在地平线搞自动驾驶的这三年
- 2026-02-28 01:12:11
作者 | candywisdom 编辑 | 自动驾驶之心
点击下方卡片,关注“自动驾驶之心”公众号
从自动驾驶转到具身智能已经有一年的时间了,之前在自动驾驶上一系列工作和一些个人思考还一直没有好好的做个总结。(Ps: 虽然广义来说,自动驾驶属于具身智能的子领域,但是现阶段二者所面临的问题和解决问题的具体方式还是存在较大差异,所以还是算是进入了一个转向了一个新的方向。)
可预期的短时间内,主要精力投入应该不会放在自动驾驶上了,但总觉得该给自动驾驶的这段经历留个记录。倒不是说这些工作多“惊天动地”,反而有些是“关注度不高但挺实在”的探索,它们可能没上过热搜,但个人认为其确确实实解决过实际问题,希望可以给做相关方向的朋友提供点参考。
在做自动驾驶期间,我主导过研究方向主要包括3D融合感知(Sparse4D系列)、轨迹预测(EDA)、端到端运动规划(SparseDrive)、传感器仿真(DriveCamSim)、交通流仿真(UniMM)以及智驾基础模型(LATR),这些研究之间的相互关系如下:
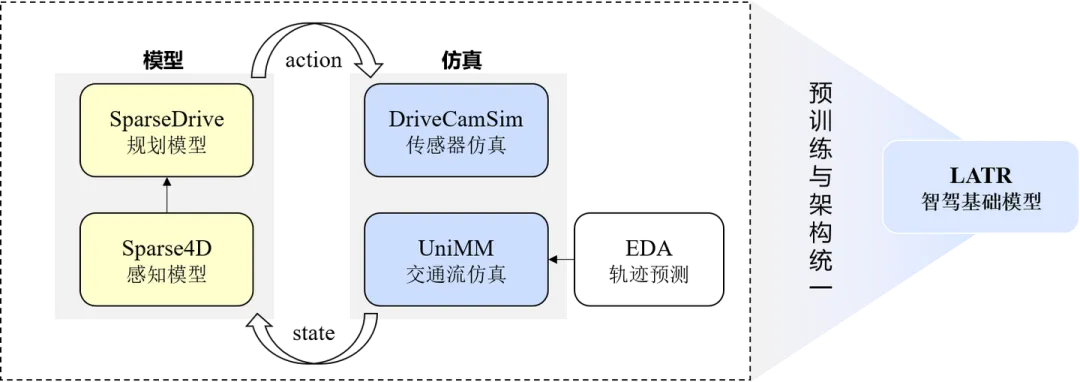
这些工作的递进关系可概括为:
从目标检测开始逐步往端到端planning拓展,构建一个强有力的端侧policy; 针对端到端模型的闭环评测和训练,构建传感器和交通流的仿真模型; 通过大数据量和大参数量构建一个智驾领域的基础模型,一方面可以为所有下游任务做预训练,另一方面想通过多任务统一的方式激发模型潜能。
所有研究点合在一起,目标是构建一个完备的自动驾驶算法系统。下面针对上述的7个研究点展开进行说明。
1. Sparse4D系列:极致性能的多传感器融合感知框架
当时受Tesla的影响,掀起了一波BEV浪潮,大家都涌入BEV方案的怀抱,但是我们认为BEV并不是一个那么合理的方案。首先是从图像特征构建BEV特征,并没有带来信息量的提升,但是却需要消耗大量的计算成本(特别是对于端侧芯片);其次BEV特征限制了模型的感知范围,感知范围、感知精度和计算效率三者难以平衡,面临着不同驾驶场景需要训练不同的BEV分辨率的模型,迭代起来很麻烦。
所以我们尝试利用稀疏query加内外参投影采样的方式,直接从多视角图像特征得到融合感知结果,最终做出了Sparse4D系列。
Sparse4D v1是最基础的版本,核心就是下图的deformable aggregation算子,它实现了纯稀疏范式的融合感知,query是稀疏的,query和image feature的交互也是稀疏的,理论计算复杂度远小于BEV方案或者其他dense方案。
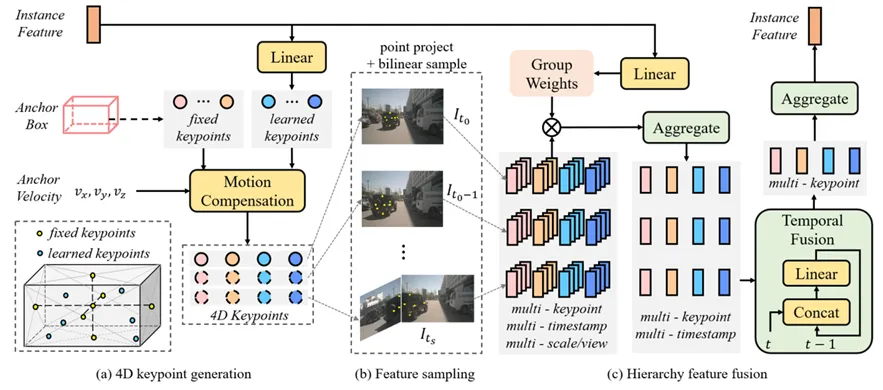
