论文解读 · BEV 感知 · 对比学习
用对比学习补强自动驾驶 BEV 感知
BEV 感知模型想要更准,除了继续堆编码器、换检测头,也可以回到一个更基础的问题:特征本身学得够好吗?
论文链接:BEVCon: Advancing Bird's Eye View Perception with Contrastive Learning
代码链接:matthew-leng/BEVCon
在自动驾驶感知中,鸟瞰图(Bird's Eye View, BEV)表示已经成为多相机 3D 检测、分割、预测和规划任务中的核心中间表达。它把环视相机采集到的透视图像特征,统一映射到俯视空间,让下游模块更容易理解车辆周围的空间结构。
不过,现有 BEV 方法大多把优化重点放在 BEV 编码器 和 任务检测头 上,对「如何让 BEV 特征本身学得更好」讨论得并不多。
一句话总结:BEVCon 不额外引入数据、不改变主干任务,而是通过对比学习同时增强 BEV 表示和图像特征表示,从而提升 3D 检测性能。
1. BEV 感知为什么需要新的监督信号?
典型的基于图像的 BEV 感知流程可以概括为三步:
这个流程看起来清晰,但训练时会遇到两个关键问题。
1.1 检测损失传回图像骨干时容易变弱
以 BEVFormer 这类基于 Transformer 的方法为例,检测损失需要穿过多层 BEV 编码器、可学习查询和注意力模块,才能反向影响图像骨干网络。
这条梯度路径很长,也很复杂。最终结果是:检测头虽然在监督最终预测框,但对图像骨干和中间 BEV 表示的约束并不够直接。
1.2 BEV 网格和真实标注之间存在对齐误差
BEV 特征通常是离散网格,分辨率受计算量限制,不可能无限细。而 3D 标注框的位置、尺度和方向更加精细。
如果直接在低分辨率 BEV 网格上取实例特征,很容易把目标边缘、背景或邻近目标混在一起,导致实例特征不够干净,进而影响定位精度。
