730 万条驾驶交互数据!同济打造自动驾驶 VLA 模型专属增强数据集,破解复杂路况推理难题
- 2026-02-28 01:14:23
点击上方蓝字加入我们

论文链接:https://arxiv.org/pdf/2602.20575
代码链接:https://github.com/egik-von/IEDD
开车上路时,你是否遇见过这样的场景:路口和其他车辆小心翼翼的会车、拥堵路段被加塞、人行道前紧急避让行人……这些日常的驾驶交互,对人类司机来说是熟能生巧的判断,却是自动驾驶迈向全自动化的一大难关。当自动驾驶车辆面对这些复杂的交互场景,往往会出现感知不准、决策失误的问题,甚至事故风险远超人类驾驶。
同济大学汽车学院团队针对这一行业痛点,提出了交互式增强驾驶数据集(IEDD),构建了百万级的异质交互驾驶样本,设计了物理感知的多模态对齐生成流水线,并建立了分层评估基准,为自动驾驶视觉-语言-动作(VLA)模型的推理能力提升提供了全新解决方案。相关研究成果也为自动驾驶VLA模型的域适配提供了实证依据,填补了现有数据在交互场景稀疏、多模态对齐不足的空白。
一、引言:自动驾驶的交互困境,现有数据成最大瓶颈
自动驾驶技术的发展,正从基础的驾驶辅助向全自动化迈进,而车辆在复杂动态环境中与行人、非机动车、其他车辆的交互能力,成为决定其安全性和效率的核心。但现实是,自动驾驶系统在变道、路口会车、斑马线避让等交互场景中,表现远不如人类:有研究数据显示,自动驾驶系统在涉及复杂协商的转弯场景中,事故风险是人类驾驶的1.98倍;在黎明、黄昏等感知要求高的光照条件下,这一差距更是扩大到5.25倍。
如今自动驾驶研究已转向VLA范式,核心是通过视觉语言模型(VLM)融合视觉感知与语义逻辑推理,实现类人化的场景理解。但这一范式的发展,却被数据问题牢牢束缚,两大核心痛点尤为突出:
高价值交互场景稀疏:现有自然驾驶数据集(如NGSIM、nuScenes、Waymo)多捕捉常规非交互行为,路口会车、强制并线等关键交互事件属于长尾分布,从海量数据中提取难度极大; 多模态数据缺失且对齐不足:多数数据集仅包含视觉或轨迹单模态信息,缺乏驾驶意图描述、场景上下文等语言标注,无法支撑VLM学习符合人类认知的综合交互表征,同时视觉、语言、动作的模态对齐性差,逻辑一致性不足。