但是v1留下了一个坑,就是它的时序融合计算复杂度是O(T),计算量随着融合的帧数线性增长,对训练和推理都不太友好,所以在Sparse4D v2中我们将时序融合方式从多帧并行采样改为了recurrent的形式,每一帧的instance feature都会往后传递,时序复杂度降低至O(1),并且原理上可以融合历史所有帧的信息。
除此之外,为了让模型在GPU上推理速度更快,我们对核心算子deformable aggregation进行了高效的实现,实现了并行的最大化。 Sparse4D v2不仅获得了更快的训练和推理速度,还大幅提升了模型的性能。
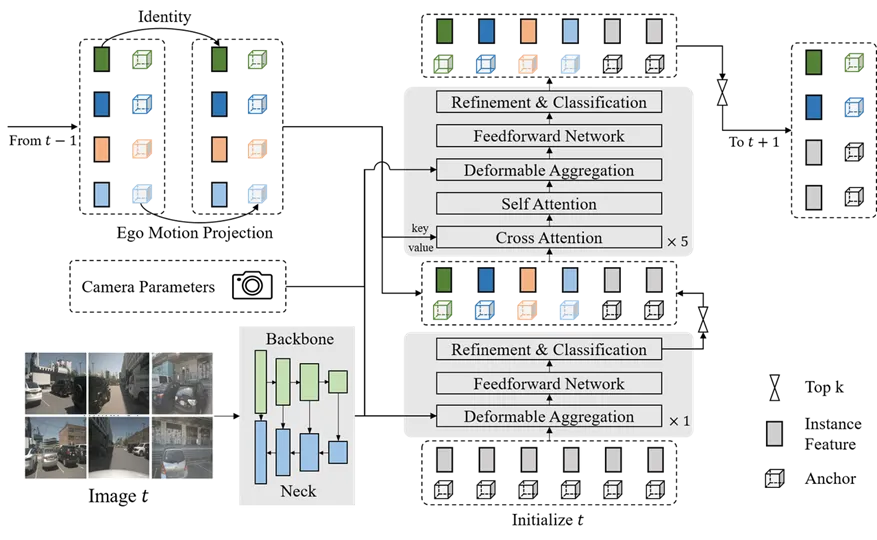
到了Sparse4D v3,有两个方面的提升,一个是对感知性能更加极致的追求,另一个是向下游任务拓展。性能方面,我们通过temporal denoising、decouple attention、quality estimation让模型的检测能力和收敛速度都有显著提升。
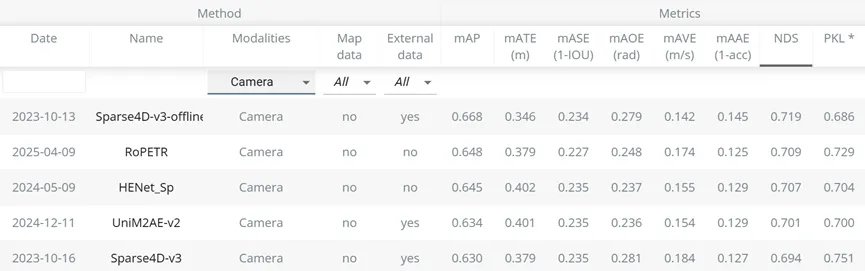
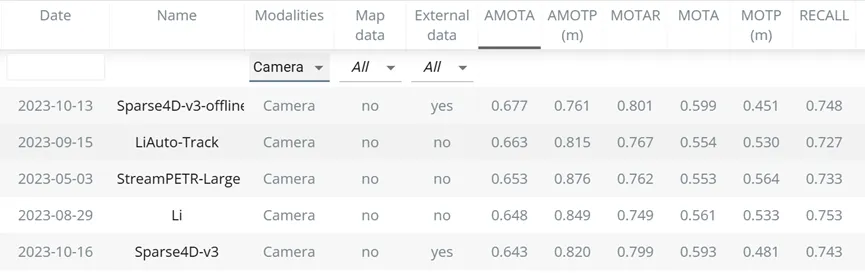
不过这些改动还只能算一些小tricks,Sparse4D v3的核心贡献是它用最为简洁的方式实现了联合检测与跟踪,无需对detector做任何修改,无需任何tracking label,就能实现稳定跟踪。Sparse4D v3获得了非常好的感知性能,无论是在公开数据集还是在内部的业务数据集上,而且从2023年10月提交到nuScenes leaderboard至今,它仍然位居camera-only detection和tracking两个榜单的第一名。
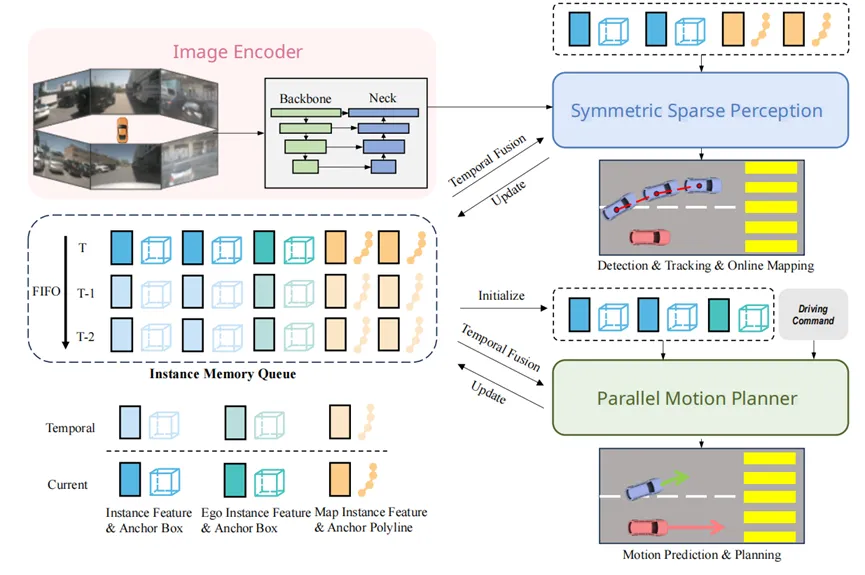
2. SparseDrive:从感知迈向端到端规划的一次尝试
当我们有了Sparse4D这样一个动态目标检测模型之后,我们希望它能进一步往其他任务上拓展,于是就有了SparseDrive。SparseDrive的主要工作包括两个方面,一个是将online mapping任务加进来,另一个是设计了一个简单的motion planner,实现了端到端的他车轨迹预测和自车轨迹规划。SparseDrive实现了5个任务,检测、跟踪、建图、预测和规划,并在nuScenes上进行了大量的实验,这五个任务在当时都获得了不错的效果。