核心思路:既然最终检测损失不够直接,那就给 BEV 空间和图像空间都补上一条更细粒度的对比监督。
2. BEVCon 的整体框架
BEVCon 是一个可以插入现有 BEV 检测器的训练框架。它不依赖外部数据,也不要求重设计检测器结构,而是在原有检测损失之外增加两个对比学习模块:
- 实例特征对比模块(Instance Feature Contrast):作用在 BEV 空间,提升 BEV 实例特征的判别性和空间对齐能力;
- 透视区域对比模块(Perspective Regional Contrast):作用在图像空间,给图像骨干网络提供更直接的区域级监督。
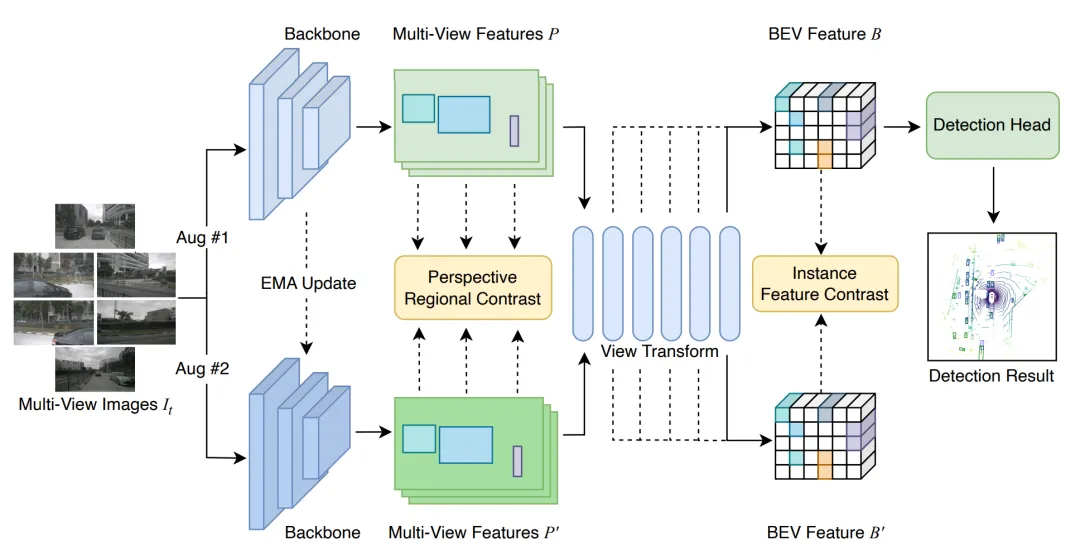 BEVCon 整体框架
BEVCon 整体框架图 1:BEVCon 在原有 BEV 检测框架上增加两条对比学习分支,分别监督 BEV 特征和图像特征。
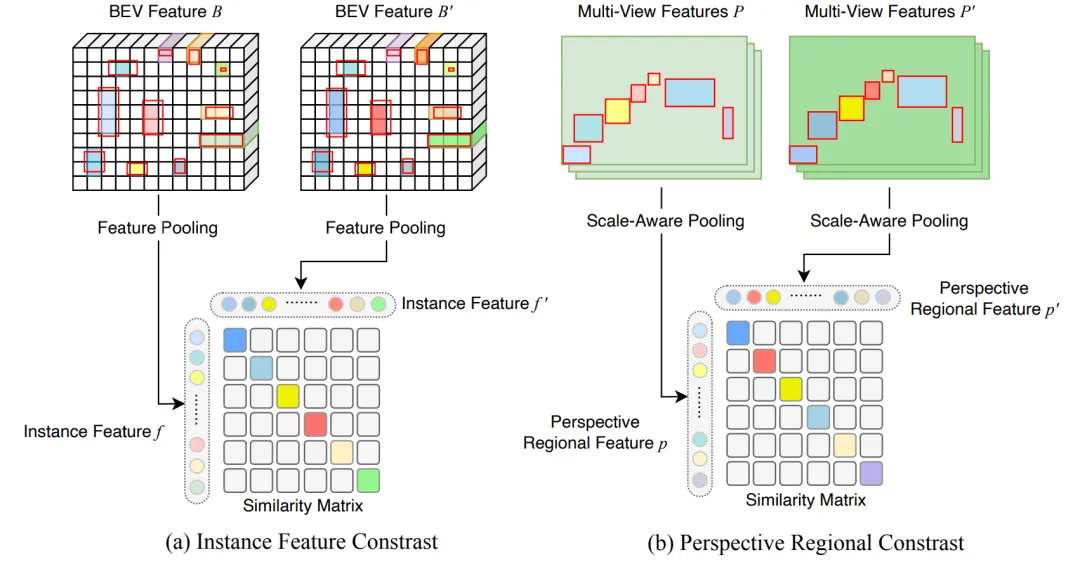 BEVCon 模块示意
BEVCon 模块示意图 2:实例特征对比关注 BEV 空间中的目标实例,透视区域对比关注图像空间中的目标区域。
3. 模块一:实例特征对比,优化 BEV 空间表示
实例特征对比模块的目标很直接:同一个目标在两种增强视图下提取出的 BEV 特征应该相似,不同目标的 BEV 特征应该可区分。
具体来说,对同一帧多相机图像做两次数据增强,得到两组输入。经过图像骨干和视图转换后,得到两张 BEV 特征图:
对于同一批 3D 标注实例 ,BEVCon 从两张 BEV 特征图中分别提取实例特征:
其中, 表示特征池化操作。对于第 个实例, 是正样本对;而 是负样本对。
对比损失可以写成:
这里的 是温度参数,特征会先做归一化,因此点积可以看作余弦相似度。
为什么要用 RoI Align?