此外,多模态驾驶数据的采集和人工标注耗时耗力、成本极高,从零构建新数据集并不现实。为此,同济团队提出了基于现有公开轨迹数据集,提取以自车为中心的交互场景、设计量化指标、合成视觉语义补充数据的全新框架,打造了IEDD数据集,从根本上解决上述痛点。
二、创新方法详解:三大核心模块,打造高质量交互驾驶数据集
团队设计了一套可扩展的数据集生产流水线,整体流程如图1所示,包含交互挖掘、交互量化、多模态合成三大紧密耦合的核心模块,最终实现从原始轨迹数据到多模态IEDD数据集的转化,同时构建了IEDD-VQA视觉问答子集,完成视觉与语言的严格时空对齐。
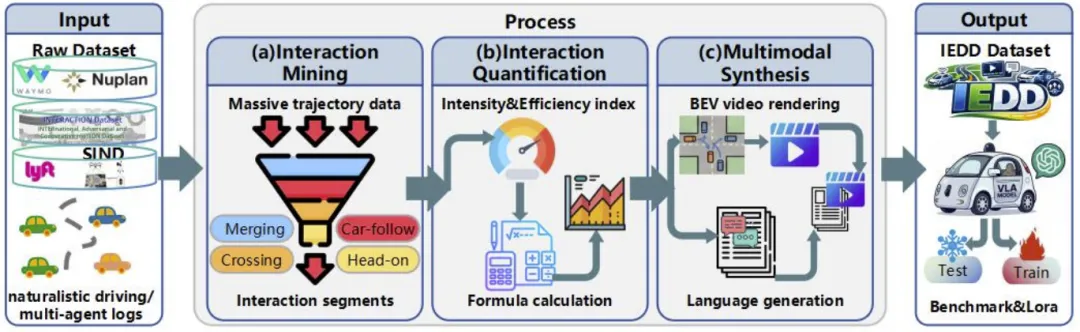
图 1. 生成 IEDD 数据的整个流程概览。
(一)自然驾驶轨迹预处理与场景切片:精准提取四类核心交互片段
这一模块的核心是从异质自然驾驶数据中,自动提取并分类以自车为中心的交互事件,分为四个级联步骤,最终输出包含精准时间窗口和语义类型的交互事件集:
轨迹清洗与标准化 :将所有车辆轨迹重采样至0.1s的时间分辨率,去除无效零点数据;通过有限差分法计算初始航向角,对航向角序列平滑处理,保证车辆运动学信息的连续性;
时空交点检测 :定义空间距离阈值和时间差阈值,采用基于时间轴的双指针滑动窗口机制,检索轨迹的潜在时空交点,避免穷举对比的计算冗余;
两车交互分类 :先判断跟车行为(轨迹重叠点多、航向差低于阈值),非跟车行为则根据两车接近交点时的相对航向角,分为并线、横穿、对向行驶三类, 图2 展示了典型交互场景的几何分类特征,同时为并线、横穿场景设定航向角阈值、提取冲突区域;
多智能体聚合 :将同一场景中参与多种交互的车辆作为锚点,递归合并所有关联交通参与者形成多智能体组,以所有交互事件时间区间的并集为有效时间窗口,保证复杂场景的时空和语义完整性。
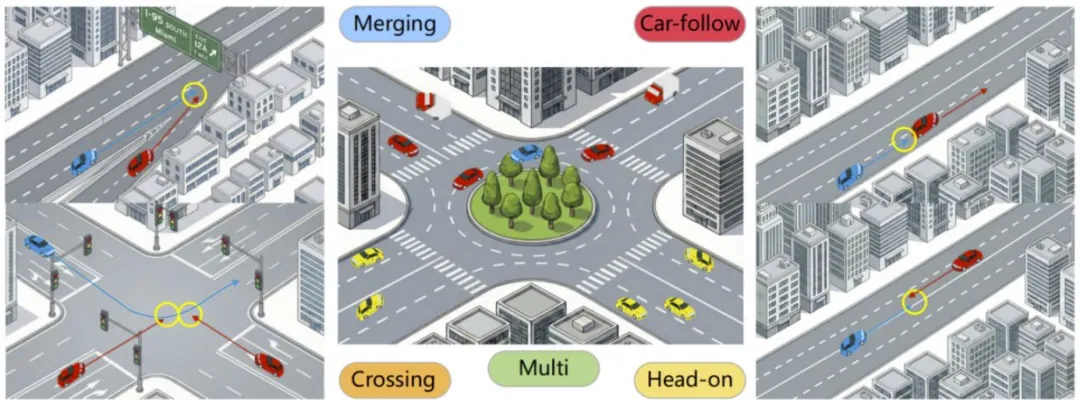
图 2. 典型交互场景的几何分类示意图。
(二)基于强度-效率的交互度量体系:量化交互过程的风险与质量
团队将车车交互建模为连续时间序列过程,从交互强度(过程风险)和交互效率(决策质量)双维度,建立了基于随机过程的定量评估体系,为每个交互片段赋予物理属性标签,核心参数如表1所示。
表 1 交互挖掘与量化关键参数汇总
1. 交互状态空间建模
将交互场景建模为随机过程,对于场景中n个交通参与者,第i个参与者在t时刻的状态向量为,整体状态空间为:
其中为平面坐标,、、分别为航向角、速度、加速度。当两车同时满足交互触发的空间距离阈值和时间差阈值时,判定为交互状态。
2. 动态交互强度评估指标
交互强度指标 量化车辆在交互过程中面临的瞬时冲突压力和响应操作强度,由姿态调整、风险梯度、环境势能三个物理分量加权耦合而成:
其中为归一化权重系数,团队采用 类别自适应权重分配策略:并线场景侧重环境势能、横穿场景侧重风险梯度、对向行驶场景风险梯度占主导,精准捕捉不同交互模式的核心风险特征。姿态调整指标 :通过速度变化率和加速度的归一化值,量化车辆为缓解冲突的运动学响应幅度; 风险变化指标 :引入碰撞时间TTC和侵入后时间(PET)时间导数,表征风险逼近的紧迫性,捕捉“风险急剧升级”的关键时刻; 交互势能场指标:基于人工势能场(APF)方法构建动态风险分布,对自车前方区域赋予更高权重,符合人类司机的感知特征。
3. 综合交互效率评估指标
交互效率指标 从路径、时间、平顺性三个独立维度评估交互遍历质量,取值范围[0,1],为结果导向的评价维度,公式为:
路径一致性 :量化实际轨迹与参考路径的几何对齐度,为起止点欧氏距离与实际轨迹长度的比值; 时间一致性 :基于期望速度评估延迟惩罚,交互导致的速度损失越小,得分越高; 驾驶平顺性 :通过交互窗口内的加速度标准差评估乘客舒适性,加减速波动越剧烈,得分呈指数衰减。
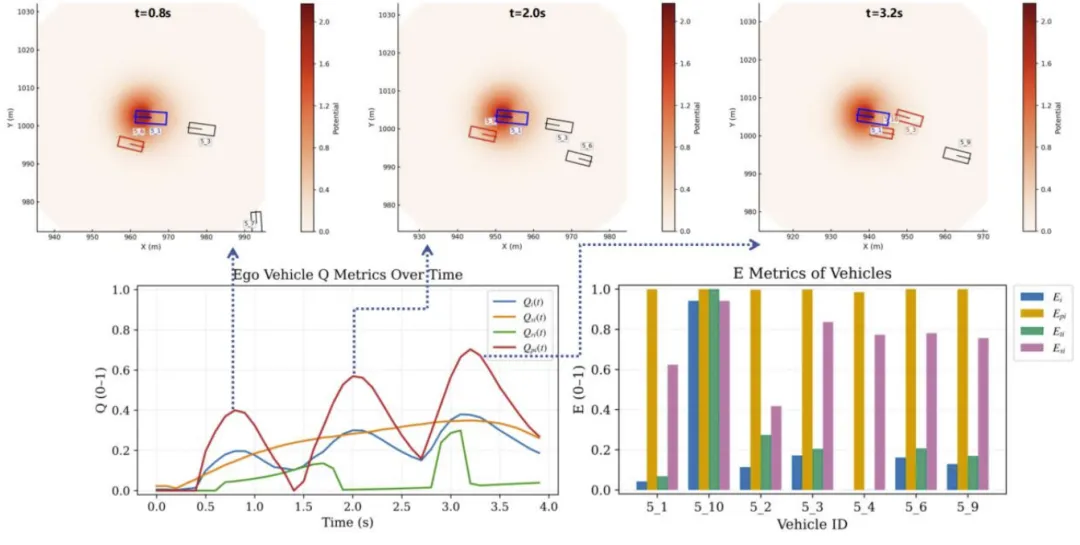
图3为动态交互指标的时空可视化结果,直观展现了交互强度随两车时空距离的变化,以及不同车辆交互后的遍历效率差异。
(三)多模态交互指令数据生成:实现视觉-语言的严格时空对齐
以提取的交互片段和量化指标为输入,构建视觉特征、结构化语义、自然语言描述高度耦合的三元组样本,打造IEDD-VQA数据集,核心分为三步:
1. 结构化语义表示与行为序列化
将连续轨迹数据抽象为符号语义单元,搭建物理世界与语言空间的桥梁:
行为原子识别与时间压缩:将车辆连续状态空间离散为“行为原子”,合并连续同质原子为紧凑的“行为链”,记录动作时间窗口; 交互关系建模与阶段划分:以交互强度峰值为时间锚点,将交互过程分为“接近、交互、结果”三个阶段,提取相对方位、路权、交互类型,赋予数据因果逻辑; 可解释元数据封装:将参与者角色标签、量化交互强度等级封装为元数据,约束后续语言描述贴合物理真实。
2. 规则驱动的语言监督生成机制