有人可能会提出疑问,以稀疏feature作为planner的输入,是不是会丢失很多信息,比如非白名单物体的避障是不是就实现不了?我认为是完全不会的,稀疏feature虽然进行了检测loss进行了约束,让它们尽可能对白名单有目标更高的响应,但有个query的数量非常多,远超待检测目标数量,其他负样本的query会覆盖到所有的可视范围,这些query会受到planning loss的影响,关注到每个对规划有影响的区域。
SparseDrive存在的问题也很明显,它的planning decoder结构比较简单,而且端到端任务只在nuScenes上进行了开环评测,开环的指标只能说明它具备拟合能力,说明不了闭环性能。因此目前我们还在尝试通过仿真器进一步设计decoder的模型结构和训练方式,以达到更好的闭环性能。
3. EDA & UniMM:轨迹预测与交通流仿真的协同研究
轨迹预测是一个非常经典的任务,接入learning之后轨迹预测的算法爆炸式增长,效果也确实得到了显著的提升。但是这些算法大多集中在研究网络结构怎么设计,并没有触及轨迹预测的核心问题。
众所周知,目标检测算法的核心问题就是正负样本分配,无论是YOLO、FasterRCNN还是DETR,网络结构的不同并不是影响检测性能的关键,于如何设计一个让模型最容易学习的正负样本分配策略才是关键。其实在轨迹预测任务中,依旧如此,无论是Dense(HOME、DenseTNT)还是Sparse(TNT、MTR)方案,它们都是定义了某种形式的anchor,并给这些anchor分配正负样本的标签。我们发现轨迹预测中的anchor及其正负样本分配会严重影响预测性能,不正确的分配策略会使得预测结果模态坍缩或者精度不足。
因此我们提出了EDA(Evolving and Distinct Anchors),一种动态更新的anchor,并在匹配时采用NMS策略,让模型能更容易收敛。EDA可以很好的建模轨迹预测的多峰分布,并且具备良好的预测精度。EDA的另一大优势在于它可以和大多数轨迹预测模型完美契合,即插即用。
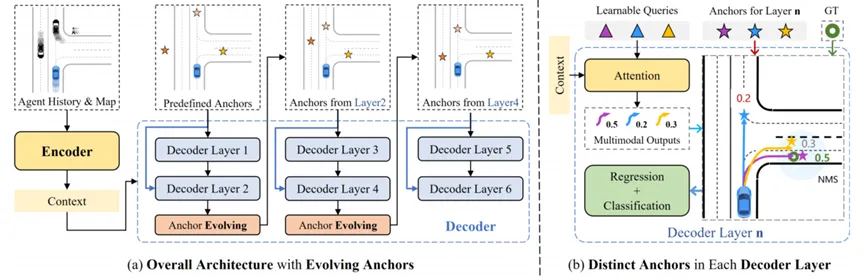
回到轨迹预测这个任务本身,它其实是连接感知和决策的中间件,一方面受感知噪声的影响,使得预测性能受限,另一方面由于输出的未来分布非常复杂,下游想用起来也是一大难点,有的规控团队可能只使用了一条预测置信度最高的轨迹,这也限制了预测带来的收益。多重因素叠加,使得轨迹预测算法的应用处于一个非常尴尬的状态。但是轨迹预测算法本身的研究还是有很必要的。这里就需要谈到另外一个任务,交通流仿真(agent simulation)。
轨迹预测和交通流仿真在输入输出形式上极其相似,都是输入历史帧的结构化信息,输出未来一段时间内所有交通参与者的轨迹。二者的区别在于轨迹预测是开环的,交通流仿真需要闭环进行rollout。
