自动驾驶和具身智能大模型真的能通用吗
- 2026-06-21 22:24:31

「把算力变成数据,再把数据变成能力」
先说结论,自动驾驶和具身智能大模型在当前阶段都无法实现真正的通用性,但两者面临的技术瓶颈和解决方案路径存在显著差异。二者通用只是努力的方向,并不是目前现实。
自动驾驶更接近商业化落地,而具身智能仍处于技术探索期。关于二者通用性的鸿沟,我们从真实数据,合成数据、模型本身,以及执行机构制约四方面进行讨论。
数据作为大模型训练的“燃料”,其规模、质量与通用性直接决定了智能系统的落地能力,自动驾驶与具身智能在数据层面呈现出显著的差异化特征。
在自动驾驶领域,头部企业已积累海量真实测试数据,理想汽车2025年测试里程达4000万公里,其中实车测试仅占2万公里,合成数据已成为数据供给的主力。这些真实数据构成了自动驾驶系统的“基因库”,有效避免了模型训练的系统性偏差,但邬贺铨院士指出,在L4/L5级自动驾驶训练中,仅10%-20%的真实数据因具备高价值被保留使用。同时,中国《汽车数据出境安全指引》的出台,形成了本土化数据壁垒,进一步加剧了数据跨区域迁移的难度。从成本效益来看,合成数据的大规模应用已将实车测试成本从18元/公里降至0.5元/公里,但在长尾场景覆盖效率上仍存在短板。
具身智能的数据困境则更为突出,真实机器人交互数据的获取成本极高,人类示范数据的收集也面临诸多限制。这类数据需包含“感知-决策-执行-反馈”的完整闭环,且与具体硬件形态强绑定,不同类型的机器人(人形、机械臂、轮式)需要专属的交互数据。行业实践中,银河通用采用“99%合成数据+1%真实数据”的混合训练模式,特斯拉则坚持以真实数据为主、仿真数据为辅的路线,但无论哪种模式,都难以完全解决数据通用性不足的问题。