消除大模型生成的“幻觉”问题,基于预定义语义槽和逻辑模板构建语言标注,生成三类互补文本格式:全局总结、标准化动作链、多轮问答指令,且问答答案均从结构化语义中严格提取,保证事实准确性;同时将连续的交互强度指标映射为离散语言修饰词,提取峰值强度附近的微行为变化转化为文本描述,提升可解释性。
3. 轨迹驱动的BEV渲染与时空对齐
选择鸟瞰图(BEV)作为核心视觉模态,克服第一视角的视野限制和遮挡问题,同时摆脱对特定硬件的依赖,实现管线的通用性:
自车中心标准化渲染:将所有轨迹转换为统一的BEV坐标系,原点设为自车在交互强度峰值时刻的位姿,动态车辆渲染为定向几何图形,叠加短期历史轨迹提供运动线索; 严格时空同步:建立统一时间基线,保证BEV视频帧与轨迹采样时间严格对应,语言描述中提及的关键时刻和行为区间与视频帧索引像素级对齐,实现视觉、物理运动、语言逻辑的有效映射。
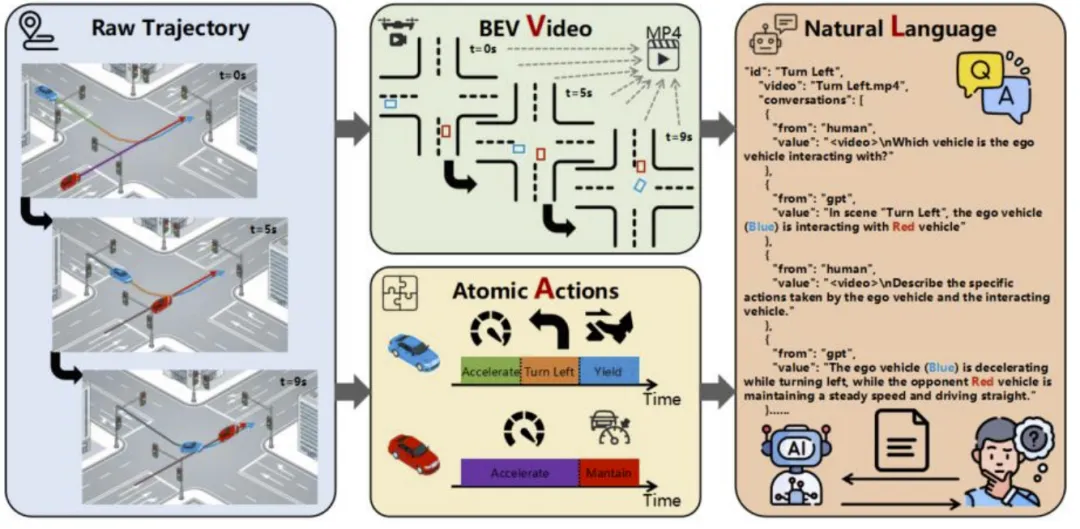
图4为轨迹驱动的多模态数据合成工作流,展示了从原始轨迹到原子动作,再到BEV视频和自然语言问答对的转化过程,同时给出了生成的JSON数据示例。
(四)IEDD数据集构成:730万条样本,覆盖多类型交互场景
IEDD数据集包含基于轨迹的大规模交互片段数据集(IEDD)和VLA模型指令调优数据集(IEDD-VQA)两部分,核心统计特征如下:
规模与交互类型:如表2、图5所示,IEDD共提取7313985条以自车为中心的交互场景,规模远超Lyft、Waymo等主流数据集; 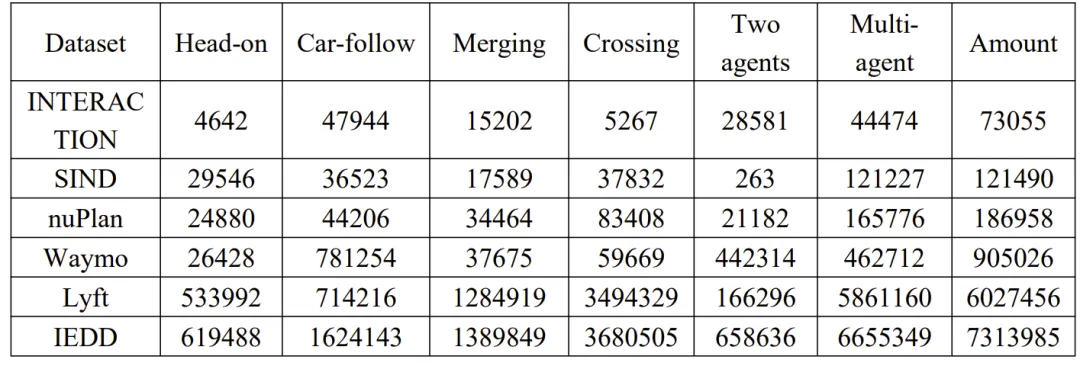
表 2.IEDD 与原始数据集之间交互类型及规模的统计比较
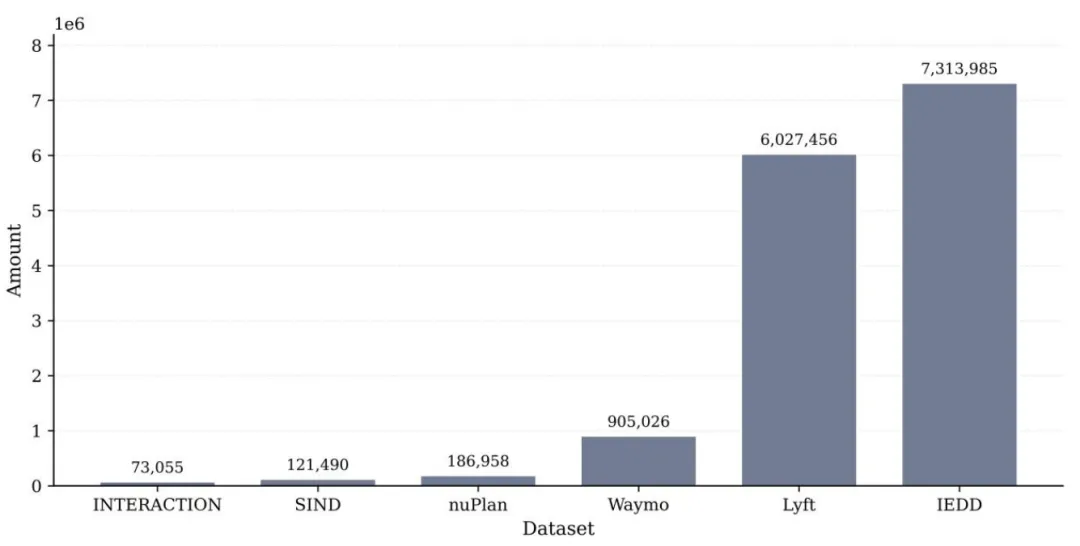
图 5. 各数据集间总交互段落的比较
图6显示,数据集打破了现有数据以跟车行为为主的格局,横穿、对向行驶等长尾高风险场景分布更均衡;
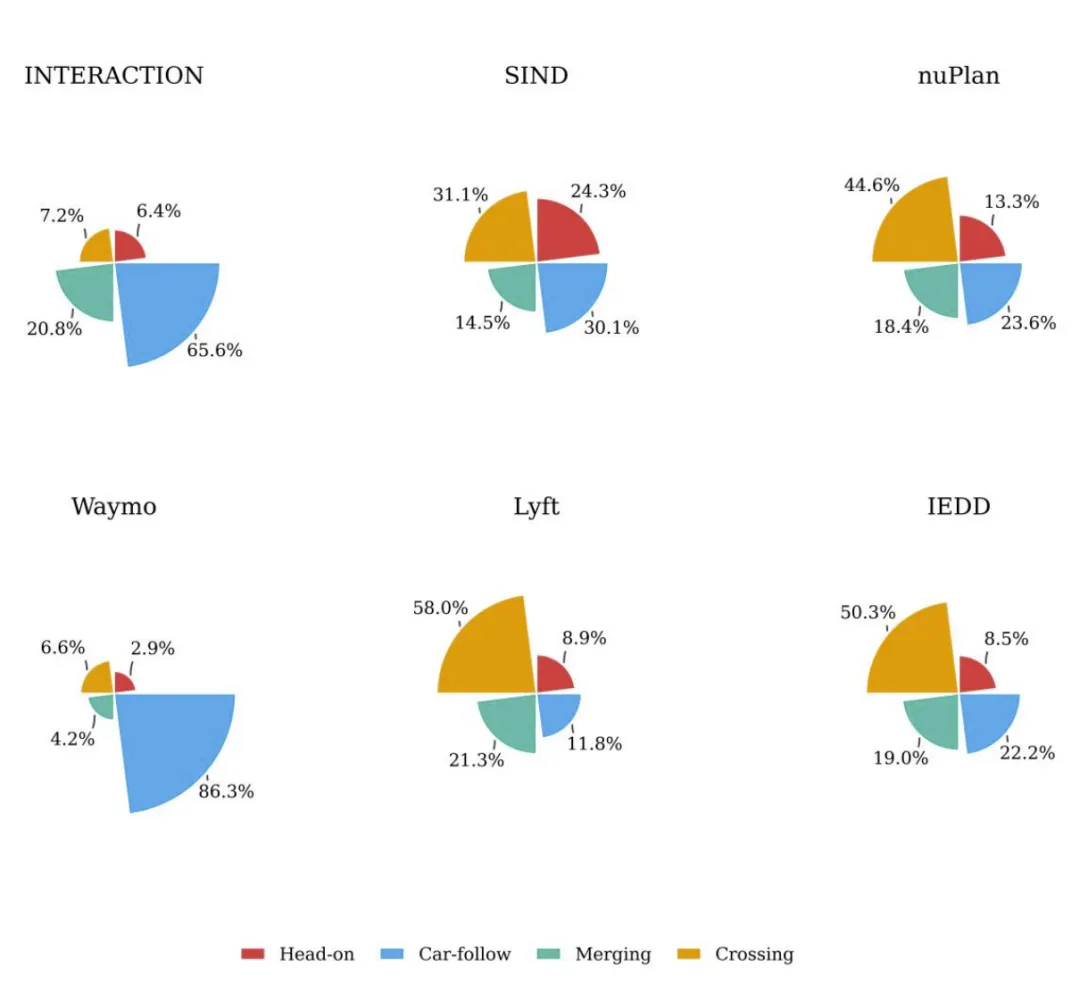
图 6. IEDD 中交互类型分布的饼状图对比。
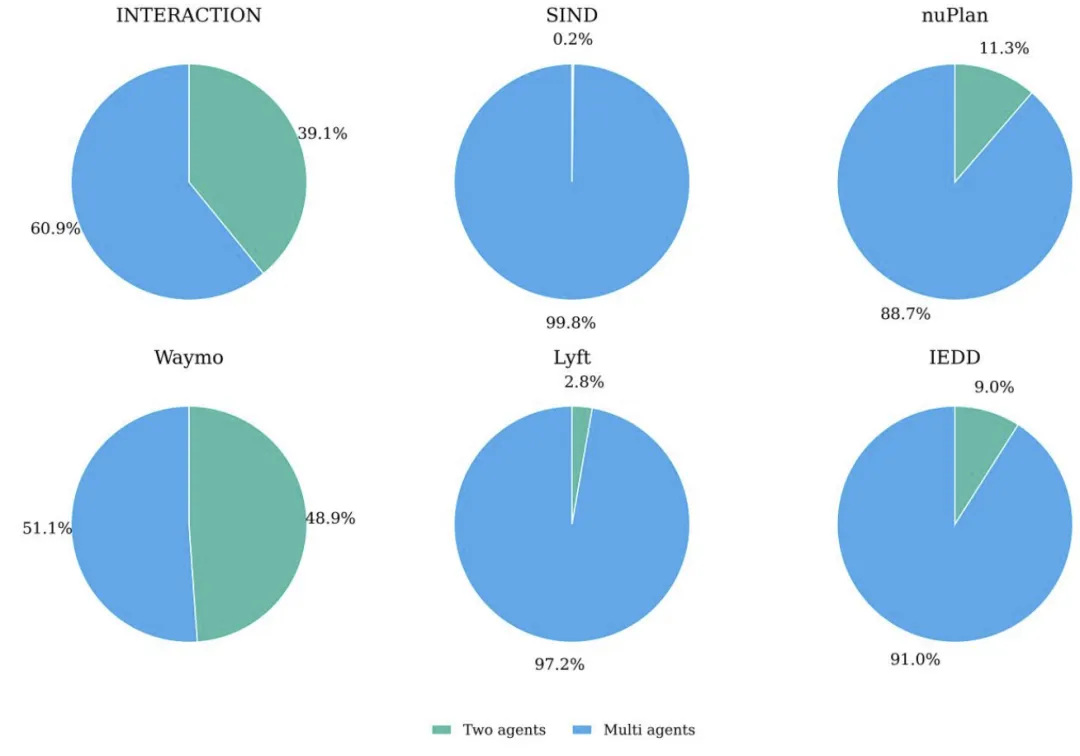
图 7. 在 IEDD 中两车和多车交互场景的成比例对比。
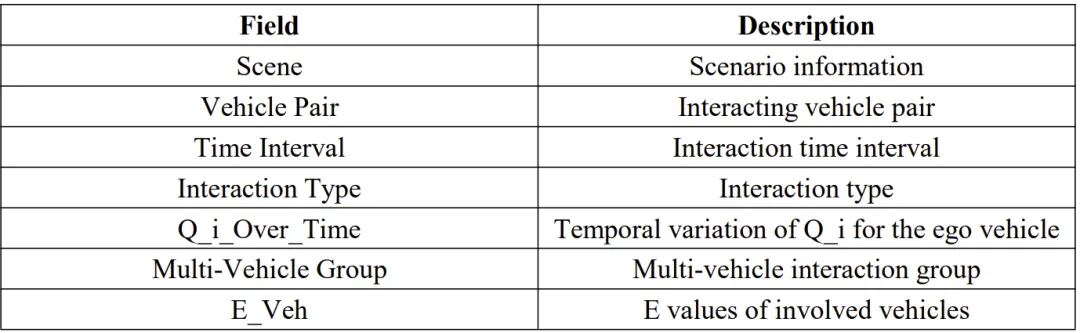
表 3. IEDD 数据集的字段定义