这里开环和闭环本质区别在于建模多个交通参与者之间的相互关系,熟悉轨迹预测任务的朋友可能知道,轨迹预测包含边缘轨迹预测和联合轨迹预测两个子类,边缘轨迹预测建模每个交通参与者的独立分布,而联合轨迹预测建模的是两个或多个交通参与者的联合分布。联合轨迹预测其实是一个伪问题,而交通流仿真通过每一个step都重新采样的方式绕开了直接建模多车联合概率,其更能反映算法的性能。
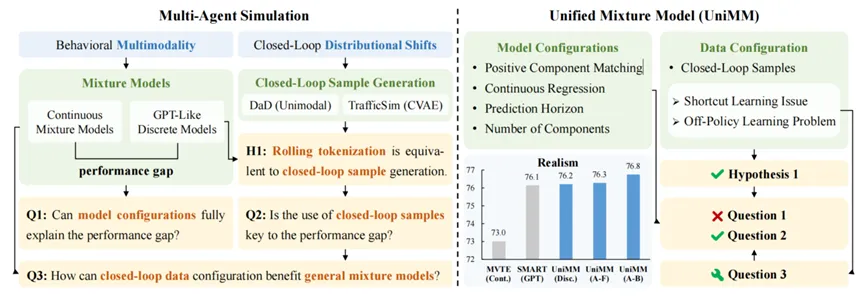
我们提出了UniMM,这篇文章研究了现有的主流交通量仿真方案,解释了那些设计是影响算法性能的关键因素。UniMM将主流的两大类模型Continuous Mixture Models和GPT-Like Discrete Models进行了统一,并提出了通用的算法框架。UniMM是以问答的形式展开的,回答了这个任务的一些关键问题。有兴趣的可以去翻阅一下这篇论文。
4. DriveCamSim:高度可控的自动驾驶传感器仿真
当我们有了端到端模型之后,下一步我们需要思考的不仅仅是如何优化端到端模型本身,还需要思考如何高效的评测。实车评测当然是最为直接的方式,短期内用实车评测没有任何问题,但是当我们的端到端模型提升到某个阈值之后,发现不同时刻的小规模实车评测结果难以正确的反映模型性能。例如,当模型MPI达到50以后,需要至少实车跑多少公里才能准确的测出不同模型之间的差异呢?每次都需要多辆车同时开几百升至几千公里才能较为准确的反映模型性能。
很显然,到这个时候模型的迭代已经很困难了。那在可以预见的未来,当模型MPI达到几百或者几千之后,再想通过实车测试反映模型性能几乎就不可能了。所以,我们必须在云端去构建一套精准的评测系统,最为直接的实现方式就是构建仿真系统。这里说的仿真不是基于物理引擎构建的仿真,而是能对真实数据回放的、足够拟真的仿真系统。
仿真的关键在于如何做到拟真性和可控性。基于3DGS的仿真方案在可控性和拟真性上都有一定的优势,但是它本质还只是一个重建方案,新视角合成质量无法保证,仿真rollout过程中会涉及到大量的未观测信息的脑补,这是重建方案无法实现的。而且动态场景的重建pipeline比较复杂,存在各种corner case,也会导致最后仿真效果并不理想。所以我们希望以生成算法为中心来构建仿真系统。
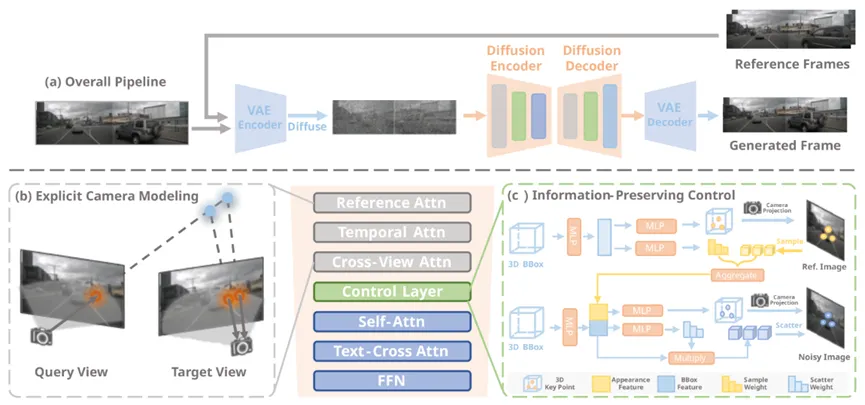
我们将仿真系统解耦成交通流仿真和传感器仿真两部分,利用UniMM基本解决了交通流仿真问题,剩下的就是传感器仿真了,因此我们做了DriveCamSim。传感器仿真的核心是用尽可能多的确定性信息作为condition,生成传感器信号,并且保证condition和生成结果之间的一致性要足够好。现有的大部分生成算法,直接把各种feature全部塞进一个DiT里面,这种是完全不行的,模型没有办法去感知整个3D空间,没有办法建立3D condition和2D image之间的相关性,想通过硬堆数据大力出奇迹的方式来实现传感器仿真不是明知之举,在后续需要多车型、多传感器配置泛化的时候,会暴露出更多问题。
