
辞旧迎新,知识续航!「龙哥读论文」陪你跨年,知识星球会员优惠券限时限量放送!🐉 「龙哥读论文」知识星球:让你看论文像刷视频一样简单!公众号每日8篇拆解不够看?星球无上限更AI领域论文、资讯、招聘、招博、开源代码,一站式干货,每日2分钟刷完即赚!👇扫码加入「龙哥读论文」知识星球,前沿干货、实用资源一站式拿捏~

龙哥推荐理由:
自动驾驶想用大模型听懂人话?算力先把你劝退!这篇论文给出了一个“既要又要”的优雅解法:让大模型自己当老师,教一个小模型学会“抓重点”,从而把海量视觉信息压缩到极致。性能几乎不打折,计算量却能暴降30倍,堪称端到端自动驾驶大模型的高效瘦身指南。🚗💨
原论文信息如下:
论文标题:
SToRM: Supervised Token Reduction for Multi-modal LLMs toward efficient end-to-end autonomous driving
发表日期:
2026年02月
发表单位:
Sungkyunkwan University (成均馆大学)
原文链接:
https://arxiv.org/pdf/2602.11656v1.pdf
想象一下,你的自动驾驶汽车不仅要看懂路,还得听懂你的指令:“前面路口右转,小心那个突然窜出来的滑板少年!”这听起来很智能,对吧?但背后的多模态大模型(MLLM)可能正在车里“气喘吁吁”——它要处理海量的摄像头图像、激光雷达点云,还要理解你的话,计算量大到芯片都在发烫。这就是当前端到端(E2E)自动驾驶面临的核心矛盾:我们既想让AI拥有类人的多模态理解和推理能力,又受限于车载芯片的实时计算能力。成均馆大学的研究者们提出了一个巧妙的解决方案:SToRM。它就像一个给大模型配的“高效秘书”,能自动筛选出最重要的视觉信息,让大模型只处理精华,从而在几乎不影响驾驶性能的前提下,把计算量最高暴降30倍。🚗💨自动驾驶新挑战:大模型虽好,计算吃不消
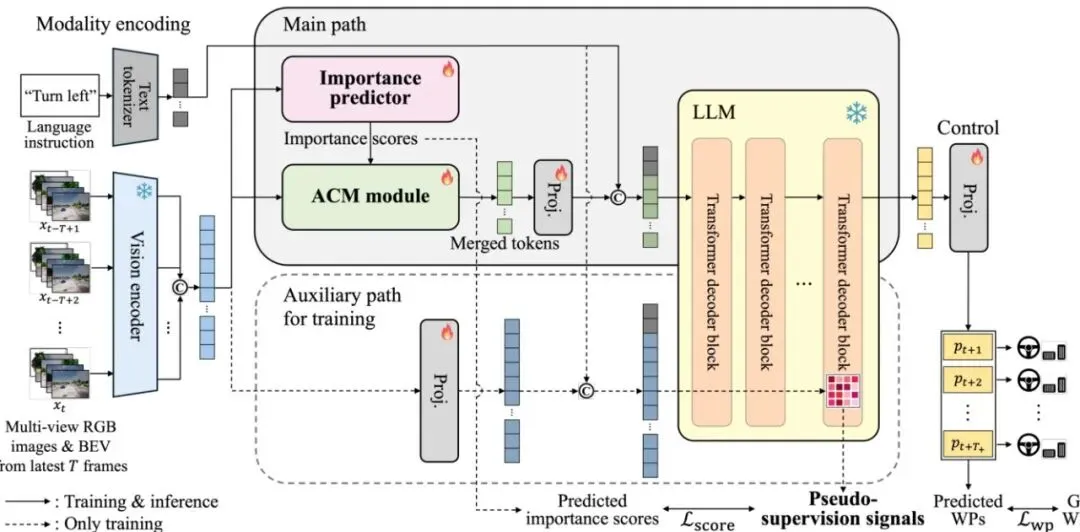
传统的自动驾驶系统像一条“流水线”,感知、预测、规划各司其职。而端到端(End-to-End, E2E)驾驶则更“拟人”,它让一个统一的模型直接从传感器数据(如图像、激光雷达)输出控制指令(如方向盘转角、油门刹车)。这种方法潜力巨大,尤其在处理需要高级语义理解的复杂、意外场景时。为了让车更“懂”人,研究者们引入了多模态大语言模型(Multi-modal Large Language Model, MLLM)。MLLM能够同时处理视觉和语言信息,理解像“绕过前面那辆抛锚的卡车”这样的自然语言指令,从而让人车交互更自然,在突发情况下也能借助人类经验进行决策。然而,麻烦来了。为了让模型有“记忆”,我们需要输入连续多帧的历史画面。每一帧画面经过视觉编码器(如Vision Transformer)后,会被切割成成百上千个视觉令牌(Visual Token)。这些令牌就像拼图的碎片,携带了图像不同区域的信息。图2:SToRM整体架构图。它包含一个主路径(用于推理)和一个辅助路径(仅用于训练)。主路径中,轻量级重要性预测器评估每个视觉令牌的重要性,锚点-上下文合并模块据此压缩令牌,再将压缩后的令牌与大语言模型结合预测控制指令。