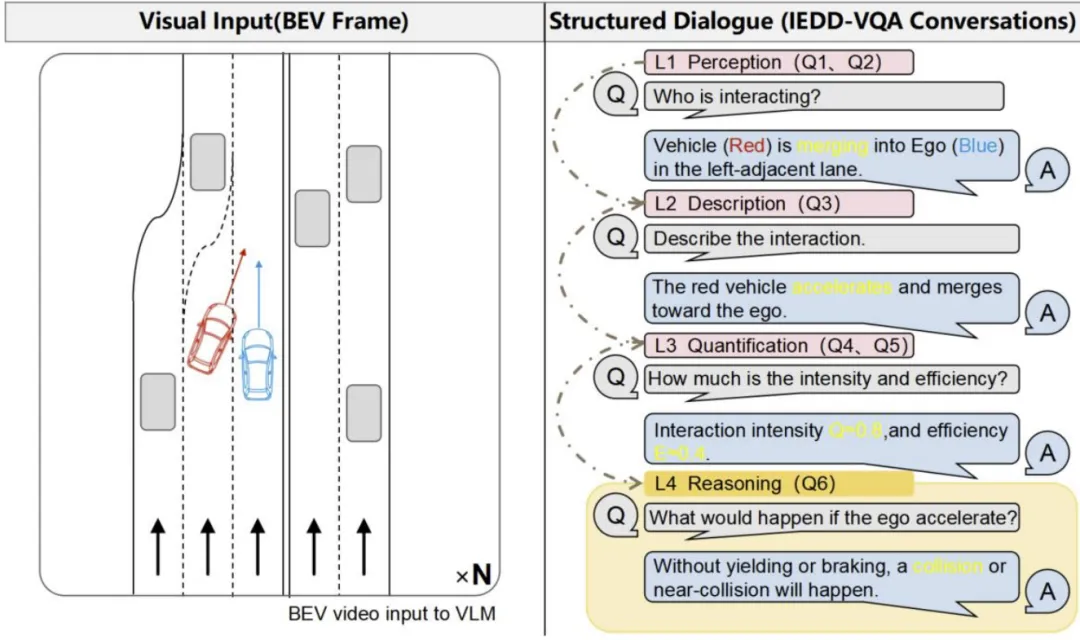
图 8. IEDD-VQA 数据集的任务定义及内容示例。
三、实验效果验证:十款主流VLM测评,IEDD大幅提升模型推理能力
为验证IEDD数据集的有效性,团队建立了分层、多维度的评估框架,对十款主流VLM模型进行了零样本评估、CoT策略激活实验和域适配微调实验,全面检验模型在自动驾驶交互领域的感知、描述、量化、推理能力。
(一)实验设计:标准化输入与分层评估指标
输入表示与预处理:基于IEDD-VQA测试集构建100个典型交互场景的评估集,对每个交互片段均匀提取6个关键帧覆盖交互全过程,图像统一resize为512×512并Base64编码,6帧序列作为视觉上下文仅在多轮对话初始输入; 分层评估指标体系:分为L1-L4四层,引入GLM-4.7作为评估器对内容的物理合理性和安全性打分,最终通过加权综合得分(WIS)衡量模型综合能力,权重向安全关键的推理层倾斜(L4占40%),公式为: L1(感知识别):采用目标ID交并比(Obj_IoU)、交互准确率(Int_Acc)评估; L2(行为描述):采用LLM动作语义得分(Act_Sem)、ROUGE-L作为辅助指标; L3(物理量化):采用平均绝对误差(MAE)评估数值估计精度,逻辑一致性(Log_Acc)验证物理量关系判断能力; L4(反事实推理):采用推理质量得分(Reas_Score)、ROUGE-L作为辅助指标。
(二)零样本性能评估:开源模型表现亮眼,量化能力成共同瓶颈
对十款主流VLM(含3款开源模型:Llama-4-Maverick、Qwen2.5-VL-7B、GLM-4.6V)进行零样本测评,结果如表4、图9所示:
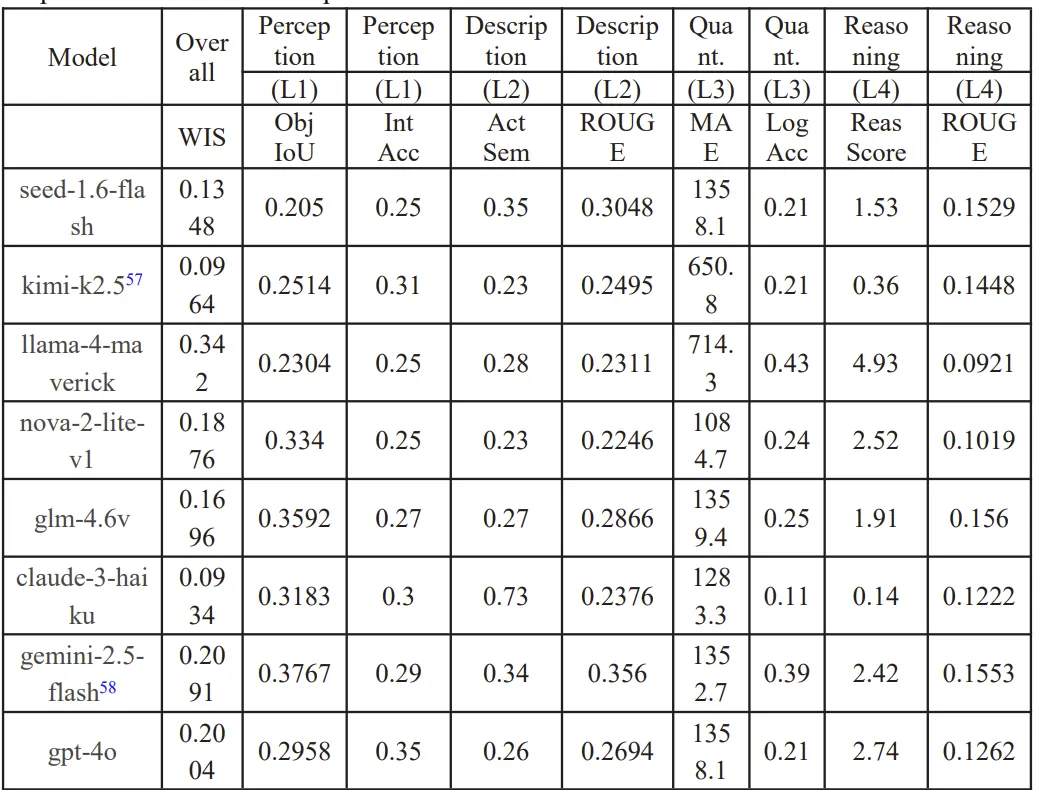

表 4.十种主流视觉语言模型在 IEDD-VQA 上的零样本评估结果
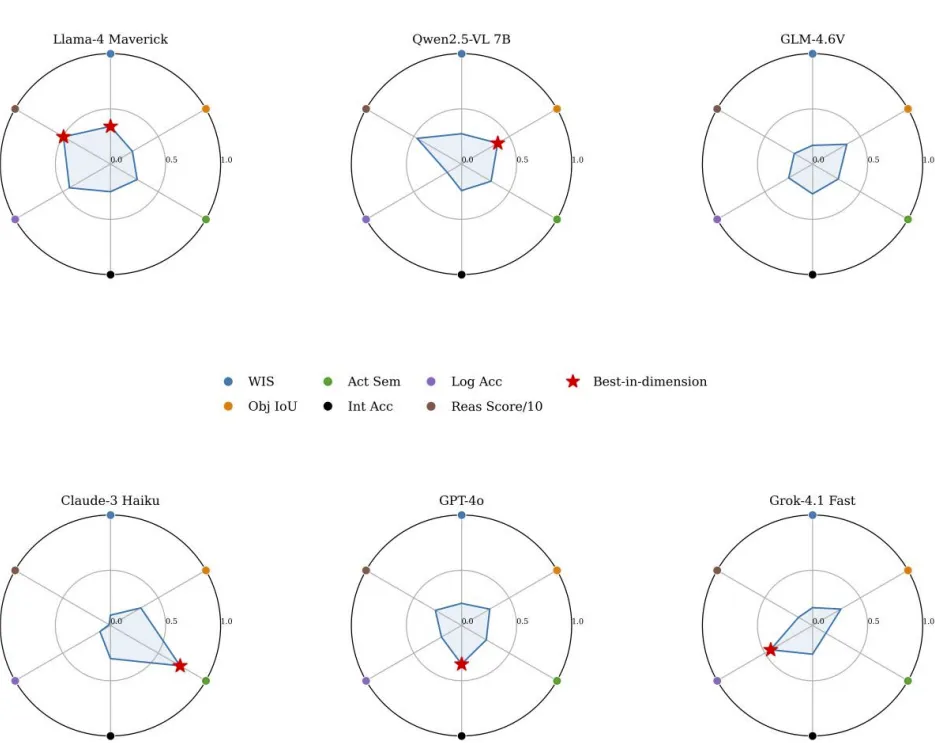
图 9. 对选定模型在六个能力维度上的零样本性能进行的雷达图比较。
开源模型实现“逆袭”:Llama-4-Maverick以WIS=0.342位居第一,Qwen2.5-VL-7B(WIS=0.275)次之,优于GPT-4o、Claude-3-Haiku等闭源旗舰模型,表明优化后的开源模型在自动驾驶交互垂直领域具备比肩甚至超越顶级闭源模型的潜力; 所有模型存在共同瓶颈:L3物理量化维度的MAE值极高(如Qwen2.5-VL-7B为1855.5,GPT-4o为1358.1),说明通用VLM虽具备较强的语义理解能力,但无法从BEV视频中精准提取物理指标,视觉特征与物理数值的映射能力严重不足。