在DriveCamSim中,我们通过显式投影的方式,来约束3D-2D和时序的一致性。对于DriveCamSim模型本身来说,完全解耦了时间和空间的概念,可以生成任意帧率、任意相机内外参、任意相机数量下的图像。相比于那些完全基于attention硬拟合图像patch之间的相关性的方案来说,DriveCamSim是有非常显著的优势的。DriveCamSim可以适应的condition也很充分,包括3D bounding box、地图、自车pose、相机内外参以及任意数量的参考图像。这是我个人非常喜欢的项目,但因时间精力限制,其落地潜力尚未充分挖掘,期待后续有人能将其推向实用。
5. LATR:智驾基础大模型初探
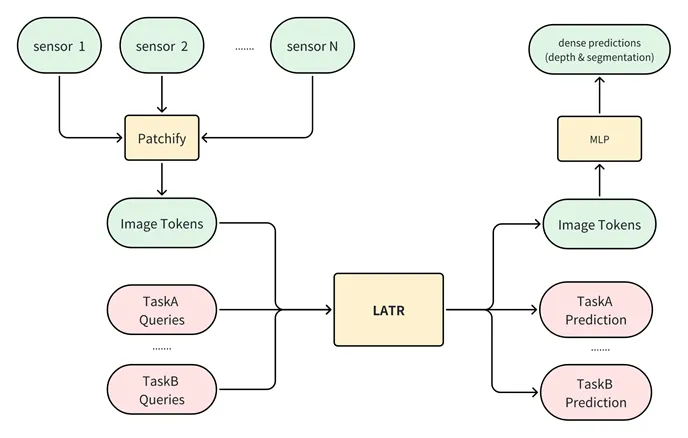
受大语言模型的启发,我们想在智驾场景下也通过大数据量和大参数量去构建一个性能强劲的基础大模型。我们初期规划智驾基础模型应当满足以下两点:一个是需要利用海量数据进行无监督训练,让它能够基本理解智驾场景的语义、空间和时空;其二是在接入下游任务做监督训练时,要尽可能复用预训练中的参数,减少新增参数,所以在模型架构上要能实现多任务的统一。
我们首先利用Mask Image Modeling的方式在海量数据上进行无监督训练,通过masking策略的设计,让模型需要通过相邻视角和时序帧的特征来估计mask部分的图像,使得模型能够理解空间和时间的关系。这部分工作注意就集中在masking策略上,做到尽可能让模型补全的难度加大,才能达到更好的训练效果。
接着,我们设计一个可以统一自动驾驶所有任务的decoder-only的模型结构,新增一个task只需要新增一个query到task output的MLP,最大程度发挥预训练参数的作用。我们将3d detection & tracking、online mapping、ego pose estimation、motion prediction、planning、depth estimation和novel-view synthesis这7个任务融合到了这个统一框架中,在效果上达到了和SparseDrive相当的水平,初步证明了所设计的模型结构及其训练方式是切实有效的。
(注:该项目未以论文/技术报告形式公开,略有遗憾。)
总结与展望