大语言模型(LLM)的核心——Transformer中的自注意力机制,其计算量会随着输入令牌数量的平方级增长。当几千个视觉令牌和几十个文本令牌一起涌入LLM时,计算开销变得极其庞大,严重拖慢推理速度,这与自动驾驶所需的“实时性”背道而驰。现有的解决方案,比如LMDrive中使用的Q-Former(一种基于可学习查询的Transformer模块),虽然能减少令牌数量,但往往以牺牲驾驶性能为代价。如何在“减肥”和“保持体力”之间找到最佳平衡点,成了关键难题。核心创新:用大模型自己的“注意力”教小模型选令牌
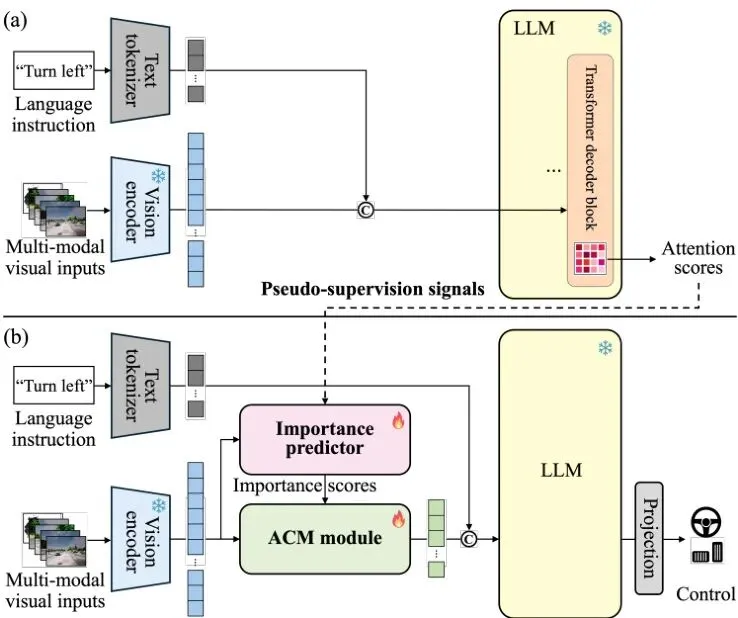 图1:SToRM框架总览。核心思想是利用大模型自身产生的注意力分数作为“伪监督信号”,来训练一个小型的重要性预测器,从而指导视觉令牌的压缩。SToRM的核心思想非常直观且聪明:让知识渊博但行动缓慢的“大模型老师”,来指导一个轻量级的“学生模型”学会抓重点。在训练阶段,SToRM设置了一条“辅助路径”。这条路径不做任何压缩,将所有的视觉令牌和文本令牌原封不动地喂给冻结(不更新参数)的大语言模型(LLM)。当LLM为了理解指令和场景进行“思考”时,它的自注意力机制会产生一个注意力分数矩阵。这个矩阵揭示了在完成最终任务(如预测轨迹)时,每个令牌(包括视觉和文本)对其他所有令牌的“关注程度”。SToRM提取最后一个Transformer解码器块的注意力矩阵,并对每一列(代表一个“键”令牌)取平均。这个平均值就被认为是该令牌的“伪重要性分数”——分数越高,意味着在完成驾驶任务时,所有其他令牌(“查询”令牌)都更关注它,它自然就越重要。同时,在“主路径”上,一个轻量级的重要性预测器(我们后面会详细介绍)会对同样的视觉令牌进行观察,并预测它们各自的重要性分数。训练目标就是让“学生”预测的分数尽可能接近“老师”给出的伪重要性分数。通过这种方式,轻量级预测器就学会了像大模型一样,识别出对驾驶决策至关重要的视觉信息。
图1:SToRM框架总览。核心思想是利用大模型自身产生的注意力分数作为“伪监督信号”,来训练一个小型的重要性预测器,从而指导视觉令牌的压缩。SToRM的核心思想非常直观且聪明:让知识渊博但行动缓慢的“大模型老师”,来指导一个轻量级的“学生模型”学会抓重点。在训练阶段,SToRM设置了一条“辅助路径”。这条路径不做任何压缩,将所有的视觉令牌和文本令牌原封不动地喂给冻结(不更新参数)的大语言模型(LLM)。当LLM为了理解指令和场景进行“思考”时,它的自注意力机制会产生一个注意力分数矩阵。这个矩阵揭示了在完成最终任务(如预测轨迹)时,每个令牌(包括视觉和文本)对其他所有令牌的“关注程度”。SToRM提取最后一个Transformer解码器块的注意力矩阵,并对每一列(代表一个“键”令牌)取平均。这个平均值就被认为是该令牌的“伪重要性分数”——分数越高,意味着在完成驾驶任务时,所有其他令牌(“查询”令牌)都更关注它,它自然就越重要。同时,在“主路径”上,一个轻量级的重要性预测器(我们后面会详细介绍)会对同样的视觉令牌进行观察,并预测它们各自的重要性分数。训练目标就是让“学生”预测的分数尽可能接近“老师”给出的伪重要性分数。通过这种方式,轻量级预测器就学会了像大模型一样,识别出对驾驶决策至关重要的视觉信息。