(三)CoT策略实验:激活逻辑推理能力,部分模型量化误差骤降
引入思维链(CoT)提示策略后重新评估模型,结果如表5、图10、图11所示:

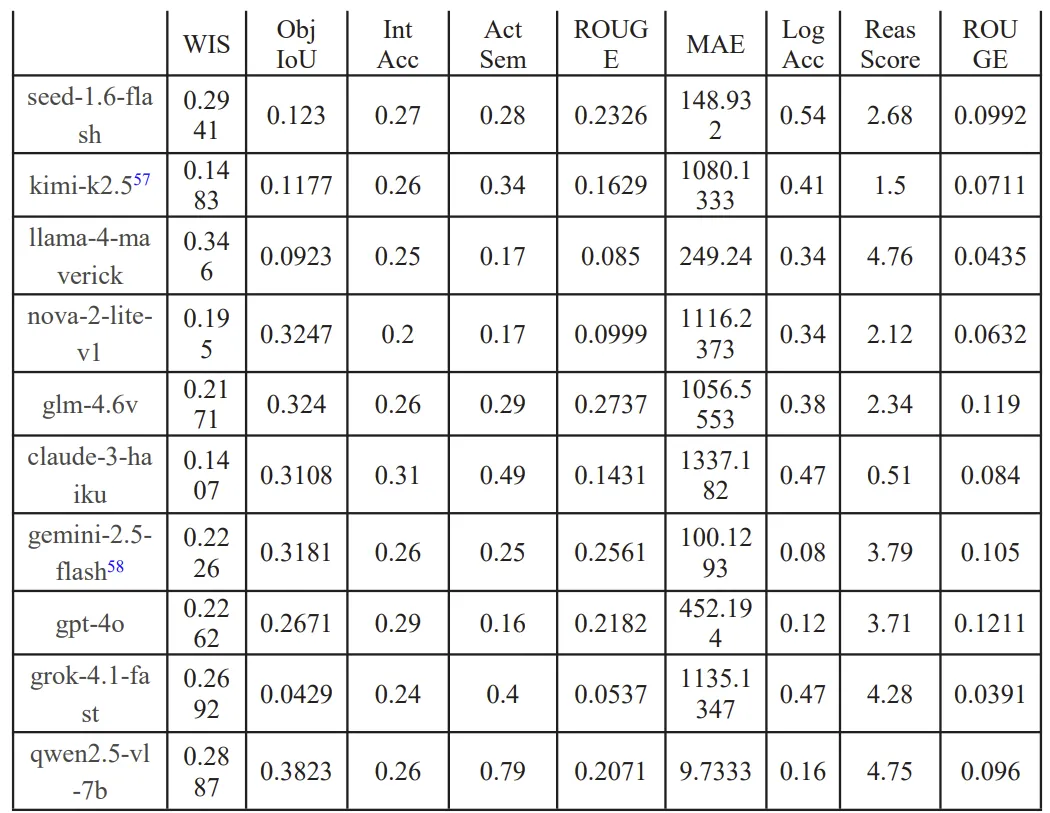
表 5. 引入 CoT 策略后的模型性能评估结果
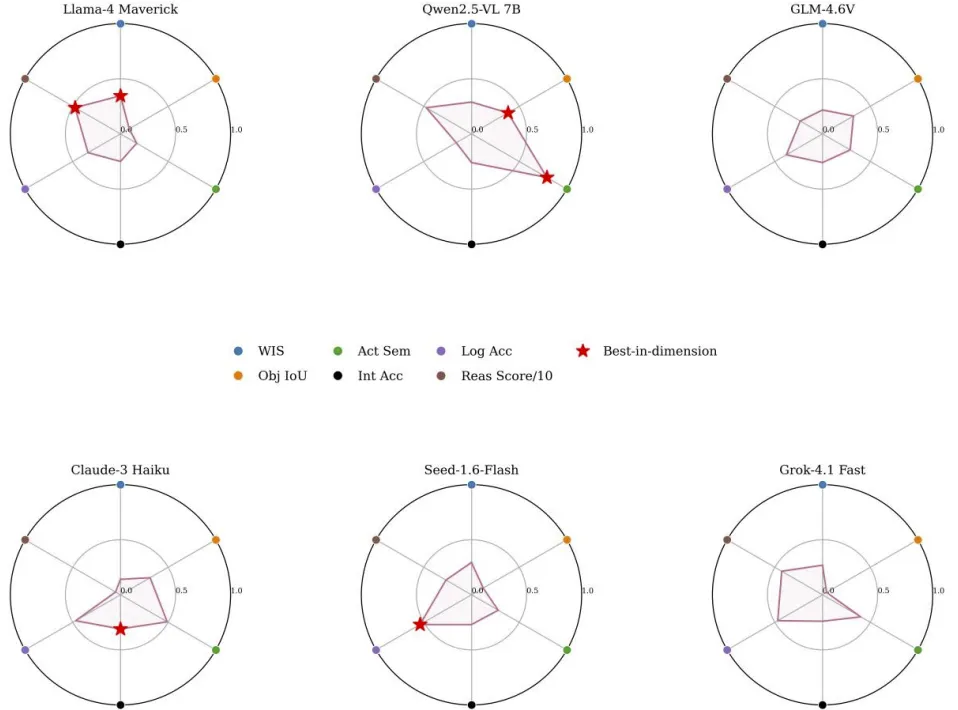
图 10. 在“成本驱动”策略下选定模型的性能雷达图。
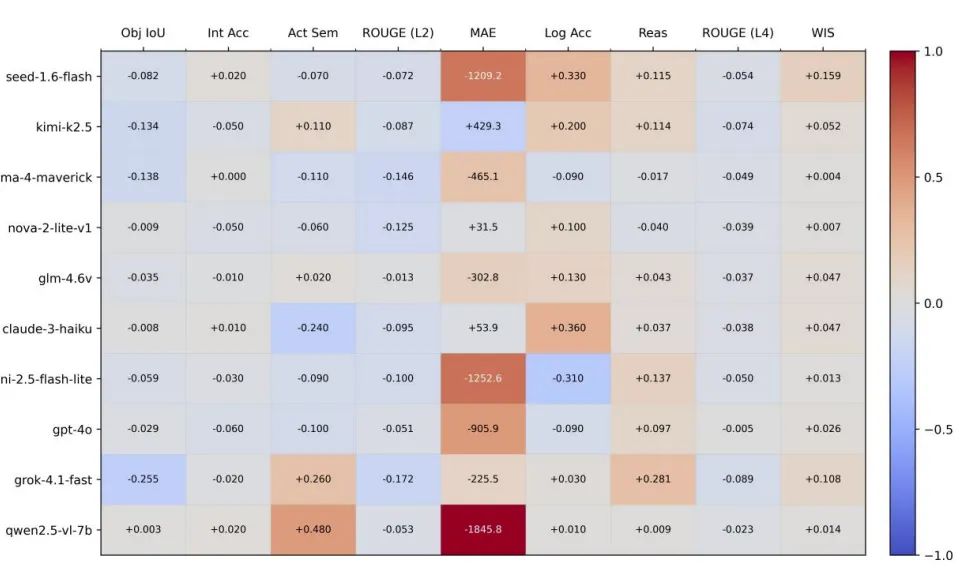
图 11. 热力图展示了通过 CoT 策略在各项指标上所实现的性能提升情况。
CoT有效激活潜在推理能力:Qwen2.5-VL-7B表现最为突出,WIS升至0.289,L3层MAE从1855.5暴跌至9.73,说明IEDD数据中的交互逻辑结构可通过提示工程有效提取,模型从纯视觉感知转向基于物理常识的分步推理; CoT并非对所有模型有效:Llama-4-Maverick、Claude-3-Haiku等模型的L2描述得分出现负增长,原因是CoT引入的长文本推理过程干扰了简洁驾驶动作描述的生成,导致“语义漂移”。
(四)域适配微调与消融实验:IEDD打造自动驾驶“领域专家”模型
选取表现最优的开源模型Qwen2.5-VL-7B,基于IEDD-VQA训练集进行LoRA低秩适配微调,采用PyTorch 2.6.0和PEFT 0.12.0框架,训练2个epoch后验证损失收敛至0.0993(图12),
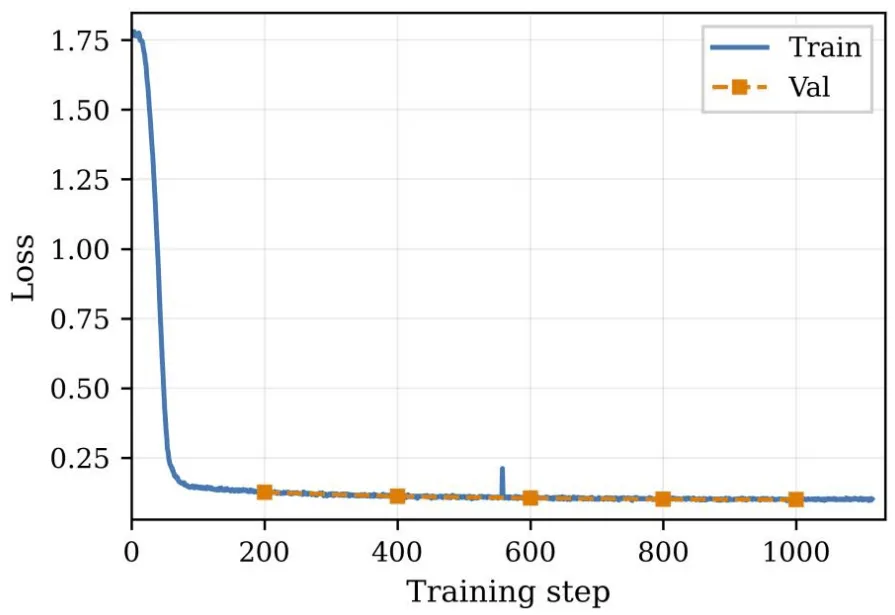
图 12. 在微调过程中训练损失和验证损失的收敛曲线。
实验结果如表6、图13所示,核心结论如下:
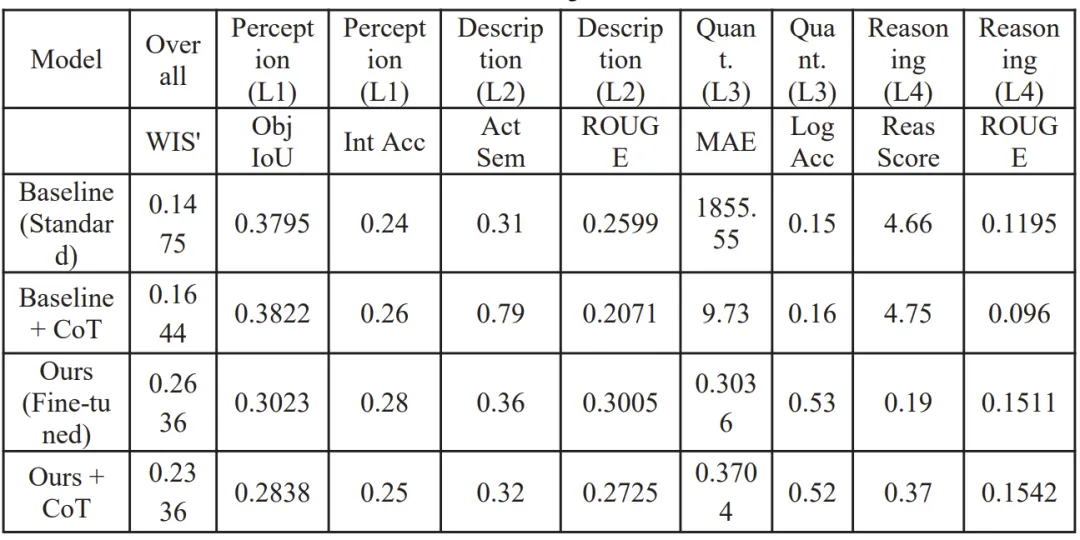
表 6.在微调前后针对分布内和分布外任务的性能消融研究。
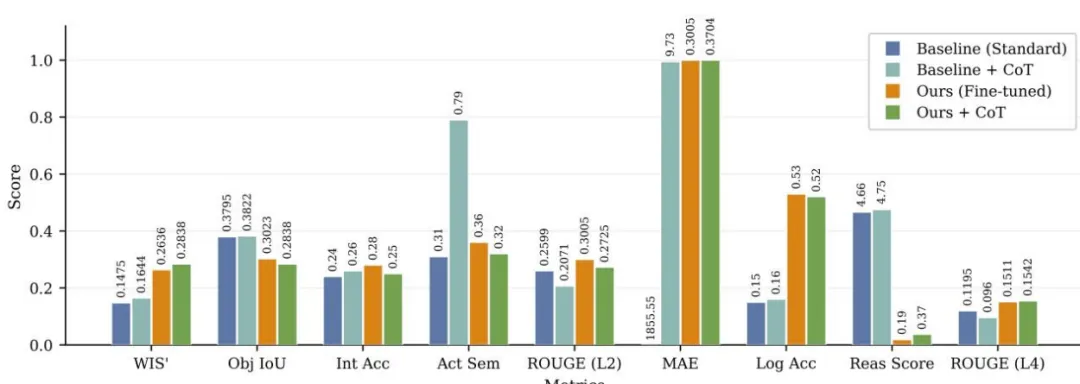
图 13. 各种评估指标在微调前后的详细对比柱状图。