上述7个模块共同构成了自动驾驶系统的核心链路。从现在这个回顾过去的角度来看这些工作依旧是正确的,它们形成了一条正确的技术路径。首先,我们做了融合感知Sparse4D和端到端规划SparseDrive,让自动驾驶汽车从看得懂到开得稳;其次,考虑到后续端到端模型长期迭代对评测的需求,我们通过将仿真系统解耦成交通流仿真和传感器仿真两个部分,提出了UniMM和DriveCamSim;最后,我们通过大数据量、大参数量以及合适的模型结构设计,搭建了智驾基础模型LATR。
目前由端到端模型主导的端侧方案逐步趋向于成熟,选择拥抱端到端的自动驾驶厂商都获得了非常显著的性能提升。大家在进一步优化端到端模型的同时,需要将目光放得更加长远。端到端模型的性能可不可以得到进一步提升,很大一部分都是由评测方式决定的。如何高效地、准确地完成模型评测是核心问题,如果完全依赖实车测试,大概率在进度是会被甩开的。构建评测系统,有两条路径可以并行尝试:
直接训练评测模型(类似RL中的Critic Network),以观测与动作为输入输出动作质量(安全性/舒适性等),简单直接易落地; 通过仿真系统评测(基于UniMM与DriveCamSim),可解释性更强且更利于迭代。
再往后展望的话,若是端侧模型和评测系统都得到充分发展,下一步就是如何利用RL提升模型性能了。当前阶段RL在自动驾驶上的作用还无法被完全发挥出来,很大一部分就是因为评测系统的不成熟。此外,智驾基础模型的研究同样关键——它既是所有任务的终极载体,也可能是十年后自动驾驶厂商的核心竞争力。
自动驾驶之心
论文辅导来啦

自动驾驶之心创建了近百个技术交流群,涉及大模型、VLA、端到端、数据闭环、自动标注、BEV、Occupancy、多模态融合感知、传感器标定、3DGS、世界模型、在线地图、轨迹预测、规划控制等方向!欢迎添加小助理微信邀请进群。

知识星球交流社区

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 这台大众SUV卖22万,车长近5米,2.0T四驱,还买什么汉兰达啊?
- 别克造了一辆“冠军”SUV!237马力仅8.12L油耗,只售15.99W,31天卖出14355辆
- 保时捷旗舰SUV放弃纯电,改用V8
- 摩托车、三轮车、小轿车在街道上穿梭,载着人们奔赴新的工作与生活.
- #全能SUV不止于城市
- 美中日欧齐点赞,自动驾驶法规大一统时代来临!联合国UNECE通过系统全球技术法规草案
- EUROGATE汉堡启动第二个自动驾驶码头牵引车试点项目
- 让“心灵”开启“自动驾驶”
- 线控转向破局者:浙江世宝的自动驾驶“掌舵”之路
- 这才是宝马的诚意!豪华中型 SUV 20 英寸轮毂 + 8.2L 油耗,比奥迪 Q5L 还香,仅售 45.99 万起