*表格超出部分左右可以滑动
| 要素 |
内容 |
| 应用场景 |
支持自然语言交互的端到端自动驾驶 |
| 问题建模 |
如何在保持多模态大模型(MLLM)驾驶性能的同时,大幅降低其因处理大量视觉令牌带来的计算开销。 |
| 模型Backbone及选择原因 |
基于LMDrive架构,使用LLaVA或TinyLLaVA作为冻结的LLM骨干。选择它们是因为它们是广泛使用的开源MLLM,便于对比和复现。 |
| 损失函数 |
总损失 L = L_wp + λ * L_score。L_wp是预测路径点与真实值的L1损失;L_score是重要性预测器输出与伪监督信号(来自LLM注意力)的L1损失。 |
| 训练数据集 |
LangAuto基准数据集。 |
| 测试数据集 |
LangAuto基准数据集的测试集(LangAuto-Long, Short, Tiny)。 |
| 训练方法 |
端到端(E2E)训练。同时优化路径点预测和重要性预测两个目标。 |
| 实验效果 |
全面提升。在同等令牌预算下,驾驶性能优于SOTA方法(LMDrive+Q-Former),且能达到与使用全部令牌相当的驾驶性能,同时计算量大幅降低(最高达30倍)。 |
| 方法优势 |
1. 首次提出有监督的令牌压缩框架,利用任务信号指导压缩。
2. 性能损失极小,效率提升显著。
3. 模块化设计,可与其他MLLM结合。 |
| 方法缺点 |
1. 训练时需要“辅助路径”计算伪标签,增加了一次前向传播开销(仅训练阶段)。
2. 锚点数量K需要预设,是超参数。 |
这个“教与学”的范式是SToRM的灵魂。它不仅避免了手工设计启发式规则(如根据令牌相似性来合并)的局限性,而且让令牌压缩过程直接与下游的驾驶任务对齐,这是它能实现“高性能、高效率”的关键。轻量级预测器:滑动窗口巧解时空依赖
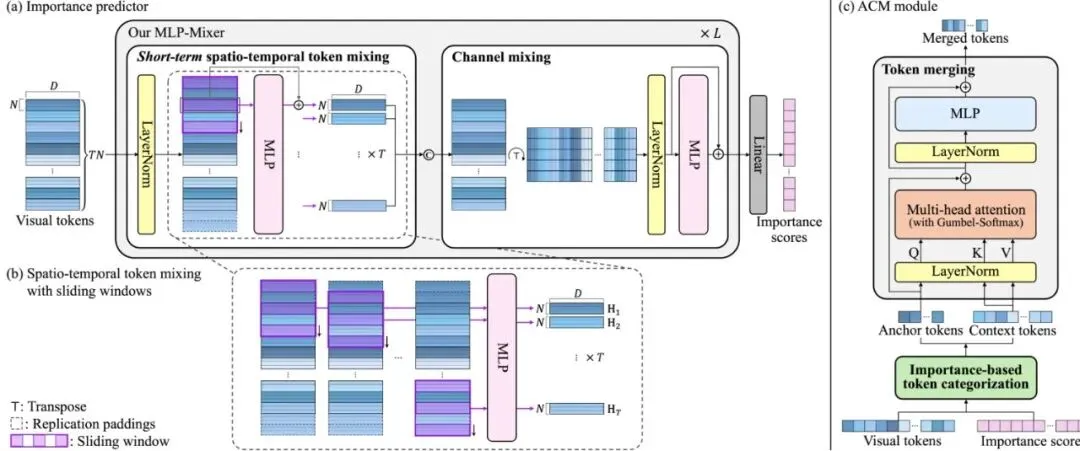 图3:轻量级重要性预测器与锚点-上下文合并模块架构。(a)重要性预测器包含短时空令牌混合、通道混合和分数计算。(b)滑动窗口机制示意图。(c)ACM模块包含基于重要性的令牌分类与合并。光有想法还不够,“学生”模型本身必须非常轻巧,否则就失去了压缩的意义。SToRM设计了一个基于MLP-Mixer架构的轻量级重要性预测器,并做了两大关键改进。自动驾驶场景中,物体的运动是连续的。判断一个令牌(比如代表一辆车的令牌)是否重要,不仅要看它在当前帧的位置,还要看它在前几帧和后几帧的轨迹。一个朴素的方案是把所有帧的所有令牌堆在一起,用一个巨大的MLP去分析它们之间的长距离依赖关系。但这会带来O((T*N)^2)级别的计算复杂度,非常昂贵。SToRM的解决方案很巧妙:使用滑动窗口。对于某一帧的令牌,预测器只关注以其为中心的一个小时间窗口(例如前后各1帧,共3帧)内的所有令牌。这样,模型既能捕捉到短期的运动趋势(时空依赖),又将计算复杂度降低到了O((窗口大小)^2 * (T/步长) * N^2)。论文中的对比也显示,这种设计在几乎不影响效果的前提下,计算量远低于全局处理方案。