整体性能大幅提升:微调后模型的修订加权综合得分WIS'从0.1475提升至0.2636,提升78.7%,成功弥合通用场景与自动驾驶交互的域差距; 物理量化能力实现质的突破:L3层MAE从1855.55骤降至0.3036,逻辑一致性从0.15提升至0.53,模型掌握了视觉特征到物理参数的精准映射机制; 动作描述更贴合专业术语:L2层动作语义得分从0.31升至0.36,生成的驾驶行为描述与行业术语更对齐,且微调后CoT策略变为冗余信息,反而导致性能下降; 存在域特化与通用能力的权衡:微调后模型在未参与训练的L4反事实推理任务上得分从4.66暴跌至0.19,出现“灾难性遗忘”,说明LoRA微调在强化域特化能力的同时,牺牲了模型的通用逻辑推理能力。
四、总结思考:IEDD的价值与未来研究方向
同济团队提出的交互式增强驾驶数据集(IEDD),是解决自动驾驶VLA模型交互场景数据稀疏、多模态对齐不足问题的一次重要探索,其核心价值体现在三个方面:
数据层面:构建了730万级的异质交互驾驶数据集,实现了长尾高风险交互场景的规模化覆盖,91%的多智能体交互样本填补了复杂群体交互数据的空白,同时通过合成BEV视频和结构化语言,实现了视觉-语言的严格时空对齐; 方法层面:提出了可扩展的交互挖掘、量化、多模态合成流水线,设计了强度-效率双维度的交互量化体系,为自动驾驶交互过程的定量评估提供了通用标准,同时建立了“感知-描述-量化-推理”的分层评估基准,为VLM模型的测评提供了科学依据; 应用层面:通过十款主流VLM的测评和微调实验,验证了IEDD数据集在提升模型自动驾驶交互感知、量化能力上的显著效果,能将通用VLM转化为自动驾驶交互领域的“专家模型”,为VLA模型的域适配提供了实证依据。
同时,实验也暴露了现有研究的不足:域适配微调会导致模型的通用反事实推理能力下降,这也是未来研究的核心方向。团队建议,在后续的指令微调中,需融入更广泛的任务重放或正则化策略,在追求域特化性能峰值的同时,保持模型对分布外(OOD)数据的鲁棒性,实现“域特化能力”与“通用推理能力”的平衡。
此外,IEDD数据集和相关代码已实现开源:数据集归档于Zenodo,代码开源在GitHub仓库,为自动驾驶领域的研究者提供了丰富的数据集和工具支持,有望推动VLA模型在复杂交互场景中的进一步发展,加速自动驾驶向全自动化的落地。

END
[T-ASE] 时空有向图赋能自动驾驶:实现混行交通下智能协商决策
东南 SG-CADVLM:上下文感知解码赋能,让自动驾驶危情模拟更真实