合成数据的发展为两大领域提供了新的可能。
自动驾驶领域的合成数据应用已趋于成熟,占比从2023年的20%-30%快速提升至2025年的50%以上,通过世界模型重建历史场景并扩展变体(如将普通路口转化为雨夜雾天场景),能够生成“人类未经历但符合物理规律”的极端Corner Case。英伟达DRIVE Sim通过添加9.2万张合成图像,将200米外车辆检测准确率提升33%,充分验证了合成数据的应用价值。
而具身智能的合成数据仍处于初期阶段,尽管英伟达可在11小时内生成相当于9个月的人类演示数据,使系统性能提升40%,但Sim2Real Gap(虚实差距)依然存在,物理交互的真实性难以完全模拟,目前主要适用于pick&place等简单任务,复杂任务仍依赖真实数据支撑。
数据层面的通用性制约核心在于:自动驾驶数据虽规模庞大但地域特异性强,不同国家和地区的道路规则、交通环境差异显著;具身智能数据极度稀缺且硬件绑定紧密,跨平台迁移难度极大;而合成数据的通用性则受限于世界模型的质量和物理规律的模拟精度。
模型架构是实现通用性的核心载体,自动驾驶与具身智能在技术路线选择上既有共通之处,也存在明显差异,均在探索兼顾性能与泛化能力的最优解。
自动驾驶的模型架构经历了“规则驱动→模块化设计→端到端大模型”的清晰演进路径。当前主流方案为多模态大模型(视觉-语言-动作VLA),小鹏汽车推出的720亿参数世界基座模型便是典型代表,能够融合多源传感器数据实现复杂场景理解。在部署策略上,行业普遍采用“云端大模型+车端小模型蒸馏”的模式,既保证了模型的推理能力,又满足了车端硬件的资源约束,实现“小身材、大智商”的目标。值得注意的是,Alpamayo等先进模型已具备链式推理能力(CoT),能够清晰说明决策逻辑,为自动驾驶的安全性提供了技术保障。
具身智能领域则形成了两大技术流派:以“大脑-小脑-肢体”为核心的分层架构成为主流选择,大模型负责感知决策,小模型专注于精准执行,这种架构具有数据需求相对较低、泛化性强、可模块化升级等优势;谷歌RT-2为代表的端到端架构则尝试直接从指令映射到动作,但其需要万亿级数据支撑,目前仍处于探索阶段。无论哪种架构,都需实现任务规划、导航、交互、技能学习的完整闭环,才能适配物理世界的复杂需求。
模型架构的通用性制约同样显著。自动驾驶模型需要适配不同的传感器配置,纯视觉方案与激光雷达融合方案的模型设计存在本质差异;具身智能模型则与硬件形态深度绑定,人形机器人与轮式机器人的运动控制逻辑截然不同,“一脑多形”仍是行业追求的理想目标。
执行机构作为智能系统与物理世界交互的载体,其特性直接定义了大模型通用性的物理边界,自动驾驶与具身智能在这一维度面临截然不同的挑战。
自动驾驶的执行机构具有相对标准化的特点,核心控制接口集中在油门、刹车、转向三大模块,但受到严格的物理约束和安全要求。车辆动力学限制(加速度、转向角、制动距离)决定了模型输出必须符合物理规律,而毫秒级响应要求和零容忍错误标准,使得系统需要冗余设计来保障安全性。更为复杂的是,开放道路环境的不可控性,要求自动驾驶系统能够处理无限长尾场景,与其他交通参与者进行动态博弈。
具身智能的执行机构则呈现出极度多样化的特征,人形机器人、机械臂、轮式机器人等形态差异巨大,对应的控制需求也千差万别。这类系统需要毫米级精度控制,同时保证运动稳定性,电池续航限制则制约了持续作业时间。更具挑战的是,具身智能需要处理与人类、物体、环境的复杂交互,不同场景下的交互逻辑缺乏统一范式,进一步加剧了通用性实现的难度。
从通用性对比来看,自动驾驶的执行机构相对标准化,但环境复杂性极高;具身智能则面临执行机构多样化与环境复杂性的双重挑战,难以建立统一的控制范式。这种差异使得两大领域的通用性突破需要采取差异化策略。
二者通用性对比分析如下:
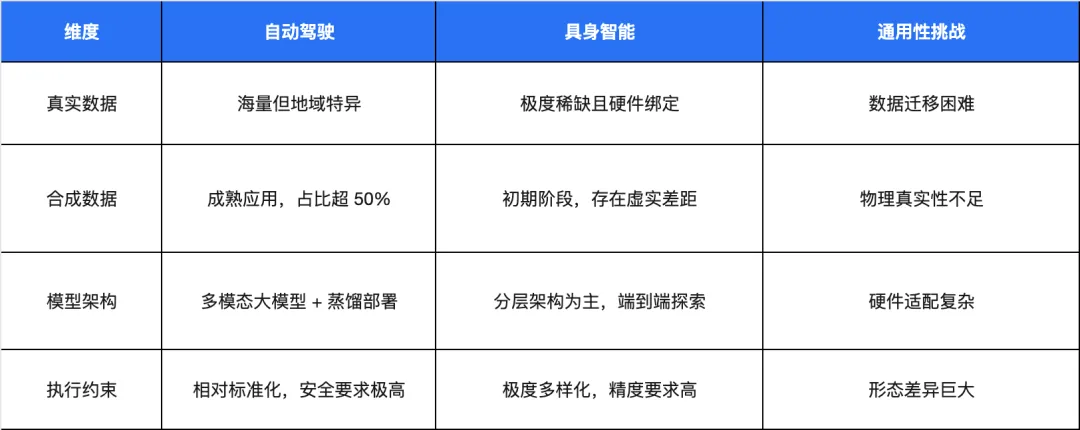
两大领域面临的共同挑战集中在四个方面:一是长尾场景覆盖难题,物理世界中的无限边缘情况难以通过模型完全覆盖;二是安全可靠性要求,物理世界中的错误代价极高,不允许“试错学习”;三是成本效益平衡,高性能与低成本的矛盾始终存在;四是法规合规压力,数据安全、隐私保护、责任归属等法律问题尚未完全解决。
差异化挑战则体现在:自动驾驶需应对开放环境的不可预测性,处理与其他交通参与者的动态博弈;具身智能则面临硬件多样性(比如丝杠电机和音圈电机就不是自动驾驶大模型能精细控制的)和任务复杂性的双重压力,需要更强的泛化和适应能力。
自动驾驶和具身智能模型如果想通用,主要是两条路:世界模型和模块化标准化。无论自动驾驶还是具身智能都在物理世界中运行,一个无所不包的世界模型当然是对二者着通用。至于标准化通用化,是指整套模型中的零件可以拆出来单独使用,互通互换,比如视觉的目标识别模型,对目标的位置和语义进行识别,对具身智能和自动驾驶都有通用意义。具体展开如下:
(一)自动驾驶通用性提升路径
车云一体数据闭环:构建“车端轻量化+云端智能化”协同体系,车端负责数据采集与实时推理,云端完成模型训练与优化迭代,形成高效的数据流转闭环。
世界模型驱动:依托NVIDIA Cosmos等世界基础模型,实现跨场景泛化能力,减少对特定场景数据的依赖。
英伟达的三台电脑范式:通过训练计算机、推理计算机、仿真计算机的协同运作,构建“数据生成-模型训练-仿真验证”的闭环系统。
本土化生态:在中国数据安全框架下建立独立技术体系,适配本土道路规则与交通环境。
行业实践中,理想汽车通过合成数据占比超90%的策略,将测试成本降至0.5元/公里;小鹏汽车的720亿参数多模态世界基座模型,将全链路迭代周期缩短至5天;英伟达则通过DRIVE Sim生成远距离物体合成数据,显著提升了极端场景的检测准确率。
(二)具身智能通用性提升路径
分层架构优化:深化“大脑(大模型)+小脑(控制算法)+肢体(硬件)”的协同机制,提升各模块的可迁移性。
数据高效利用:采用少量真实数据+大量合成数据的混合训练模式,降低对真实数据的依赖。
一脑多形愿景:推动同一智能系统适配不同形态物理实体,建立统一的技能迁移框架。
标准化推进:建立统一的操作系统和软件开发工具链,降低硬件适配成本。