图3:轻量级重要性预测器与锚点-上下文合并模块架构。(a)重要性预测器包含短时空令牌混合、通道混合和分数计算。(b)滑动窗口机制示意图。(c)ACM模块包含基于重要性的令牌分类与合并。光有想法还不够,“学生”模型本身必须非常轻巧,否则就失去了压缩的意义。SToRM设计了一个基于MLP-Mixer架构的轻量级重要性预测器,并做了两大关键改进。自动驾驶场景中,物体的运动是连续的。判断一个令牌(比如代表一辆车的令牌)是否重要,不仅要看它在当前帧的位置,还要看它在前几帧和后几帧的轨迹。一个朴素的方案是把所有帧的所有令牌堆在一起,用一个巨大的MLP去分析它们之间的长距离依赖关系。但这会带来O((T*N)^2)级别的计算复杂度,非常昂贵。SToRM的解决方案很巧妙:使用滑动窗口。对于某一帧的令牌,预测器只关注以其为中心的一个小时间窗口(例如前后各1帧,共3帧)内的所有令牌。这样,模型既能捕捉到短期的运动趋势(时空依赖),又将计算复杂度降低到了O((窗口大小)^2 * (T/步长) * N^2)。论文中的对比也显示,这种设计在几乎不影响效果的前提下,计算量远低于全局处理方案。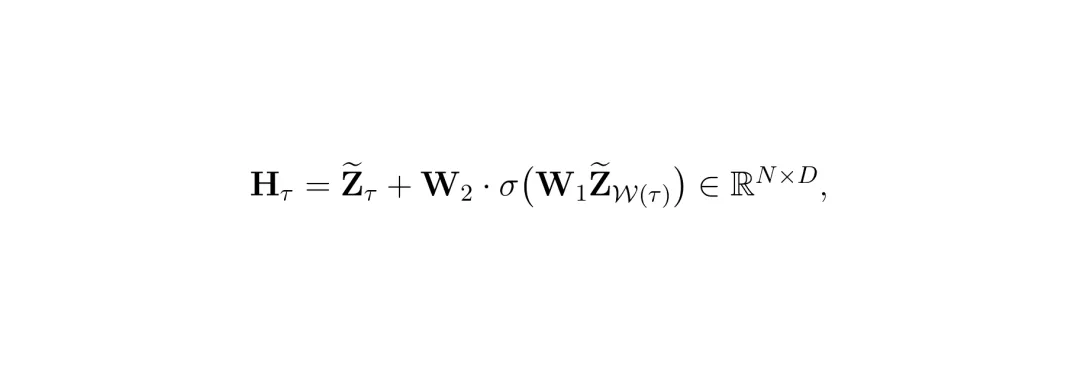 公式:短时空令牌混合操作。H_τ是第τ帧令牌混合后的新表示,它由原始令牌Z~_τ加上一个MLP对滑动窗口内令牌Z~_W(τ)的变换结果构成。这个操作让H_τ蕴含了局部时空信息。经过时空混合后,每个令牌变成了一个D维的特征向量。这D个维度(通道)之间也可能存在重要的关联。SToRM通过一个通道混合模块来捕捉这种“令牌内”的依赖关系。具体做法是:将令牌序列转置,使得每个通道的特征成为一条序列,然后再用MLP对这些通道序列进行混合。这相当于是从另一个视角(特征维度)来理解和增强令牌表示。
公式:短时空令牌混合操作。H_τ是第τ帧令牌混合后的新表示,它由原始令牌Z~_τ加上一个MLP对滑动窗口内令牌Z~_W(τ)的变换结果构成。这个操作让H_τ蕴含了局部时空信息。经过时空混合后,每个令牌变成了一个D维的特征向量。这D个维度(通道)之间也可能存在重要的关联。SToRM通过一个通道混合模块来捕捉这种“令牌内”的依赖关系。具体做法是:将令牌序列转置,使得每个通道的特征成为一条序列,然后再用MLP对这些通道序列进行混合。这相当于是从另一个视角(特征维度)来理解和增强令牌表示。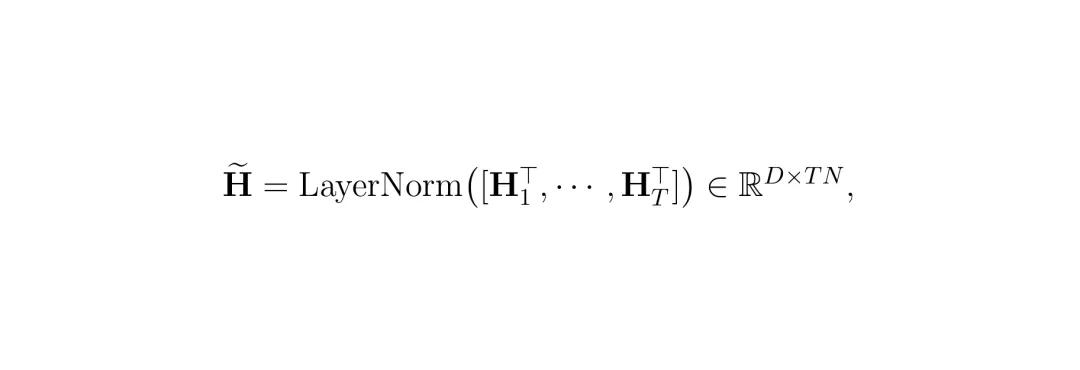 公式:构建通道混合的输入矩阵H~。它将所有帧混合后的令牌表示H_τ转置后拼接,每一行代表一个通道在所有时空位置上的值。
公式:构建通道混合的输入矩阵H~。它将所有帧混合后的令牌表示H_τ转置后拼接,每一行代表一个通道在所有时空位置上的值。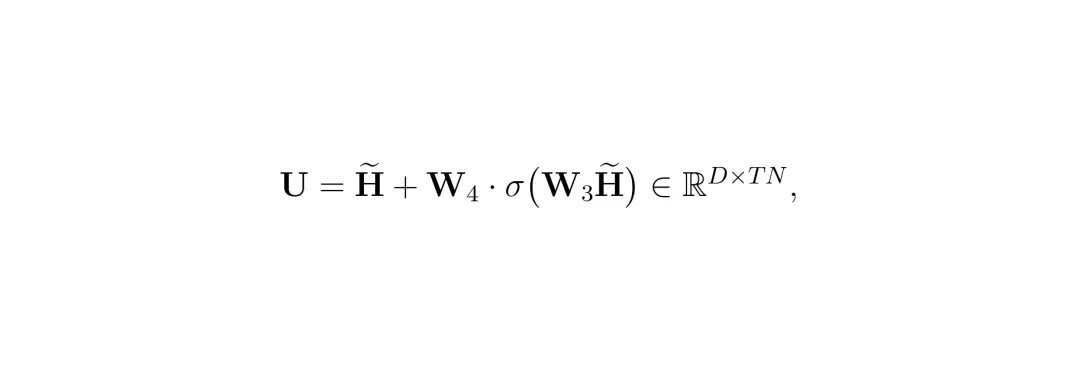 最后,通过一个简单的线性投影层,从增强后的表示U中计算出每个视觉令牌的重要性分数向量s。
最后,通过一个简单的线性投影层,从增强后的表示U中计算出每个视觉令牌的重要性分数向量s。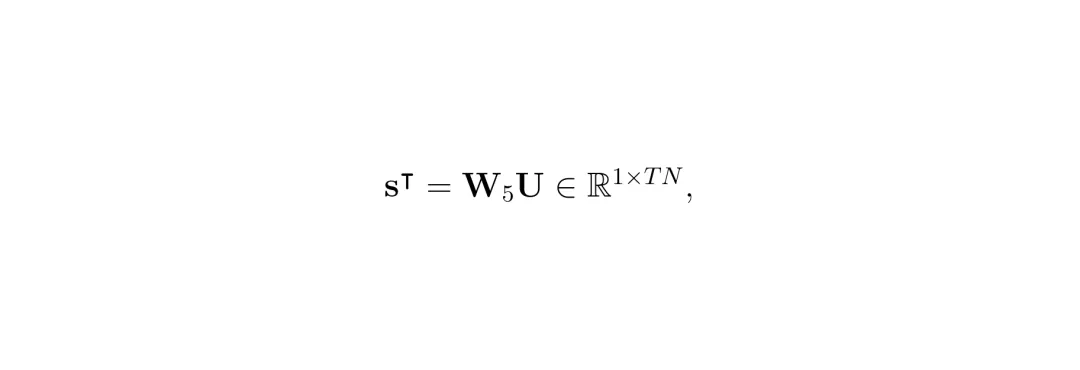 公式:重要性分数计算。W_5是一个1xD的权重向量,将D维特征映射为一个标量分数。
公式:重要性分数计算。W_5是一个1xD的权重向量,将D维特征映射为一个标量分数。锚点-上下文合并:硬分配保留关键信息