[ ICRA 2026 ] 车辆感知加持,3D 行人姿态预测新成果
ScenePilot:3847 小时跨 63 国驾驶数据,打造自动驾驶 VLMs 评估新标杆
清华 & 现代汽车 音频-情绪-视觉协同:EchoVLA 的多模态 CoT 推理与自动驾驶优化
浙大 & 港大 AutoDriDM: 给自动驾驶 “AI 大脑” 做决策考试,VLMs 的能力边界被说透了!
【TR-C】南理工 & 华科:博弈 + 稀疏性双 buff!自动驾驶极端场景生成算法,精准戳破算法漏洞
复旦 & 理想 & 同济等 SGDrive: 用场景 - 智能体 - 目标三层认知,让 AI 像老司机一样思考
慕尼黑工业提出:聊天控车的LLM 驱动框架,让自动驾驶语音指令精准落地!
CAR 实验室 & 特华拉 DAVOS:毫秒级响应 + 隐私防护双 buff,让自动驾驶又快又安全
清华 & 港中文 & 滴滴 ColaVLA:用 latent 推理 + 并行解码实现高效安全驾驶
西交 & 南理工 HOCD:融合司机意图与状态的协作驾驶方案,冲突率大降 2.4+
华科 & 小米 DriveLaw:让自动驾驶兼具场景想象力与行驶稳定性
港理工 UrbanV2X 多传感器车路协同数据集:3 大场景、含 7 类车载 + 3 类路侧设备,破解城市峡谷自动驾驶定位难题

分享

收藏

点赞

在看
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Tensor发布全球首个L4原生自动驾驶汽车 Tensor Unveils World's First Native Level 4 Autonomous Vehicle
- 大众“不再坚持”,荣放同级SUV,配多连杆,比CR-V便宜,一箱油能跑800公里
- R1XX对自动驾驶系统ADS的要求2️⃣4️⃣
- 马自达SUV“真火了”!大排量引擎喝92油,8雷达6喇叭,顶配才13万多
- 招聘-自动驾驶仿真测试工程师
- 不按常理出牌!蔚来ES9旗舰SUV,预计5月上市,ES8或将退居次席!
- 渥太华市中心一辆SUV撞倒4名行人后,又冲进街边商店,造成多人受重伤!
- 吉利星越L又一次拿到燃油SUV年度销量总冠军,两年的使用感受告诉你答案!
- 全球第一!王朝首款B级纯电SUV!比亚迪宋Ultra EV配大床模式,预计18万
- 某紧凑型SUV碰撞性能优化方案
