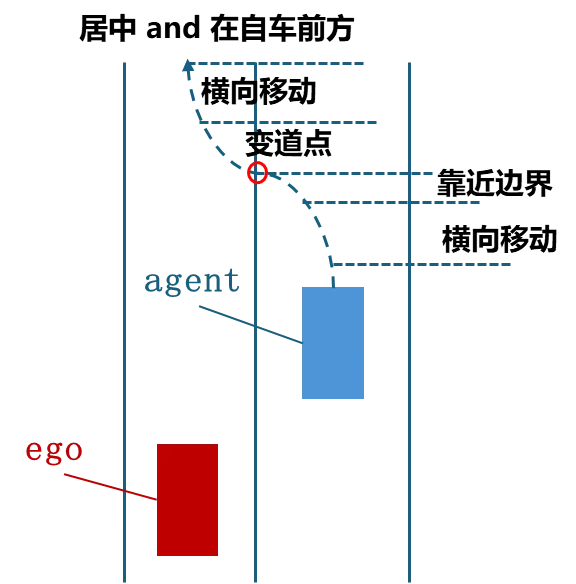
# 示例:他车变道切入场景的状态定义cut_in_scene = ["centered_in_lane", # 他车居中行驶"approaching_lane_boundary", # 接近车道边界"crossing_lane_boundary", # 跨越车道边界"moving_away_from_boundary", # 远离车道边界"centered_in_front_lane"# 重新居中在自车前方]这种方式的好处是:
易于理解:场景逻辑一目了然,非技术人员也能理解
易于修改:只需修改状态条件,无需修改核心算法
易于扩展:可以轻松添加新的状态和转移规则
6.2 灵活的状态转移控制
通过状态转移图和提前转移图的设计,支持复杂的分支逻辑和状态跳转,能够处理实际场景中的各种复杂情况。
# 支持分支的状态转移图示例complex_scene_edge_map = {0: [1, 2], # 状态0可以转移到状态1或状态21: [3], # 状态1只能转移到状态32: [3], # 状态2只能转移到状态33: [4, 5], # 状态3可以转移到状态4或状态54: [6], # 状态4转移到状态65: [6], # 状态5转移到状态66: [] # 状态6是最终状态}6.3 强大的时间约束能力
通过给状态设置时间限制,能够处理一些模糊的过渡状态,例如徘徊变道这种很难精准匹配的场景。
# 处理徘徊变道的状态定义wandering_lane_change = ["centered_in_lane", # 初始居中状态"True", # 过渡状态(始终为True)"centered_in_another_lane"# 最终居中状态]# 限制过渡状态最多持续10秒state_limit_size_map = {1: 10# 过渡状态最多10秒}6.4 可扩展的 DSL 设计
这套机制可以作为领域特定语言(DSL),后续可以:
编译为 Python UDF,在 ODPS 表上进行分布式计算
翻译为 SQL 语句,在数据仓库中进行高效检索
转换为其他编程语言实现,适应不同的运行环境
-- 示例:将状态匹配逻辑转换为SQL查询WITH state_matching AS (SELECTtimestamp, features,-- 状态0匹配CASEWHEN distance_to_destination > 300AND traffic_light_distance > 100THEN1ELSE0ENDAS state0_match,-- 状态1匹配CASEWHEN is_lane_changing = 1AND lane_position = 'rightmost'THEN1ELSE0ENDAS state1_match,-- 状态2匹配CASEWHEN is_lane_changing = 0THEN1ELSE0ENDAS state2_match,-- 状态3匹配CASEWHEN speed < 0.5THEN1ELSE0ENDAS state3_matchFROM driving_data)SELECT * FROM state_matching-- 匹配完整的状态序列WHERE state0_match = 1ANDLEAD(state1_match, 1) OVER (ORDERBYtimestamp) = 1ANDLEAD(state2_match, 2) OVER (ORDERBYtimestamp) = 1ANDLEAD(state3_match, 3) OVER (ORDERBYtimestamp) = 1;七、工程实践中的优化与思考
7.1 性能优化策略
增量计算:只处理新增的数据,避免重复计算
并行处理:将大的时间窗口拆分为小窗口并行处理
索引优化:为时间字段和关键特征字段建立索引
缓存机制:缓存常用的特征计算结果
7.2 可观测性设计
classStateMachineMonitor:def__init__(self): self.metrics = {'total_events_processed': 0,'total_matches_found': 0,'average_match_duration': 0,'state_transition_counts': defaultdict(int),'condition_evaluation_times': [] }defrecord_match(self, event):"""记录匹配事件""" self.metrics['total_matches_found'] += 1 self.metrics['average_match_duration'] = ( self.metrics['average_match_duration'] * (self.metrics['total_matches_found'] - 1) + event.duration ) / self.metrics['total_matches_found']defrecord_state_transition(self, from_state, to_state):"""记录状态转移""" self.metrics['state_transition_counts'][(from_state, to_state)] += 17.3 容错与鲁棒性设计
defhandle_data_gaps(data, max_gap_duration=1):"""处理数据间隙""" gaps = identify_data_gaps(data)for gap in gaps:if gap.duration <= max_gap_duration:# 小间隙:插值填充 data = fill_gap_with_interpolation(data, gap)else:# 大间隙:分割数据 data_segments = split_data_at_gap(data, gap)return datadefvalidate_state_sequence(sequence):"""验证状态序列的合法性"""ifnot sequence:returnFalse# 检查状态序列是否有循环依赖 visited = set()for state, transitions in sequence.state_edge_map.items():if state in visited:continue path = []if has_cycle(state, sequence.state_edge_map, visited, path): logging.warning(f"状态序列存在循环依赖: {path}")returnFalsereturnTrue八、总结与展望
这套时序状态匹配机制通过将复杂场景分解为有序的状态转移序列,结合灵活的特征预处理和强大的后处理能力,为自动驾驶场景挖掘提供了一种高效、可扩展的解决方案。相对而言,目前虽然有较为成熟的商业化方案(例如自动化场景挖掘与筛选:高效评估自动驾驶系统的安全与性能))在形式匹配上有更多与场景相关的更复杂的逻辑实现,然而实际面临的问题常与数据深耦合,对于数据管理、数据特征的预处理以及后处理,缺少成熟统一的方案和范式,许多场景需要根据实际业务中的需求,数据特性来做特异化地处理,当前使用的这套机制尽可能考虑了数据处理的灵活性。
8.1 核心优势
声明式编程:用户只需关注场景的逻辑描述,无需关心底层实现
高度灵活:支持复杂的分支逻辑和状态跳转
可扩展性强:可以轻松添加新的状态和转移规则
性能高效:基于状态机的匹配算法时间复杂度为 O (n)
易于维护:模块化的设计使得代码易于理解和维护
8.2 未来发展方向
自动化特征工程:结合机器学习自动生成最优的特征组合
自适应状态机:根据数据分布自动调整状态转移规则
可视化配置界面:提供拖拽式的场景配置界面,降低使用门槛
实时匹配能力:优化算法以支持实时数据流的在线匹配
跨平台部署:支持在不同的计算平台上运行,包括云原生环境
By:世界五百强车企自动驾驶数据挖掘团队,致力于通过工程手段让dirty的work变得不dirty,with efficiency!