拿到了重要性分数,下一步就是“动手术”压缩令牌了。SToRM没有简单地丢弃低分令牌,而是提出了锚点-上下文合并模块,旨在“合并同类项”,最小化信息损失。对于每一帧,根据预测的重要性分数对所有N个视觉令牌进行排序。分数最高的前K个令牌被选为“锚点”,它们代表了该帧中最关键、不可丢弃的信息(如车辆、行人、交通标志)。剩下的N-K个令牌则被归为“上下文”,它们提供了补充的、细节性的信息(如路面纹理、背景建筑物)。接下来,要为每个“上下文”令牌找到一个最相似的“锚点”令牌,并把它的信息合并过去。这听起来很像注意力机制。没错,SToRM在这里使用了交叉注意力,将锚点作为查询(Q),上下文作为键(K)和值(V)。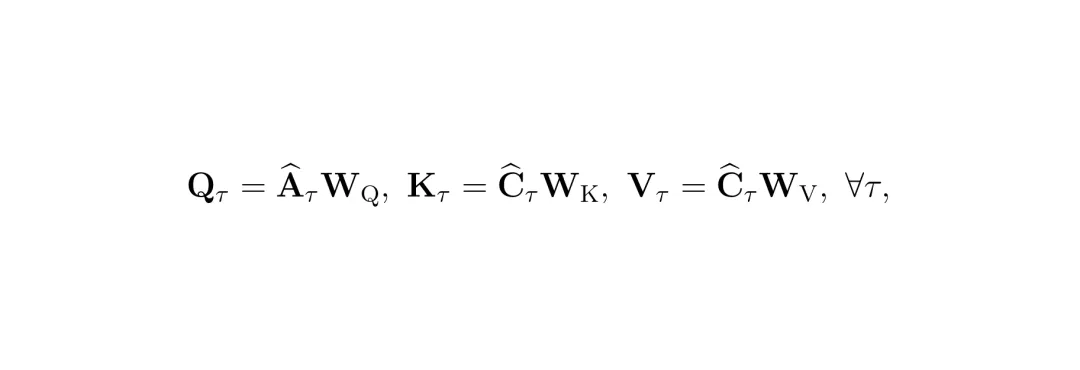 关键创新在于,SToRM希望这种合并是“硬分配”的,即每个上下文令牌只归属于一个锚点,而不是以加权平均的方式模糊地分给多个锚点。这能更好地保留信息的独立性和结构性。为了实现可微分的硬分配,论文采用了Gumbel-Softmax技巧。
关键创新在于,SToRM希望这种合并是“硬分配”的,即每个上下文令牌只归属于一个锚点,而不是以加权平均的方式模糊地分给多个锚点。这能更好地保留信息的独立性和结构性。为了实现可微分的硬分配,论文采用了Gumbel-Softmax技巧。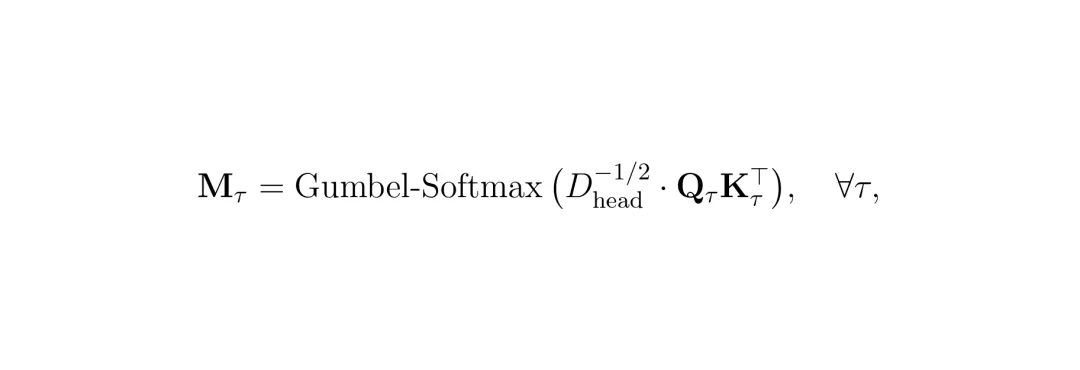 公式:使用Gumbel-Softmax计算分配矩阵M_τ,它近似于一个按列取argmax的one-hot矩阵。得到(近似)硬分配矩阵后,每个锚点令牌通过加权聚合所有分配给它的上下文令牌的信息来更新自己,从而得到一个信息更丰富的“超级锚点”。
公式:使用Gumbel-Softmax计算分配矩阵M_τ,它近似于一个按列取argmax的one-hot矩阵。得到(近似)硬分配矩阵后,每个锚点令牌通过加权聚合所有分配给它的上下文令牌的信息来更新自己,从而得到一个信息更丰富的“超级锚点”。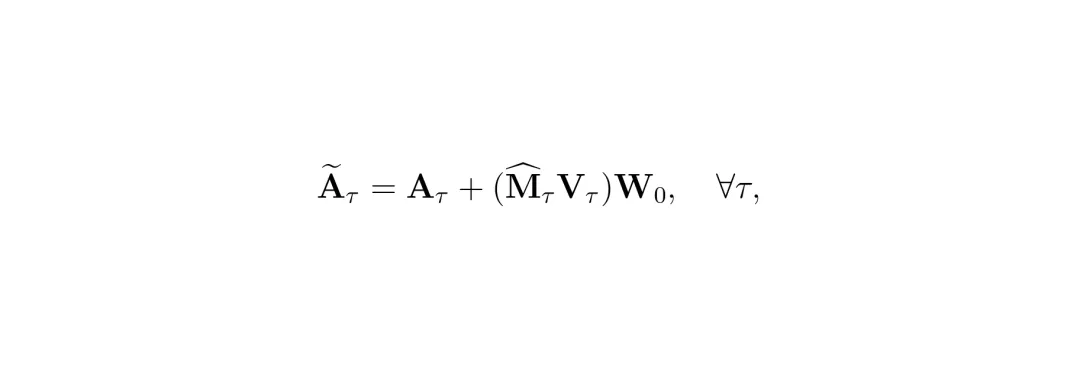 公式:更新锚点表示。M^_τ是经过直通估计(STE)处理的硬分配矩阵,V_τ是上下文的值,W_O是投影矩阵。经过ACM模块,每帧的视觉令牌数量就从N个减少到了K个。这些保留下来的“超级锚点”被送入后续的大语言模型进行推理。整个流程确保了关键信息不丢失,而冗余信息被高效整合。
公式:更新锚点表示。M^_τ是经过直通估计(STE)处理的硬分配矩阵,V_τ是上下文的值,W_O是投影矩阵。经过ACM模块,每帧的视觉令牌数量就从N个减少到了K个。这些保留下来的“超级锚点”被送入后续的大语言模型进行推理。整个流程确保了关键信息不丢失,而冗余信息被高效整合。实验结果:性能媲美全令牌,计算量骤降30倍