BEV 特征图分辨率有限,如果直接根据目标框所在网格取特征,很容易产生量化误差。BEVCon 使用 RoI Align 提取实例特征,通过双线性插值减少特征与目标框之间的错位。
这一步很关键。它让对比学习不再只是「粗略地比较两个网格」,而是尽可能比较真实目标区域对应的 BEV 表示。
为什么要做多层对比?
对于 BEVFormer 这类包含多层 Transformer 编码器的方法,中间层也会产生 BEV 特征。BEVCon 对不同层的 BEV 特征都施加实例对比损失,并用指数权重控制不同层的重要性:
直观理解是:越靠近输出层的 BEV 特征越接近最终检测任务,因此给予更高权重;浅层特征仍参与监督,但影响更小。
4. 模块二:透视区域对比,直接监督图像骨干
实例特征对比主要优化 BEV 空间,但它的监督仍然需要通过视图转换模块传回图像骨干。为了让图像骨干直接学到更有用的目标级特征,BEVCon 又引入了透视区域对比模块。
它的做法是:在图像骨干输出的多级特征图上,根据 2D 标注框提取目标区域特征,并让同一目标在两种增强视图中的区域特征保持一致。
形式上,设图像骨干输出的多级多视角特征为:
其中 表示相机视角, 表示特征层级。根据二维标注区域 ,提取区域特征:
然后与增强视图中的对应区域特征 做对比学习。
尺度感知池化:解决目标重叠问题
驾驶场景中,2D 框重叠非常常见。近处车辆可能遮挡远处车辆,行人、自行车、车辆之间也可能在图像上相互覆盖。
如果直接对完整 2D 框做池化,一个区域里可能混入多个目标的特征。BEVCon 因此设计了 尺度感知池化:用参数 缩小边界框,只提取中心区域特征。
例如 时,只保留原始框中心 60% 的区域。这样可以减少重叠目标带来的特征污染,让图像空间的对比目标更干净。
5. 联合优化:对比损失和检测损失一起训练
BEVCon 并不是替代原有检测任务,而是在原有检测损失基础上增加两项辅助监督:
其中:
训练目标:检测损失负责最终任务目标,对比损失负责把中间特征学得更稳、更准、更有区分度。
6. 实验结果:多类 BEV 模型都有稳定提升
论文在 nuScenes 数据集上验证了 BEVCon,覆盖了三类典型 BEV 方法:
- 基于深度的方法:如 BEVDet、BEVDet4D;
整体结论很明确:BEVCon 对不同 BEV 架构都有稳定增益。
6.1 在 BEVFormer 上提升明显
这说明 BEVCon 不只是对小模型有效,在更强的基线模型上也能继续带来收益。
6.2 定位相关指标也有改善
除了 mAP 和 NDS,论文还观察到 mATE、mAOE、mAVE 等定位、方向和速度相关指标下降。
这与 BEVCon 的设计目标是一致的:实例级对比和区域级对比并不只是提升分类可分性,也在帮助模型学习更准确的空间表示。
7. 消融实验:哪些设计最关键?