图|银河通用机器人现场,来自网络©️【深蓝AI】编译
典型案例包括银河通用通过“99%合成数据+1%真实数据”完成pick&place任务;Figure AI采用三层架构,整合OpenAI大模型、神经网络策略与全身控制器;谷歌RT-2基于VLM的端到端模型,展现出初步的物理常识推理能力。
大模型在自动驾驶与具身智能中的通用性是有限的,这种限制并非源于模型本身的能力不足,而是深深植根于物理世界的本质特征:物理世界的复杂性使得数字智能无法完全替代亲身体验;执行机构的多样性导致统一控制范式难以建立;安全要求的严苛性限制了模型的“试错学习”空间;高质量真实数据的稀缺性则制约了模型泛化能力的提升。
真正的通用性不在于追求单一模型的“万能化”,而在于构建灵活、可组合、可迁移的技术体系。
未来的突破将来自于“世界模型+合成数据+分层架构+标准化接口”的综合解决方案,通过高效的数据生产-模型训练-实际部署闭环,实现智能能力的跨场景、跨平台迁移。
正如黄仁勋所言,“把算力变成数据,再把数据变成能力”,大模型在物理世界的通用性落地,最终将取决于能否建立高效的技术闭环,而非依赖单一超级模型的“单点突破”。
商务推广/稿件投递请添加:xinran199706(备注商务合作)


· 计划周期:深蓝学院将以3个月为一个周期,建立工程师&学术研究者的「同好社群」
· 覆盖方向:自动驾驶、具身智能(人形、四足、轮式、机械臂)、视觉、无人机、大模型、医学人工智能……16个热门领域
扫码添加阿蓝
选择想要加入的交流群即可
(按照提交顺序邀请,请尽早选择)
👇

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 3月起,电动车又有新政策,电动车、三轮车、四轮车都在内,车主注意
- 交警提醒:除了禁止挡风被,2026年电动车上路,还要满足“2要3不要”新规
- 首款纯中国研发生产的电动汽车如何拯救大众汽车?
- 3000元左右买电动车,这6款是五大品牌“杀手锏”车型,72V高配车
- 电动汽车终局思考
- 车主找到了!长沙猴子石大桥“无主”电动车引关注,交警:外卖骑手摔伤治疗后返乡休养,租车公司未及时去拖车
- 特斯拉自动驾驶Robotaxi:事故率是人类司机9倍?而Waymo无人车事故率却显著低于人类水平
- 酒后用自动驾驶算酒驾吗
- 【港股打新】自动驾驶视觉系芯片玩家,爱芯元智申购分析
- 可惜一款中型轿车,标配双10.25英寸液晶屏,续航800km,却被冷落