理论很美好,实际效果如何?论文在自动驾驶基准数据集LangAuto上进行了全面测试。实验设置非常扎实。首先,对比了三种方案:1) “全令牌”基准(不压缩,性能上限);2) SOTA方法 LMDrive(使用Q-Former压缩);3) 提出的SToRM。并且为了验证泛化性,分别在LLaVA和更小的TinyLLaVA两个LLM骨干上进行实验。评估指标包括衡量驾驶安全性和合规性的驾驶分数,以及关键的计算效率指标(FLOPs)。从结果来看,SToRM的设计理念得到了完美验证。有监督的令牌压缩使得它能够学习到与任务高度相关的重要性判别能力。因此,在将令牌数量压缩到与Q-Former相同水平(例如64个)时,SToRM的驾驶性能显著优于Q-Former,甚至可以达到与使用全部近3000个令牌相近的性能水平。这意味着SToRM几乎筛选出了“全部精华”,丢弃的更多是冗余信息。在效率方面,由于大幅减少了输入LLM的令牌数量,SToRM带来了数量级的计算量下降。轻量级预测器自身增加的计算开销几乎可以忽略不计。消融实验也证实了其各个组件(如滑动窗口设计、通道混合、硬分配的ACM)的有效性。与一系列其他SOTA令牌压缩方法(如Token Merging, LLaVA-PruMerge等)的对比中,SToRM也全面胜出,证明了其框架的优越性。 表1:所提滑动窗口令牌混合与朴素全局混合的计算复杂度对比。所提方法显著降低了计算量。
表1:所提滑动窗口令牌混合与朴素全局混合的计算复杂度对比。所提方法显著降低了计算量。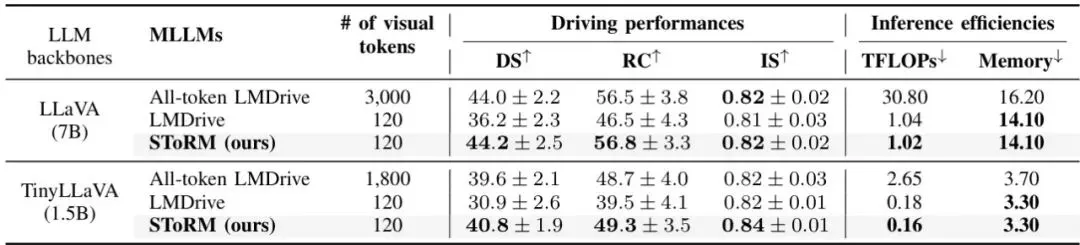 表2:SToRM与SOTA E2E驾驶MLLM在两种不同规模LLM骨干上的对比(LangAuto-Long数据集)。SToRM在使用64个令牌时,性能媲美全令牌(~3000个),且计算量(GFLOPs)大幅降低。↑表示越高越好,↓表示越低越好。
表2:SToRM与SOTA E2E驾驶MLLM在两种不同规模LLM骨干上的对比(LangAuto-Long数据集)。SToRM在使用64个令牌时,性能媲美全令牌(~3000个),且计算量(GFLOPs)大幅降低。↑表示越高越好,↓表示越低越好。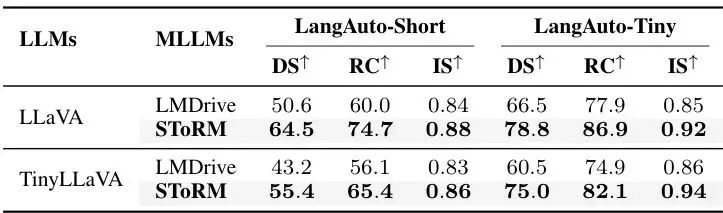 表3:在LangAuto-Short和LangAuto-Tiny数据集上的对比结果,结论一致。
表3:在LangAuto-Short和LangAuto-Tiny数据集上的对比结果,结论一致。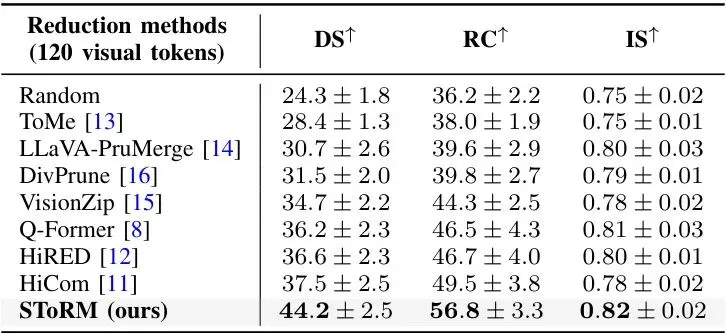 表4:与多种先进令牌压缩方法在E2E驾驶任务上的对比。SToRM在驾驶分数和效率上均取得最佳平衡。
表4:与多种先进令牌压缩方法在E2E驾驶任务上的对比。SToRM在驾驶分数和效率上均取得最佳平衡。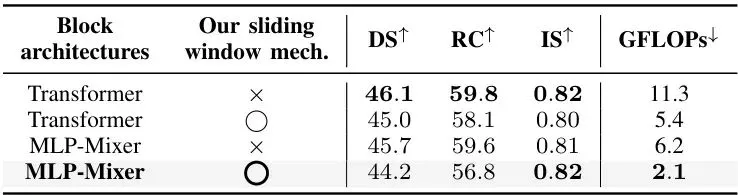 表5:不同重要性预测器设计的消融实验。证明了滑动窗口和通道混合模块的有效性。
表5:不同重要性预测器设计的消融实验。证明了滑动窗口和通道混合模块的有效性。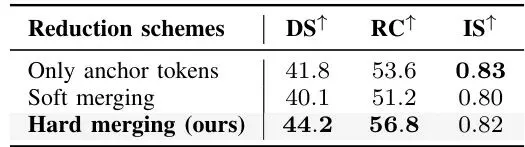 表6:不同令牌压缩方案的消融实验。证明了锚点-上下文合并(ACM)模块优于简单的令牌剪枝或软合并。这些结果清晰地表明,SToRM成功实现了“鱼与熊掌兼得”:在将计算量削减至原来的约1/30的同时,守住了驾驶性能的底线,甚至有所超越。
表6:不同令牌压缩方案的消融实验。证明了锚点-上下文合并(ACM)模块优于简单的令牌剪枝或软合并。这些结果清晰地表明,SToRM成功实现了“鱼与熊掌兼得”:在将计算量削减至原来的约1/30的同时,守住了驾驶性能的底线,甚至有所超越。