论文的消融实验验证了三个重要结论。
7.1 两个对比模块最好一起用
单独使用实例特征对比或透视区域对比都能提升性能,但两者结合效果最好。
原因也比较清楚:实例特征对比强化 BEV 空间表示,透视区域对比强化图像骨干特征,两者作用位置不同,监督信号互补。
7.2 RoI Align 和多层对比很重要
在 BEV 空间中,RoI Align 能减少低分辨率特征带来的对齐误差;多层对比则让不同深度的 BEV 表示都获得实例级监督。
这两个设计共同提升了 BEV 特征的稳定性和精度。
7.3 尺度感知池化是透视对比的关键
如果去掉尺度感知池化,透视区域对比很容易受到重叠目标影响,训练稳定性和最终收益都会下降。
这说明图像空间的区域级对比不能简单照搬普通 RoI 池化,必须考虑驾驶场景中目标遮挡和重叠的特点。
8. 可视化效果:减少射线状伪影和重复预测
论文还展示了 BEVFormer 与 BEVFormer + BEVCon 的检测结果对比。
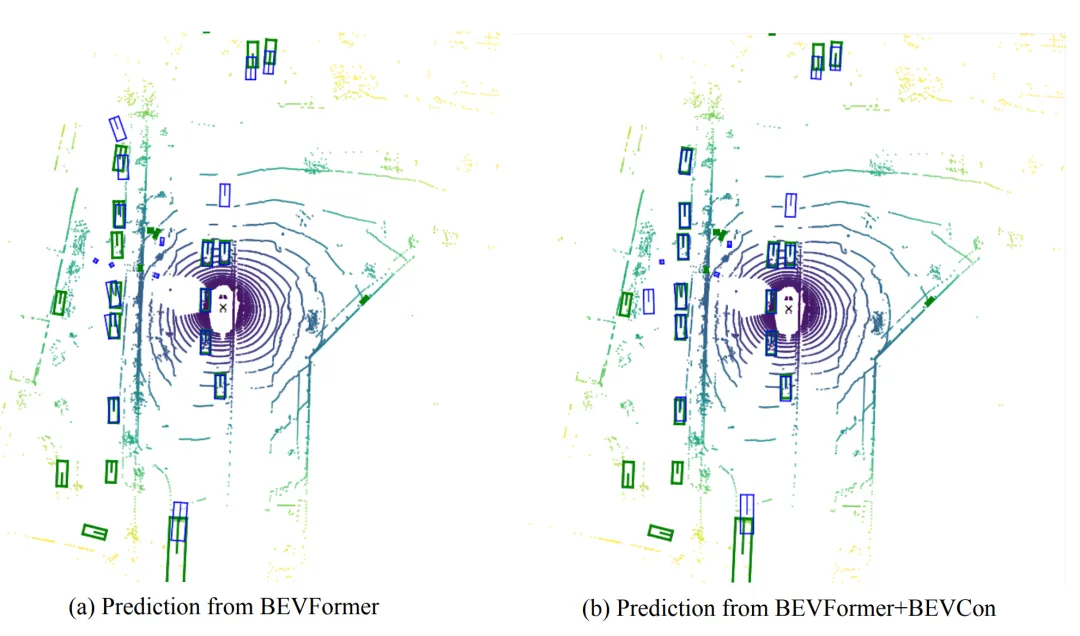 检测结果对比
检测结果对比图 3:绿色框为真值,蓝色框为预测框。加入 BEVCon 后,预测框与真值对齐更紧密,重复预测和射线状伪影有所减少。
从可视化结果看,BEVCon 对定位质量的改善比较直观:预测框更贴近真实目标,远距离或容易混淆区域中的重复预测也有所缓解。
9. 总结:BEVCon 的价值在哪里?
BEVCon 的意义不在于提出一个新的检测头,也不在于设计一个更复杂的 BEV 编码器,而是提供了一个更通用的训练视角:
对 BEV 感知来说,最终检测损失并不一定足以学好中间表示。通过对比学习补充实例级和区域级监督,可以让图像特征和 BEV 特征同时变得更可靠。它的核心价值可以概括为三点:
- 监督更细:从实例和区域粒度约束特征,而不是只依赖最终检测框;
- 路径更短:透视区域对比为图像骨干提供直接监督,缓解梯度经过视图转换后变弱的问题;
- 适配性强:能够集成到 BEVDet、BEVFormer、Sparse4D 等不同类型 BEV 模型中。
最后来看:对于自动驾驶感知模型的训练来说,BEVCon 提醒我们,在追求更强结构之前,也值得重新审视表示学习本身。把同一目标在不同视角、不同增强、不同空间中的特征对齐,可能就是提升 BEV 感知质量的一条高性价比路径。 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