未来展望:迈向实时高效多模态驾驶
SToRM为高效多模态端到端自动驾驶打开了一扇新的大门。其“用大模型指导小模型进行动态信息筛选”的核心思想,具有很强的通用性和启发性。未来的工作可以从几个方面展开:一是将框架扩展到更多模态,如音频(车内语音指令)、雷达等;二是探索更自适应的方法,例如让锚点数量K能够根据场景复杂度动态调整;三是研究如何将该框架与模型量化、蒸馏等技术结合,进一步推动在真实车载芯片上的部署落地。随着类似SToRM这样的高效化技术不断成熟,那个既能听懂我们唠叨、又能安全敏捷驾驶的“AI老司机”,或许正加速驶向现实。龙迷三问
Q1:这篇论文到底解决了自动驾驶中的什么问题?它解决了在端到端自动驾驶中引入多模态大语言模型(MLLM)后带来的计算效率瓶颈问题。MLLM需要处理海量的视觉令牌,导致推理速度慢,无法满足实时性要求。本文提出了SToRM框架,通过有监督的令牌压缩,在几乎不损失驾驶性能的前提下,大幅降低了计算量,让高性能的交互式自动驾驶更接近实际应用。
Q2:文中的MLLM和Q-Former具体是指什么?MLLM全称Multi-modal Large Language Model,即多模态大语言模型。它能够理解和生成文本,同时处理图像、语音等其他模态的信息,是实现自然语言与自动驾驶系统交互的基础。Q-Former(Querying Transformer)是一种用于压缩视觉令牌的模块,它通过一组可学习的“查询”向量与视觉令牌进行交互,只将这些查询向量输入LLM,从而减少令牌数量。它是之前SOTA方法LMDrive中使用的技术,但性能有损失。
Q3:“锚点-上下文合并”具体是怎么合并的?能举个简单例子吗?假设一帧图像有100个令牌,我们选重要性最高的20个作为“锚点”(比如分别代表“汽车A”、“行人B”、“红灯C”),剩下80个是“上下文”(比如“天空”、“路面”、“树叶”)。对于每个上下文令牌(如“路面纹理”),计算它与所有20个锚点的相似度,发现它与“汽车A”的锚点最相似(因为汽车压在路面上)。于是,我们就把“路面纹理”这个上下文令牌的信息,“硬分配”合并到“汽车A”这个锚点里。更新后的“汽车A”锚点就既包含了汽车本身的信息,也包含了它所接触的路面信息。最终,我们只用这20个融合了周围上下文的“超级锚点”来代表这一帧。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~龙哥点评
论文创新性分数:★★★★☆
将大模型的注意力机制作为监督信号来训练轻量级令牌筛选器,这个“知识蒸馏”的变体思路清晰且新颖。结合面向任务的硬分配合并机制,构成了一个完整、有特色的框架。实验合理度:★★★★★
实验设计非常全面。不仅与SOTA方法和全令牌基准对比,还在不同规模LLM、不同数据集上验证,并与众多主流令牌压缩方法进行了横向比较。消融实验也完整地验证了每个核心组件的必要性。结论可靠。学术研究价值:★★★★☆
为多模态大模型的高效化提供了一个行之有效的新范式(有监督的动态令牌压缩)。其思想可迁移到其他计算受限的多模态任务中,如机器人交互、具身智能等,具有较高的启发价值。稳定性:★★★☆☆
在基准数据集上表现稳定。但自动驾驶场景极其复杂,该方法对重要性预测器的准确性依赖较高。在极端恶劣天气、严重遮挡等导致视觉特征模糊的情况下,预测器可能失效,需要进一步在更严苛的 corner case 上测试。适应性以及泛化能力:★★★★☆
框架本身是模态无关和模型无关的,可以适配不同的视觉编码器和LLM骨干。论文也在不同规模LLM上验证了有效性。但针对全新的传感器配置或任务形式,可能需要调整或重新训练。硬件需求及成本:★★★★☆
推理阶段成本极低,轻量级预测器增加的开销很小,主要收益来自于LLM计算量的大幅减少,有利于实时部署。训练阶段因为需要“辅助路径”进行前向传播来计算伪标签,所以成本相对较高(约是两倍模型前向计算)。复现难度:★★★☆☆
论文方法描述清晰,但涉及多个定制模块(重要性预测器、ACM)。虽然基于现有LMDrive,但完整复现仍需一定的工程能力。若能开源代码,难度将大大降低。产品化成熟度:★★★☆☆
在特定数据集和仿真环境中展示了巨大的潜力,是迈向产品化的重要一步。但要应用于真实车辆,必须通过海量实车数据训练和验证,尤其是在安全攸关的长尾场景中证明其稳定性。目前处于“ promising research, needs further validation ”阶段。可能的问题:论文实验主要基于仿真环境(LangAuto)。真实世界的视觉噪声、传感器故障、标注噪声等因素可能影响重要性预测的可靠性。此外,“锚点”数量K是固定的超参数,未能实现完全自适应的压缩比,在简单和复杂场景下可能不是最优。
[1] Seo Hyun Kim, Jin Bok Park, Do Yeon Koo, Ho Gun Park, Il Yong Chun. SToRM: Supervised Token Reduction for Multi-modal LLMs toward efficient end-to-end autonomous driving. arXiv preprint arXiv:2602.11656, 2026. (本论文)[3] Peng, Y. et al. LMDrive: A Benchmark for Language-Guided End-to-End Driving. In Proc. IEEE/CVF CVPR, 2024. (文中作为SOTA基线及数据源的论文)[8] Li, J. et al. BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models. In Proc. ICML, 2023. (提出了Q-Former模块)*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文",查看更多原论文细节哦!

🚗 想让你的AI模型也学会“瘦身”绝技,跑得更快更稳吗?快来和龙哥及一群自动驾驶、大模型高手们一起切磋!
欢迎加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 自动驾驶+北京+清华+龙哥),根据格式备注,可更快被通过且邀请进群。



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
